























 7,863
7,863
On May 7, 2019, the search engine giant Google announced that Googlebot switches to a new engine, which will now work based on the latest version of Chromium (popular Chrome browser was made on its basis).
The updated crawler now supports more than 1,000 new features, but the most interesting innovation for us is the feature to handle web pages in the same way as modern browsers do, including rendering JavaScript and JavaScript frameworks.
Thus, it turns out that if a year ago, when scanning a website, Google bot loaded only the source code of pages (an analogue of what you can see in the browser by clicking Ctrl-U), now it has a full-fledged tool similar to the classic browser that crawls both the source code and also CSS styles and Javascripts, thereby fully renders the page and sees almost everything that an ordinary user sees on the webpages.
So how do visits of a new crawler reflect on pageview statistics?
Most recently, adding a new article for Google indexing, I noticed the strange behavior of the article view counters.
Note:
My counter of article views works according to the classical principle: each time you visit a page, the counter is incremented by one. At the same time, upon repeated visits to the page, there is no comparison by IP or by cookie (no verification of whether this user has visited the page or not yet). Conventionally: if you press F5 on the page five times (forcing to refresh the page), the number of views will increase by 5 times.
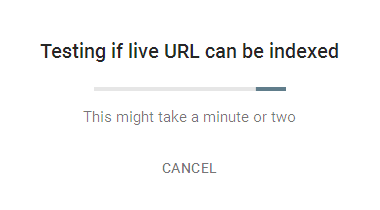
So, after several corrections to the article and control of changes on the website, the counter showed 16 views. For quick indexing, as usually, I added the URL to priority reindexing via the Google Webmaster panel.
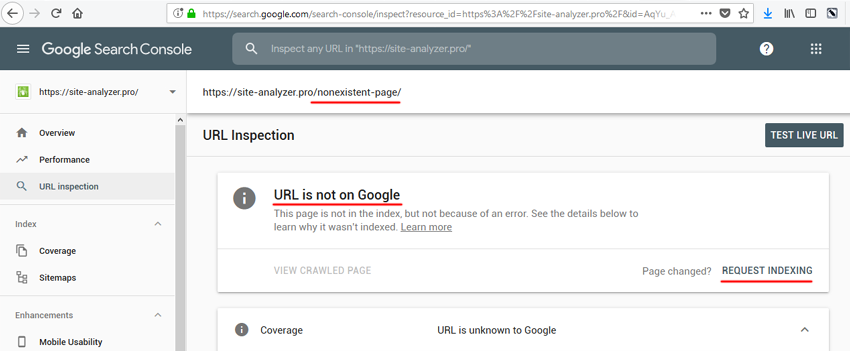
Then I changed something else in the article, once again updated the page and noticed that the counter value became equal to 21 (16 + 1 my update + 4)!
It is strange...
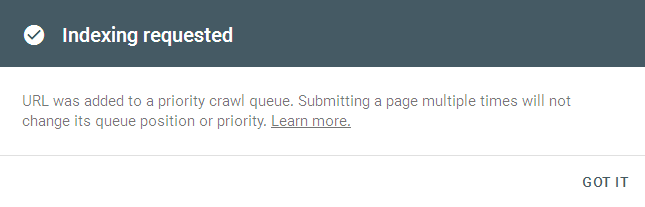
That is, even if the page is already in the index, more than 4 people except me could not visit it in a couple of minutes. One option remains – Googlebot and its new principle of rendering pages. To test the hypothesis, I opened phpMyAdmin, opened the table with counters, found the article, set the views counter at 10. Then I copied the URL to the clipboard and repeated the procedure of priority page indexing in the Google Webmaster panel. After 10 seconds, the counter value became 14!
That is, every time Google crawler visits the page, it passes 4 times to re-index it, thereby driving up the website counters (this doesn’t affect the visit statistics in Google Analytics ).
As far as I know, previously Google bot made 2 passes for re-indexing, and now from 4 to 5 passes (sometimes I saw a counter increase by 5 views).
Passing sequence:
- No matter the page is indexed or not, indexing usually takes 4 passes:
- first, a request is sent to check the page indexing to its database (does not physically go to the webpage)
- next, two passes are done after confirming that the page has been sent for reindexing
- and after sending the request for indexing, almost immediately 2 more
Example of Google bot visiting log in access.log to re-index a single page:
- 66.249.75.72 - - [02/Jul/2019:23:00:56 +0300] "GET /articles/googlebot-chromium-page-rendering/ HTTP/1.0" 200 8867 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
- 66.249.75.74 - - [02/Jul/2019:23:00:57 +0300] "GET /articles/googlebot-chromium-page-rendering/ HTTP/1.0" 200 8867 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
- 66.249.75.70 - - [02/Jul/2019:23:01:48 +0300] "GET /articles/googlebot-chromium-page-rendering/ HTTP/1.0" 200 10340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
- 66.249.75.70 - - [02/Jul/2019:23:01:49 +0300] "GET /articles/googlebot-chromium-page-rendering/ HTTP/1.0" 200 8867 "-" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
- 66.249.69.92 - - [02/Jul/2019:23:02:59 +0300] "GET /articles/googlebot-chromium-page-rendering/ HTTP/1.0" 200 10340 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
As it turned out, Google has not changed the user-agent for Googlebot and still uses the old version, which mentions Chrome 41. At the same time, the crawler is actually based on Chrome 74, as the company says (they plan to update the user-agent in the future).
We also see "Nexus 5X" in the new user-agent logs, although previously it mentioned only "Android 9.0.0 Pixel 3 XL"...
Thus, with frequent re-indexing of articles, for one such article, all such counters can decently distort the number of actual visits.
For example, when Googlebot re-indexes one of the articles once a week, we get 4 (passes) * 4 (weeks) * 12 (months) = 192 "fake" article views per year. This will be a quite significant enough error for articles with several hundred views. For articles with 5,000 views a year or more, this will not be such a significant deviation.
Such a feature of Googlebot should be taken into account when analyzing statistics of views of your information materials.
Whether search bots in case of such principle of counting statistics of views can be ignored?
Yes. There are several options, I mentioned two of them in the beginning of the article:
- Comparison by cookies (labor intensive).
- Comparison by IP address (labor intensive).
- Search for bot signs by user-agent (the easiest option).
The first two options are hard to implement, so we’ll go straight to the third point, since its implementation is quite simple: we just have to look for bot signs using the user-agent, and if it is a bot, then just don’t increase the counter. In PHP, it looks like this:

After introducing such code on the website, the counter stopped increasing when the Google bots reindex the page, but it still updates when regular users visit and update the page.
Thus, we get a simple option for Google bot identification when re-indexing pages that have simple visit counters (advanced statistics systems have built-in functions that do not take into account visits of search robots to the website, but they work according to the same principle).
And what about the counters in Javascript?
Let's check how the new Google rendering renders javascript counters.
To do this, we will create an arbitrary page, which will no longer contain the counter loading in an explicit form, but will load it with Javascript, which in turn will pull the PHP script, which will interact with our database, replacing the <div> with the counter value derived from the base by loading via Ajax. The source code of the page looks like this:

Link to page: test.php
This time, after sending the page for reindexing, the counter did not move to a single transition, which means that currently javascripts are still not fully rendered.
The sequence of indexing pages, as does Googlebot
- visiting a page by a Googlebot and checking indexing rules meta "robots"
- checking indexing rules in "robots.txt"
- page indexation if both rules allows indexing

Author Andrey Simagin
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Other articles:



















