























 8,494
8,4941. Giant indexes, dirty crawls, mis-managed indexing
This impacts a HUGE volume of sites – and, it's mind numbing that these SEO issues persist when so many of these sites have BEEN managed by SEOs – where the client wasn't advised of the issues that unmanaged indexes can cause.
Simple fact – yes, Google can better understand parameter paths / parameter relationships (that's why they got rid of the ability in legacy webmaster tools to tell them what parameters did what) – now, Google will understand – parameters change page content.
But – when you let parameters work in infinite combinations – this creates index bloat (and don't think directives alone can entirely stop this).
Let me explain
If you have a HUGE index – Google is, at some point going to just stop indexing URL combinations – index bloat will BLEED LINK EQUITY across pages – you create dilution.
Large NON VALUE indexes are bad for SEO – and, now with Googlebot being FAR MORE selective about what is indexed – there has never been a better time to PROPERLY manage parameters.
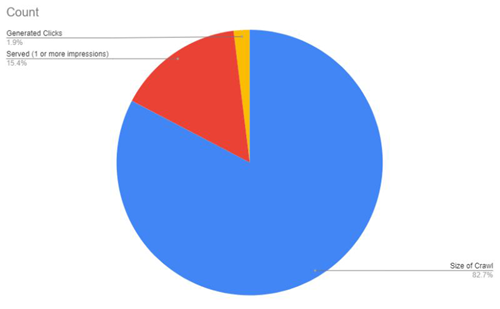
In the photo of this post is a site that I am auditing – I dumped out a full crawl, I then dumped out the GSC data from SEO stack so I could see the true scale of SERVED URLs.
I then – from the list of URLs that had been served (1 or more impressions) sized up how many of those URLs generated clicks.
Now – this is based on an "at the time" analysis. The index (and non indexed) URLs continue to grow – but, indexed URLs is dropping off fast whilst CCNI grows.
I went further than this – here is what I did
👉 Crawled the website and split the crawl into STATIC URLs / DYNAMIC URLs.
👉 I then used SEO stack to export ALL GSC data (API based – no limitation on URL/query counts).
👉 I then compared the DYNAMIC URL size against filtered GSC data where the URL contained ? – this is how I get INDEX SIZE vs URLs that served 1 or more impressions vs URLs that generated 1 or more clicks.
👉 I then compared GSC click data for STATIC URLs vs DYNAMIC URLs.
It looks like this
Dynamic URLs:
- 50K Clicks, 6m Impressions
- 188,600 URLs crawled
- 35,047 URLs served 1 or more impressions
- 4430 URLs generated 1 or more clicks
- 153,553 URLs not indexed
Static URLs:
- 570K Clicks, 24m impressions
- 2039 URLs crawled
- 1869 URLs served 1 or more impressions
- 1365 URLs generated 1 or more clicks
- 170 URLs not indexed
The amount of index bloat is huge.
So – what do you do here?
Look at the DYNAMIC URLs that generated clicks – then look at creating static routes for any single/combination URL paths.
Create static routes that are accessible via text links.
Apply Noindex, Follow to DYNAMIC ROUTES after STATIC ROUTES are built and accessible.
Canonicals will not save you. Sure, Google will recognise a chunk of canonicals – but, ultimately you'll end up with a mish mash index.
When filtering allows for various combination paths where the content changes – where content changes, the canonical can be ignored.
2. SEO Tip – Indexing Cleanup
With so many churning out content and neglecting pre-existing index cleanups, I thought I'd drop some tips/videos around index scrubbing.
Today – we talk about PAGE WITH REDIRECT in search console page indexing.
Why you would do this?
Because it goes towards clearing up your websites index – which is generally beneficial for organic performance.
Does it take long to do?
No, you can do this in minutes.
How do you do it?
👉 Export your page with redirect data.
👉 Run a HTTP status code check to validate (google often has lag, lists URLs with incorrect status codes etc).
👉 Get external referring domain counts to URLs classed as being redirected.
👉 Get traffic data for these URLs from GA > Behaviour > Site content – you can apply custom segments i.e. social to find traffic going to legacy URLs that redirect (this way you don't cull traffic that's a through route from legacy social content etc.).
👉 Get internal link counts to see if the redirects persist because of internal links.
👉 Apply a filter to all of this data.
👉 Duplicate the master sheet, title a tab for each check i.e. 301s with referring domains, 301s without referring domains.
You can then sub filter to find redirects to cull i.e.
URLs where there are no referring domains, no internal links, no session data – the redirects can be removed from server level (or however they are applied).
You can also address persistent redirects that are based on internal links (cleaning up internal links to point post redirect as opposed to pre-redirect).
Cleaning up your index is key.

Author Daniel Foley Carter
In the SEO industry since 1998/1999. Extensive experience working with medium & large global brands on their SEO. Key services I supply to brands looking to scale, grow & convert include professional / enterpri... →
Other articles:



















