























 9,627
9,627Checking web pages for duplicate content is one of the most important steps in the technical audit of a website. The more duplicate pages you have the worse the SEO performance of your web resource. You have to get rid of the repeated content to optimize your crawl budget and improve the search engine ranking. If you want your website to prosper, you must minimize the number of duplicate pages.

Plenty of plagiarism checkers online allow checking the text uniqueness within one web page. However, there are not that many tools to check multiple URLs for duplicate content at once. It does not mean the problem less important, though. Your site rankings may suffer severely because of that!
Common problems associated with duplicate content
1. The same content appears at more than one web address.
Usually, this is a page with parameters and a SEF URL (search engine-friendly URL) of the same page.
- Example:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
This is a fairly common problem. It happens when webmasters forget to set up 301 redirects from pages with parameters to SEF URLs.
This problem can be easily solved with any web crawler. It can compare all the pages of the site and identify two URLs with the same hash codes (MD5). As soon as it happens, you will only need to set up a proper 301 redirect to a SEF URL.
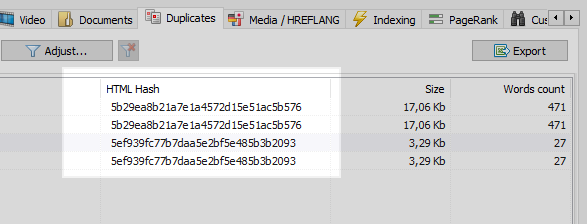
However, at times duplicate content might cause a whole lot more problems.
2. Near-duplicate content.
Pages with serious amounts of overlapping data are called "near-duplicate content" or "common content".
Example 1
A year ago, a copywriter posted congratulations on International Women's Day in the news section of the online store. He wrote a 500-symbol post about the 15% discount.
This year, the content manager simply reused that post instead of writing a new one from scratch. He only changed the discount from 15% to 12% and added extra 50 symbols to the congratulations message.
In the end, the website has two near-duplicate pages that are 90% identical. Both of them need to be rewritten to improve SEO.
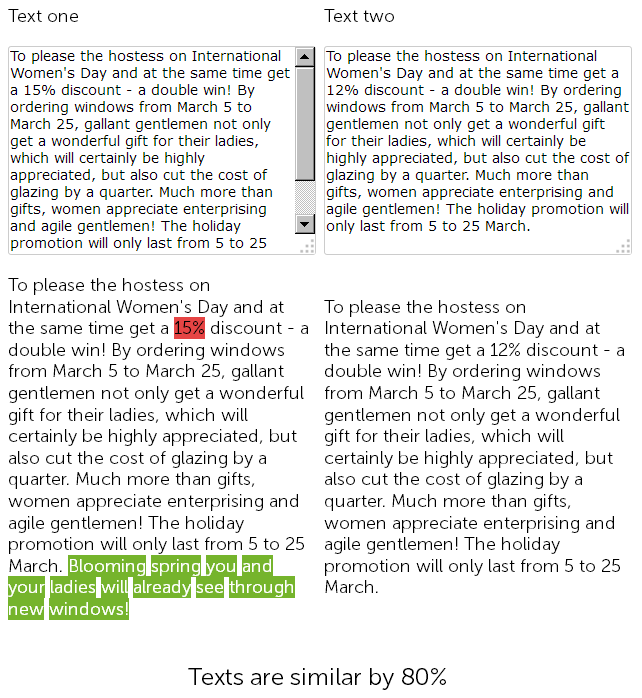
Even though these pages are 90% identical, technical audit tools will consider them different since their SEF URLs will have different checksums.
As a result, it is hard to say which one of the two web pages will rank better.
However, news reports get outdated very quickly. Let us take a look at a far more interesting example.
Example 2
Let’s say you have a website or a blog about food (or any other hobby that interests you).
Sooner or later, you will have over 100 posts in your blog. One day, you will write an article only to find out that you have already covered the topic three years ago. It could happen even if you look through the list of the existing blog posts.
Some of the older pages in your blog might have very similar content. If some of your posts are 70% identical, it will definitely affect your site’s rankings negatively.
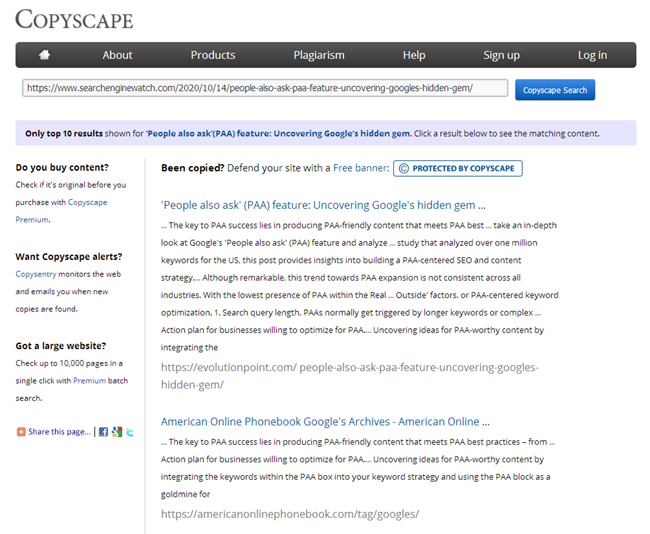
Obviously, every copywriter should use plagiarism checkers to analyze their articles. At the same time, every webmaster is also obliged to check the uniqueness of new content prior to posting it on the website.
However, what do you do when you need to promote a website and quickly check all of its web pages for duplicate content? Maybe, your blog features a bunch of closely similar articles. They still might be damaging your site’s SEO performance even if posted years ago. Obviously, you would waste a ton of time by checking the myriads of pages manually one by one.
BatchUniqueChecker
That is why we created BatchUniqueChecker – a tool designed to bulk check numerous pages for uniqueness.
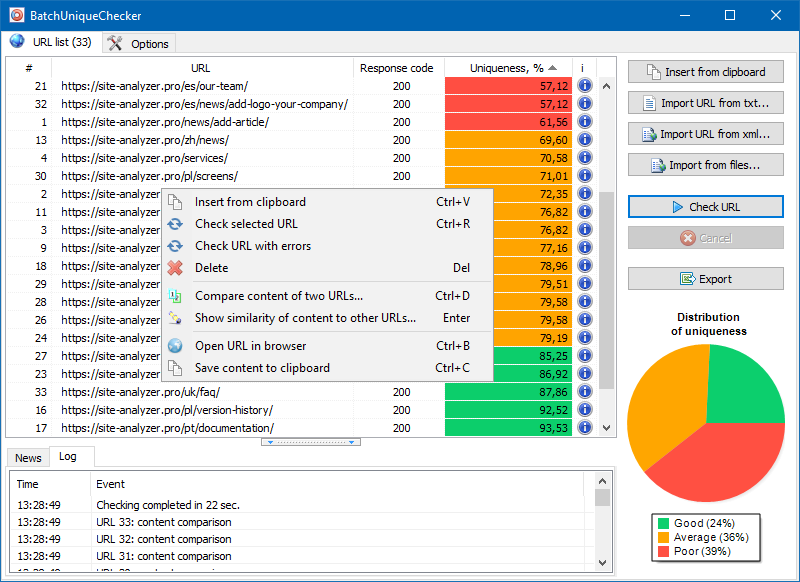
Here is how BatchUniqueChecker works: the tool downloads the contents of a preselected URL list gets PlainText of each page (nothing but the text within HTML paragraphs), and then uses the Shingle algorithm to compare them with one another.
Thus, using shingles of texts, the tool determines the uniqueness of each page. It can be used to find duplicate pages with the text content uniqueness of 0%, as well as partial duplicates with varying degrees of text content uniqueness.
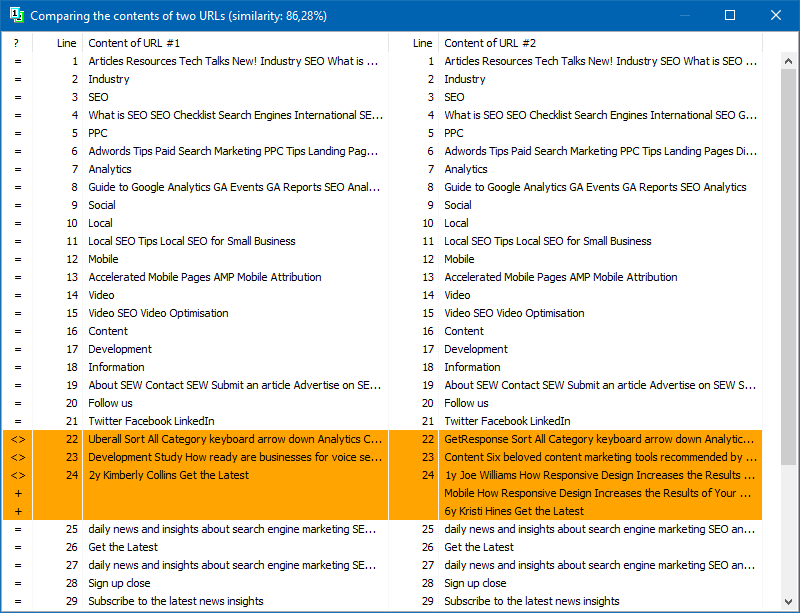
In the program settings, you can manually set the shingle size. Shingles are overlapped sentences of the text, consisting of a fixed length of words. They are superimposed on one another. We recommend setting the value to 4. If you are checking large amounts of text, set it to 5 and above. Set the shingle size 3 or 4 to analyze small amounts of text.
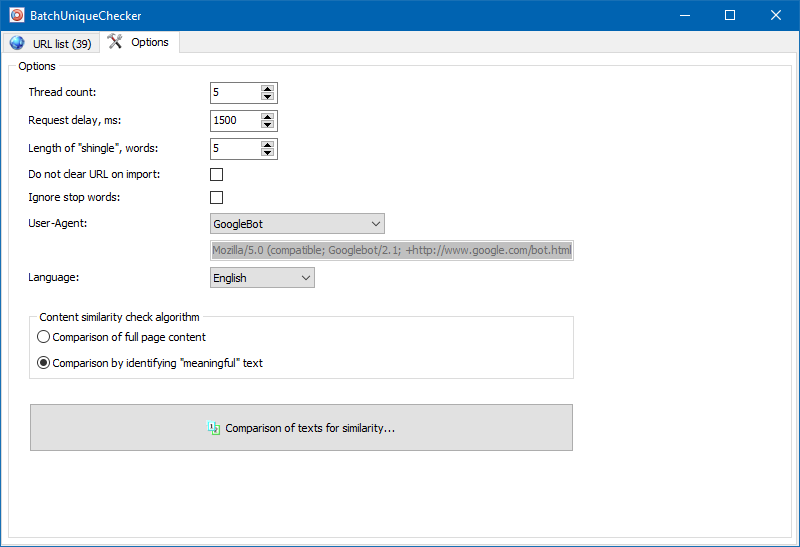
Meaningful texts
In addition to full-text content comparison, the program has a smart algorithm used to detect the so-called "meaningful" texts.
In other words, it takes certain portions of content from the HTML code of a page, specifically the text within the tags H1-H6, P, PRE, and LI. This allows discarding the "insignificant" content such as the text from the site navigation menu, text from the footer, or side menu.
As a result of these manipulations, you will get only the "meaningful" page content, which, when compared, will show more accurate uniqueness results with other pages.
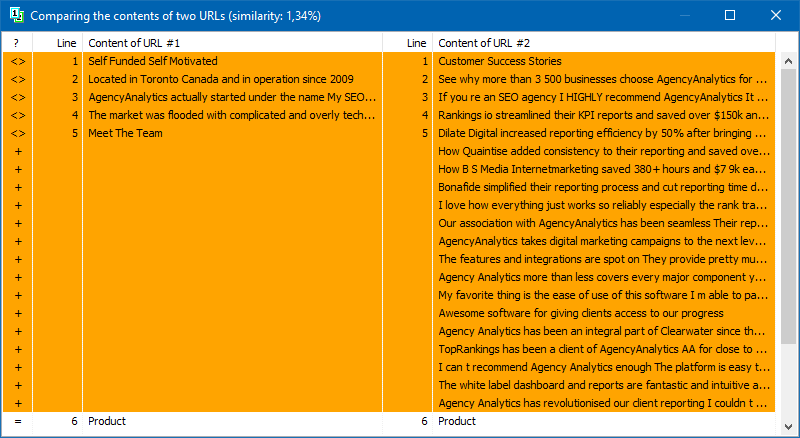
The URL list for the analysis can be added in several ways: paste from the clipboard, load from a text file, or import from Sitemap.xml from your computer disk.
The program is multithreaded, so you can check hundreds of URLs or even more within several minutes. You would have to waste your whole day checking web pages for duplicate content yourself!
Thus, you get a simple tool for quick content uniqueness checks of multiple URLs, which can be activated even from removable storage.
BatchUniqueChecker is available free of charge. It only takes 4 Mb and does not require installation.
All you need to do in order to use it is to download the distributive and check the list of URLs, which can be imported from SiteAnalyzer, a free tool for technical audit.
The BatchUniqueChecker software is implemented in SiteAnalyzer as a separate module and will not be further developed in its current form. Read more...
Other articles:



















