























 4,096
4,096In this article, we made a selection of several materials from the popular foreign SEO consultant Daniel Foley Carter on the correctness of using the Canonical tag, breaking the most popular SEO myths, and outlining his thoughts on working with page quality optimization (Page Experience).

👋 Do not rely on canonical tags (self referencing) 👋
Canonical tags are a DIRECTIVE – instructional, Google does not arbritarily follow URL preference – that's why Google can chose another canonical path over the one it finds.
"But Daniel, what's the point of a canonical?"
👉 Canonicals were intended as a solution for preventing things such as duplicate content as a LAST RESORT – basically, the directive was introduced so that websites with heavy structural limitations i.e. CMS level limitations had an alternate solution.
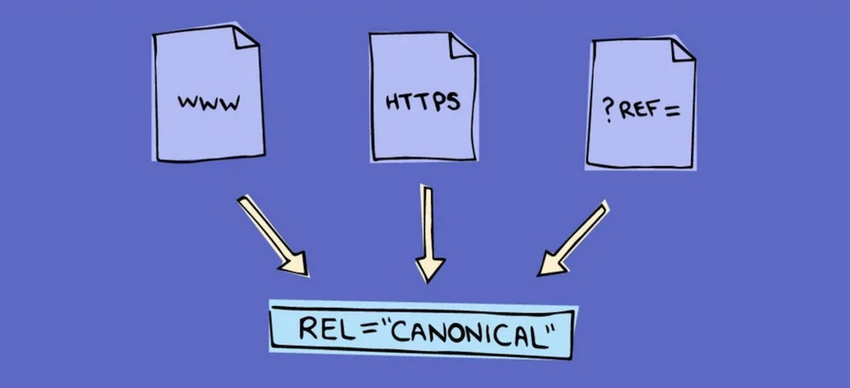
Self referencing canonical tags are fine to a degree – but, you should still ensure that:
👉 Your website ENFORCES consistent paths i.e. trailing slash vs non trailing slash.
👉 You have consistent paths for HTTPS / NON WWW / WWW – depending on what configuration your website uses.
👉 Your website does not return HTTP 200 for variant URLS i.e. mywebsite.com/hello and mywebsite.com/hello/ – in this scenario 2 of the same pages exist but are indepent with a trailing slash – therefore a canonical fall back would be applied.
👉 Do NOT canonicalise pagination series to root pagination – if the page content is different do not canonicalise one URL to another.
👉 Do NOT rely on canonical tags for dynamic URL paths – if the dynamic URL path changes the content – then the canonical tag is attributing pages with different content to one another – instead, use robots.txt to control parameter indexing (use static paths).
Look in your search console > page indexing data now to see if you can see:
❌Duplicate, Google Chose Different Canonical than User.
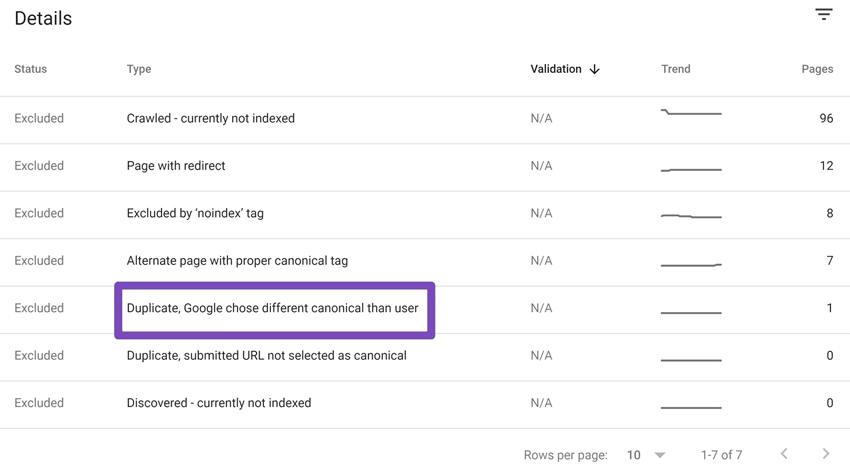
⚠ This means that Google has ignored the canonical directive and chosen something else.
⚠ You should also try to minimise where possible:
❌ Alternate page with proper canonical tag.
Whilst not generally a massive issue – it means Google is crawling content that it doesn't really need to – indexing control is ideal here to reduce the volume of URLS being crawled that are effectively canonical child paths.
👋 Breaking SEO Myths 👋

❓ We own multiple domains and would like to consolidate them – is there any benefit?
⚠ This is VERY conditional. Consolidating numerous domains to aggregate link equity is risky in that you'll consolidate something of potential value but not see the benefit from it – therefore the risk is WASTING equity. Combining numerous domains – Google will obviously follow redirections – the consolidation of links from 1-2 domains (if there is some affinity) is generally beneficial – however, consolidating numerous domains is likely to lead to Google ignoring any additional link weight (I have tested this countless times over the years).
☢️ BS: Consolidating lots of domains will significantly strengthen our domain.
⚠ Yes in Ahrefs maybe, but the reality is – Google will treat everything discretionary – the combination of lots of domains is not "normal behaviour" and whilst there may be rare exceptions – the aggregated benefits will fizzle out where there were better opportunities to pass link equity.
❓ We found that we have lots of links from sites that are on a "blacklist" – will these harm us?
⚠ First of all, there is no Google link blacklist – any tools that claim to show domains blacklisted will likely be based on Semrush / Ahrefs API data where they look for sites with tanked traffic metrics – these links won't generally harm you – they just won't add any benefit and therefore aren't worth wasting money on.
☢️ BS: Links from blacklisted sites will land you a Google penalty.
⚠ Maybe 10 years ago you could of been impacted by third party shoddy links – now you'll see no benefit in most instances – although Google can still acknowledge even sites that appear to have tanked (traffic projection wise) – this is because not all traffic projections are correct.
❓ We're about to launch a new website – should we wait until we begin link building.
⚠ No, building domain trust is a time consuming process – therefore you should begin at the earliest opportunity rather than waiting. Link equity is passed irrespective of where the domain is as long as there is a holding page. Pre-existing equity will help speed things up at site deployment.
☢️ BS: You should wait until you've launched your website before getting links.
👋 Me again with some points on PAGE EXPERIENCE 👋
Inspired by numerous «SEO Audits IO» audits that I've conducted.
➡️ Stop ruining "User experience" for the sake of Core Web Vitals for SEO – it's not worth it.
➡️ Stop obsessing over PageSpeed scores when your site is full of duplicate content, cannibalisation issues, thin / dead content, indexing issues.
➡️ Sites that have good content / meets end user needs outrank sites with optimal core web vitals.
➡️ CWV's are LAST MILE ranking factors and even then – the impact is likely marginal.
➡️ Numerous sites I've audited where there was considerable emphasis on SPEED suffereing from horrible layout shifts – no one likes cumulative layout shifts – it's annoying, it causes people to miss their tap target and is really fucking annoying.
➡️ Use a CLS validator to make sure your pages aren't loading like rubbish such as https://webvitals.dev/cls.
➡️ Choosing a tech for your site build based on speed in many cases is a terrible idea – I've seen companies who spent £1 mil + use Angular for speed – only to end up using pre-render and scoring badly after + having lots of indexing issues because of the angular implementation.
➡️ Enforce protocols and make their utilisation consistent – HTTPS should be forced by default.
➡️ Non HTTPS requests should always single hop redirect.
➡️ Internal links (absolute) should always be HTTPS.
➡️ Ensure SCHEMA / Markup validation uses HTTPS (including libraries that are third party).
➡️ Do NOT block resources used to render your page – it can often result in NON MOBILE FRIENDLY warnings – conduct LIVE URL tests in Google Search Console, inspect the render and resource blocking.
➡️ Fast loading pages are a result of numerous processes – not just optimising for core web vitals – use a SPECIALIST to fix speed issues rather than plugins – choose a good server that's over spec not under spec, declutter CMS plugins (anything not used), reduce requests, ensure you use the right image tech (webp) with fall back for non supported browsers.
➡️ ALWAYS trade off speed for experience – an extra 5 of a second lost for the sake of something that loads properly and isn't full of issues is totally worth it – I've worked on multi million pound eCom sites that obsessed over speed and ended up damaging conversion rates (subsequently reverted to their poor scores and conversion rates recovered) – who want's CLS issues in a checkout? or buggy cart opening issues etc?
➡️ SEO IS ABOUT PRIORITISATION – PRIORITIES! As long as your pages load and don't take forever, and your content is accessible – you should get straight to your content offering BEFORE anything else – put core web vitals at the LOWER END of the priority list.
In the screenshot - you can see both of my websites ranking top – one has good page experience – the other has awful page experience.
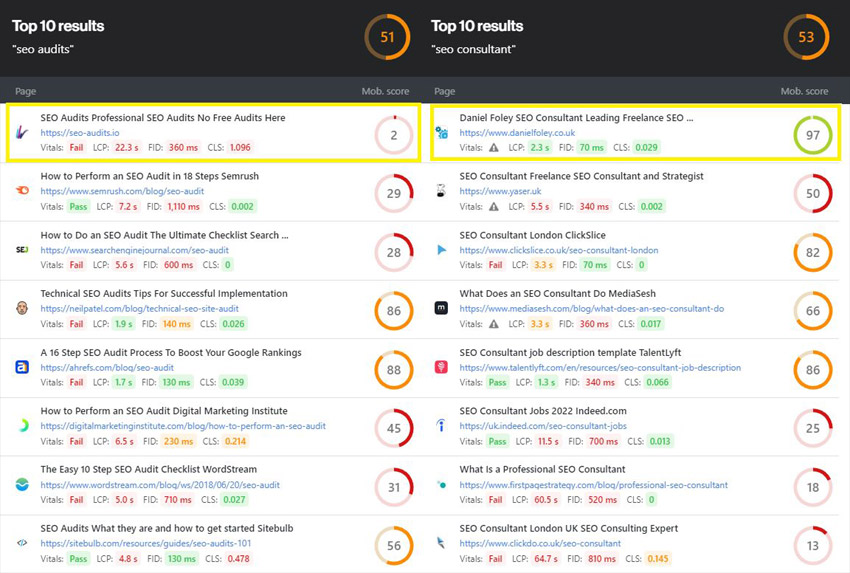
I STILL see SEOs obssessing over speed at a time when there are other issues that should be dealt with.
Author: «Daniel Foley Carter»
Other articles:



















