






















 7,753
7,753After quite a long pause, we have finally released a new version of SiteAnalyzer. We hope it will meet your expectations and become an irreplaceable assistant in SEO promotion.
We have implemented some of the most user-requested features in the new version of SiteAnalyzer, including:
- Data scraping (the extraction of data from a website).
- Content uniqueness check.
- Google PageSpeed score check.
In addition, we have fixed plenty of bugs and changed our logo design. Let us talk about this in details.

Major changes
1. Data scraping with XPath, CSS, XQuery, RegEx.
Web scraping is an automated process of extracting data from specific web pages of the website according to certain rules.
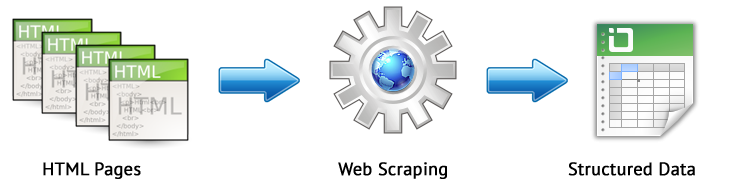
The main web scraping methods are data parsing with XPath, CSS selectors, XQuery, RegExp and HTML templates.
- XPath is a special query language for selecting nodes from XML / XHTML documents. To access elements, XPath utilizes DOM navigation by defining the path to the desired element on the webpage. With the help of it, one can get the value of an element by its ordinal number in the document, extract its text content or internal code, and find a specific element on the webpage.
- CSS selectors are used to find an element or a part of it (attribute). The syntax of CSS is similar to XPath. Nevertheless, in some cases CSS locators work faster and can be defined more clearly and concisely. The downside to CSS is that it only works in one direction — deeper into the document. XPath, on the other hand, works both ways. For instance, you can search for a parent element using its child element.
- XQuery is based on XPath. XQuery mimics XML, which allows you to create nested expressions in a way that is not possible in XSLT.
- RegExp is a formal search language used for extracting values from a set of text strings that match the required conditions (regular expression).
- HTML templates is a language used with HTML documents for data extraction. It is a combination of HTML markup language, used to define a search pattern for the desired fragment, with data extraction and transformation functions and operations.
Usually, scraping is used to solve tasks that are difficult to handle manually. For instance, it is useful when you need to extract product descriptions when creating a new online store, scrape prices for marketing research, or monitor advertisements.

Using SiteAnalyzer, you can configure scraping on the Data Extraction tab. It lets you define the extraction rules. You can save them and edit if needed.
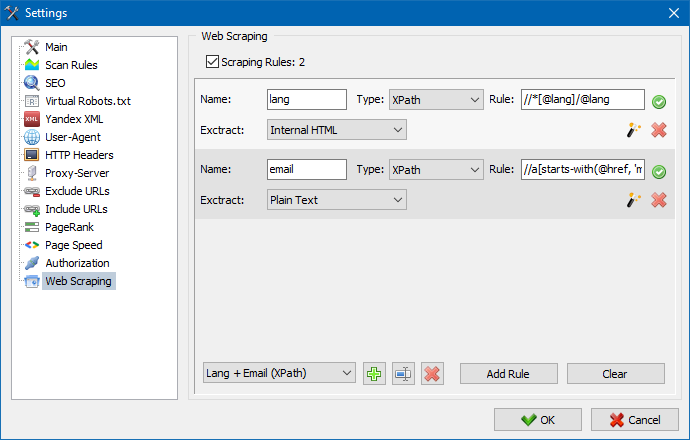
There is also a rule testing module. Using the built-in rule debugger, one can quickly and easily get the HTML content of any page on the website and test HTTP requests. The debugged rules can then be used for data parsing in SiteAnalyzer.

As soon as the data extraction is finished, all the collected information can be exported to Excel.
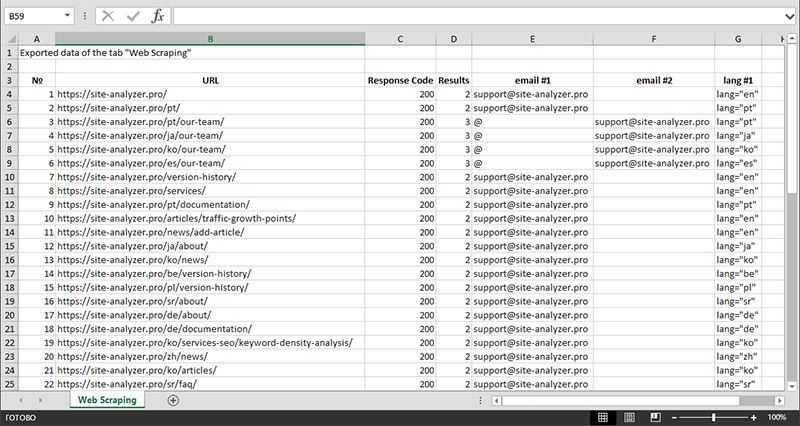
To get more details regarding the module's operation and see the list of the most common rules and regular expressions, check the article "How to parse and extract data from a website for free".
2. Check content uniqueness on a website
This tool allows searching for duplicate pages and check the uniqueness of texts within the website. In other words, you can use it to bulk check numerous pages for uniqueness by comparing them with one another.
This can be useful in such cases as:
- Searching for full duplicate pages (for instance, a specific webpage with parameters and its SEF URL).
- Searching for partial matches in content (for instance, two borscht recipes in a culinary blog that are 96% similar to each other, which suggests that one of the articles should be deleted to avoid SEO cannibalization).
- When you accidentally write an article on your blogging site on the same topic that you have already covered 10 years ago. In this case, our tool will also detect such a duplicate.
Here is how the content uniqueness checking tool works: the program downloads content from the list of website URLs, receives the text content of the page (without the HEAD block and HTML tags), and then compares them with each other using the Shingle algorithm.

Thus, using shingles of texts, the tool determines the uniqueness of each page. It can be used to find duplicate pages with the text content uniqueness of 0%, as well as partial duplicates with varying degrees of text content uniqueness. The program works with 5 characters long shingles.
Read the article "How to check a large number of web pages for duplicate content" to learn more details about this module.
3. Google PageSpeed score checker
The PageSpeed Insights tool from the internet search giant Google allows you to check the download speed of certain page elements. Moreover, it shows the overall download speed score of the specific URLs on the desktop and mobile versions of the browser.

The tool from Google is great in many ways. Nevertheless, it has a huge drawback: you cannot use it to bulk check URLs. It is extremely inconvenient if you want to check multiple webpages on your website. You would probably agree that manually checking the PageSpeed score for each page is tedious and takes a long time, especially if you need to analyze a hundred or even more URLs.
That is why we have created a free module that allows checking the load speed score of multiple pages at once. It utilizes a special API of the Google PageSpeed Insights tool.

Here are the main analyzed parameters:
- FCP (First Contentful Paint) – metric used for measuring the perceived webpage load speed.
- SI (Speed Index) – metric that shows how quickly the contents of a webpage are visibly populated.
- LCP (Largest Contentful Paint) – metric that measures when the largest content element in the viewport becomes visible.
- TTI (Time to Interactive) – metric that measures how much time passes before the webpage is fully interactive.
- TBT (Total Blocking Time) – metric that measures the time that a webpage is blocked from responding to user input.
- CLS (Cumulative Layout Shift) – metric used for measuring visual stability of a webpage.
Since SiteAnalyzer is a multi-threaded program, you can check hundreds of URLs or even more within several minutes. You would have to waste your entire day or even more to check web pages for duplicate content manually.
Moreover, the URL analysis itself only takes a few clicks. As soon as it is ready, you can download the report, which conveniently includes all the data in Excel.
All you need to get started is receive an API key.
Find out how to do in this article.
4. Now you can group projects by folder
We have added the group sites by folder feature to improve navigation through the list of projects.

Additionally, now you can filter the list of projects by name.
5. Updated settings interface
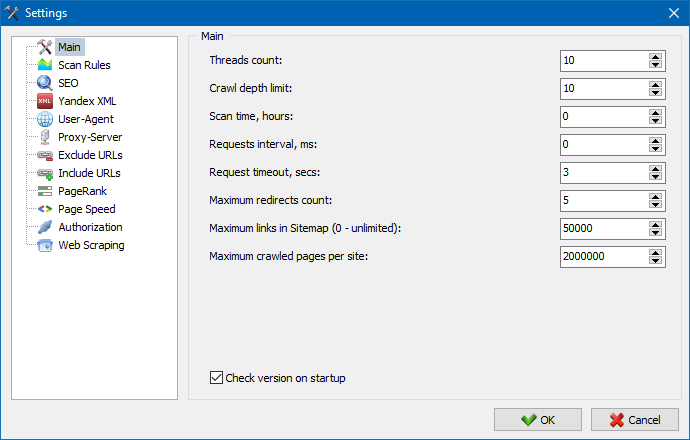
Considering all the new features, we decided to stop using tabs. Instead, we have created a more convenient and functional settings interface.
Other changes
- Fixed incorrect processing of URL exceptions.
- Fixed incorrect processing of website’s crawl depth.
- The display of redirects for URLs imported from a file has been restored.
- The ability to rearrange and save the order of columns on tabs has been restored.
- The processing of non-canonical pages has been restored, fixed an issue with empty meta tags.
- The display of anchor links on the Info tab has been restored.
- Increased the import speed for a large number of URLs from the clipboard.
- Fixed an issue with incorrect parsing of title and description.
- The display of alt and title for images has been restored.
- Fixed an issue when a freeze occurred when switching to the "External links" tab while scanning a project.
- Fixed a program freeze that occurred when switching between projects and updating the nodes of the "Crawl Stats" tab.
- Fixed incorrect definition of nesting level for URLs with parameters.
- Fixed data sorting by HTML-hash field in the main table.
- The processing of Cyrillic domains has been optimized.
- The interface of the program settings has been updated.
- The logo design has been updated.


Author Andrey Simagin
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
News about last versions:



















