























 12,328
12,328It’s not a rare case when a webmaster, marketing expert, or SEO specialist needs to extract data from site pages and display it in a comfortable form for further processing. This could be parsing prices in an online store, getting the number of likes, or extracting reviews from resources you’re interested in.
Most technical site audit software collect only the H1 and H2 header content by default, however, if, for instance, you want to collect the H5 headers, you will have to extract them separately. They usually reach out to web scrapers to avoid the routine manual work of parsing and extracting data from the HTML pages.
Web scraping is a process of automated data extraction from the site pages following certain rules.
Web scraping application fields:
- Tracking the prices of goods in online stores.
- Extracting descriptions of goods and services, getting the number of goods and pictures in a data sheet.
- Extracting contact information (email addresses, phone numbers, etc.).
- Collecting data for marketing research (likes, shares, ratings).
- Extracting specific data from the HTML-page code (searching for analytics systems, checking if there is a micro-markup).
- Monitoring ads.
The basic web scraping methods are parsing methods using XPath, CSS selectors, XQuery, Regex, and HTML templates.
- XPath is a query language for XML/XHTML document elements. To access elements, XPath uses DOM navigation by describing the path to the desired element on the page. Using it, you can get the value of an element by its ordinal number in the document, extract its text content or internal code, check for specific elements on the page. XPath description >>
- CSS selectors are used to find an element of its part (attribute). CSS is syntactically alike to XPath, but in some cases, CSS locators show faster performance and are more descriptive and concise. The only drawback of CSS is that it only works in one direction, i.e. deeper into the document. XPath works both ways (for example, you can search for a parent element by a child). CSS and XPath Comparison table >>
- XQuery is based on XPath. XQuery imitates XML, which allows you to create nested expressions in a way that is not possible in XSLT. XQuery description >>
- Regex is a search language for extracting values from a set of text strings that match the required conditions (regular expression). Regex description >>
- HTML templates is a language for extracting data from HTML documents, which is a combination of HTML markup aimed to describe the search template for the fragment, as well as functions and operations for extracting and transforming data. HTML templates description >>
As a rule, parsing is used to cope with tasks that are difficult to handle manually. This can be web scraping of product descriptions in a new online store, scraping in marketing research to monitor prices or ads (for instance, for apartment sales). For SEO optimization tasks, highly specialized tools are usually used with built-in parsers and all the necessary settings for extracting the main SEO parameters.
BatchURLScraper
There are many tools used for scraping (extracting data from websites), but most of them are paid and cumbersome, which limits their availability for mass use.
So, we decided to develop a simple to use and free tool called BatchURLScraper, designed specially to collect data from a URL list and adapted to export the results to Excel.
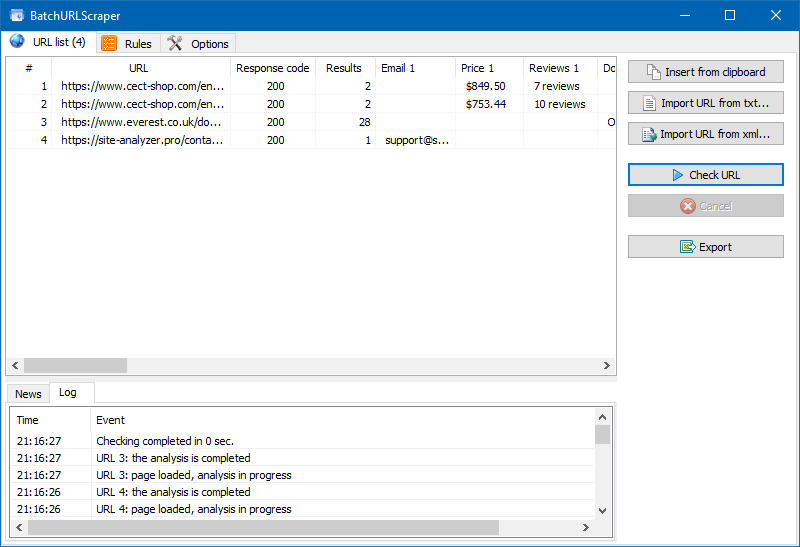
The software interface is quite simple and has only 3 tabs:
- The "URL List" tab is designed to add parsing pages and display the results of data extraction with their subsequent export.
- In the "Rules" tab, you can configure scoping rules using XPath, CSS locators, XQuery, Regex, or HTML templates.
- The "Settings" tab contains general program settings (number of threads, User-Agent, etc.).
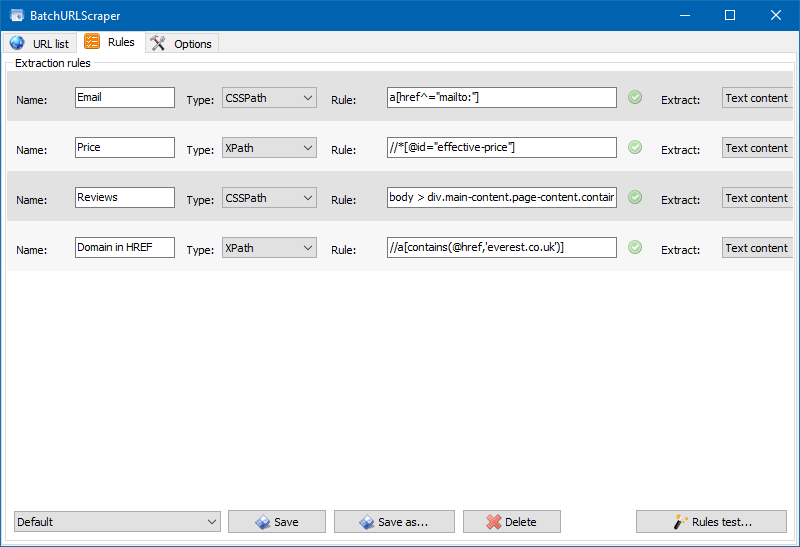
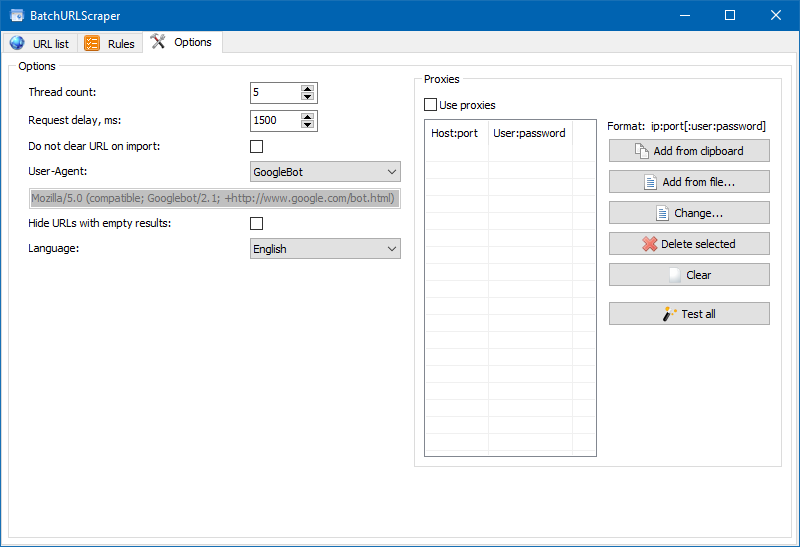
We also added a module for debugging rules.
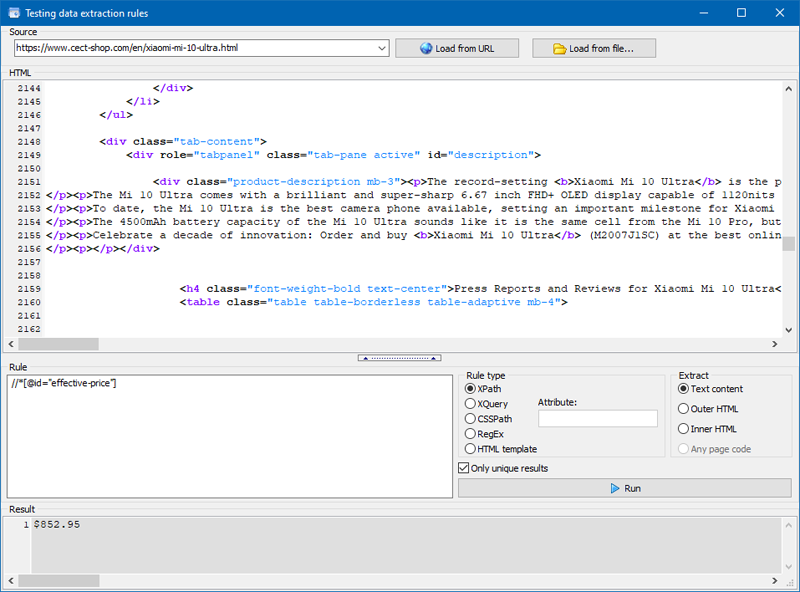
Using the built-in rule debugger, you can quickly and easily get the HTML content of any site page and test the operation of queries, and then use the debugged rules for parsing data in BatchURLScraper.
Let’s consider the examples of parsing configuration for different variants of data extraction.
Examples of extracting data from site pages
Since BatchURLScraper allows you to extract data from an arbitrary list of pages, which may contain URLs from different domains and, accordingly, different types of site, we will use all five scraping variants as examples to test data extraction: XPath, CSS, Regex, XQuery, and HTML templates. The list of test URLs and rule settings are located in the software package, so you can test them all this yourself using presets (preset parsing settings).
Data extraction mechanics
1. An example of scraping using XPath.
For example, in an online mobile phone store, we need to extract prices from the product card pages, as well as an indication of the item availability in stock (available or not).
To extract prices, we need to:
- Go to the product card.
- Highlight the price.
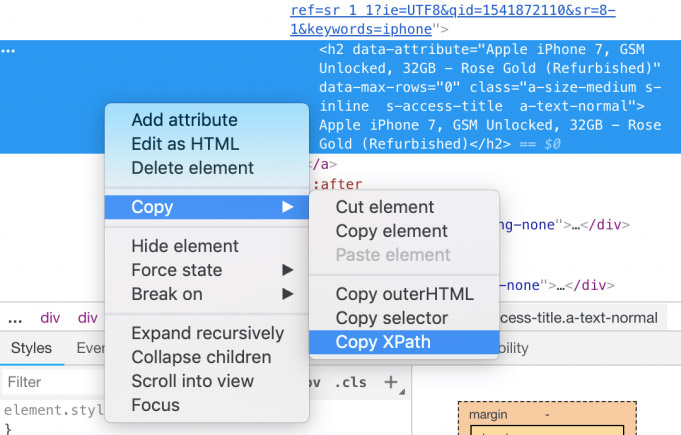
- Right-click on it and click "Inspect".
- In the window that opens, find the element responsible for the price (it will be highlighted).
- Right-click on it and choose Copy > Copy XPath.
In the same way you can extract an indication of the product availability on the site.
Since ordinary pages usually have the same template, it only takes to perform the operation of obtaining XPath for one such typical product page to parse the prices of the entire store.
Next, we add rules one by one in the list of program rules and paste the previously copied XPath element codes from the browser into them.
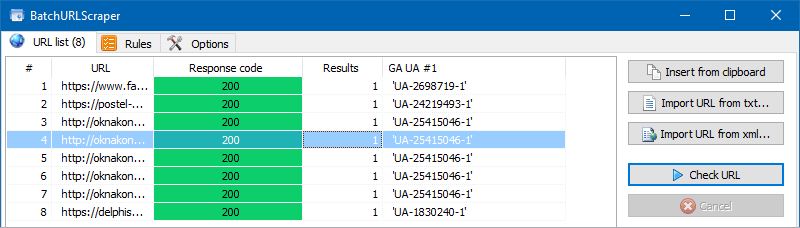
2. Then we need to determine the availability of a Google Analytics counter using Regex or XPath.
- XPath:
- Open the source code of any page using Ctrl-U, then search for the text "gtm.start" in it, look for the UA -... identifier in the code, and then by using the display of the element code we copy its XPath and paste it into a new rule in BatchURLScraper.
- Regex:
- Searching for a counter using regular expressions is even easier: you just need to insert the data extraction rule code ['](UA -.*?)['].
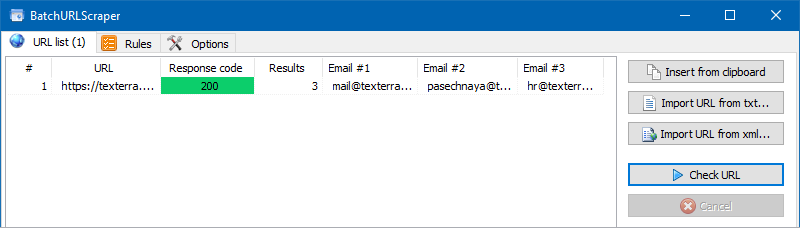
3. Extract contact email address using CSS.
It’s quite simple to do it. If there are hyperlinks like "mailto:" on the site pages, you can extract all email addresses from them.
To do this, we add a new rule, select the CSSPath in it, and insert the rule a[href^="mailto:"] into the data extraction rule code.
4. Extract values into a list or in a table using XQuery.
Unlike other selectors, XQuery allows you to use loops and other programming language features.
For example, using the FOR statement, you can get the values of all LI lists. Example:
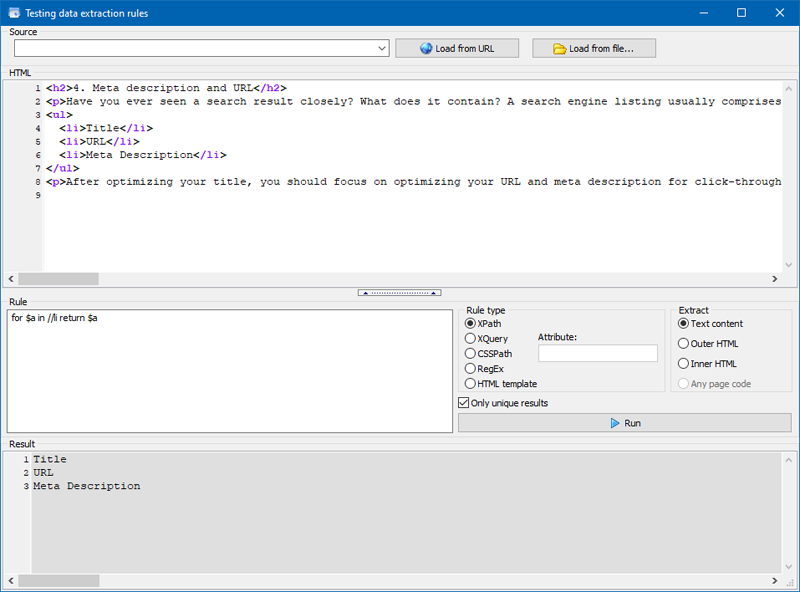
Or you can figure out if there is email on the site pages:
- if (count(//a[starts-with(@href, 'mailto:')])) then "Email is available" else "No email available"
5. Using HTML templates.
In this language, you can use XPath/XQuery, CSSpath, JSONiq, and regular expressions to extract data as functions.
Test table:
| 1 | aaa | other |
| 2 | foo | columns |
| 3 | bar | are |
| 4 | xyz | here |
For example, this template searches for a table with the id="t2" attribute and extracts the text from the second column of the table:
- <table id="t2"><template:loop><tr><td></td><td>{text()}</td></tr></template:loop></table>
Extracting data from second line:
- <table id="t2"><tr></tr><tr><template:loop><td>{text()}</td></template:loop></tr></table>
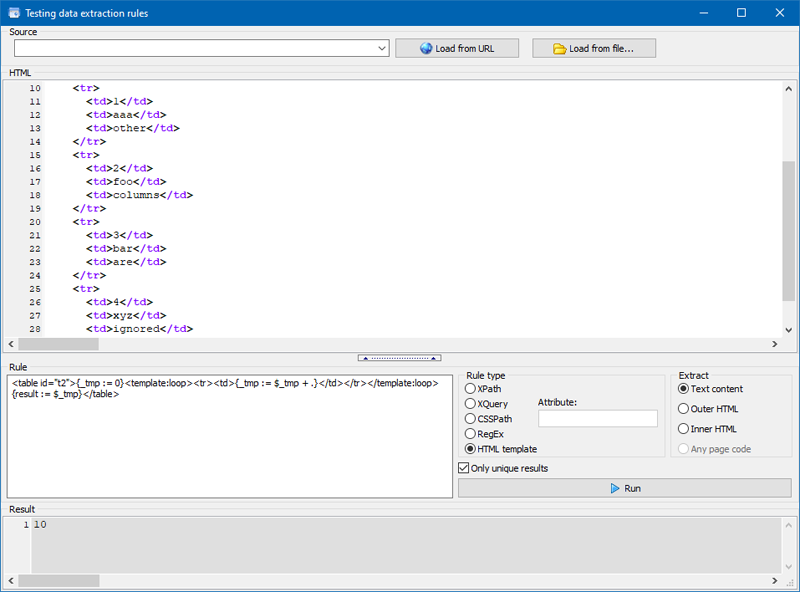
While this template calculates the sum of the numbers in the table column:
- <table id="t2">{_tmp := 0}<template:loop><tr><td>{_tmp := $_tmp + .}</td></tr></template:loop>{result := $_tmp}</table>
Therefore, we were able to extract almost any data from the site pages using an arbitrary list of URLs, including pages on different domains.
The following is a table with the most common rules for extracting data.
Examples of code for extracting data
In the table below, we have compiled a list of the most common data extracting options that can be retrieved using various types of extractors.
| Extractor | Expression | Description |
1. CSSPath |
#comments>h4 |
Content of the ID "comments" and the H4 subtitle in it |
2. CSSPath |
*[src^=http://] |
Finding insecure links to the HTTP protocol |
3. CSSPath |
a[href^=https://yourdomain.com] |
Find pages that contain an absolute URL to your domain in hyperlinks |
4. CSSPath |
a[href^=mailto:] |
Search for links containing mailto URLs: |
5. CSSPath |
a[itemprop=maps]:not([href=your_google_maps_url]) |
Search for pages that do not contain a specific URL on Google Maps |
6. CSSPath |
a[itemprop=maps][href=your_google_maps_url] |
Search for pages containing a specific URL on Google Maps |
7. CSSPath |
body>noscript:has(iframe[src$=GTM-your_tracking_id]):first-child |
Extract Google Tag Manager ID |
8. CSSPath |
head:has(link[rel=alternate][hreflang=es-es][href*=/es/]) |
Search for pages containing href or hreflang=/es/ |
9. CSSPath |
img[alt*=SiteAnalyzer] |
The content of the alt tag, if it contains the SiteAnalyzer text |
10. CSSPath |
link[rel=canonical][href^=http://] |
Finding pages containing HTTP pages in canonical URLs |
11. CSSPath |
link[rel=stylesheet][href^=http://] |
Finding unsafe links to the HTTP protocol in links to CSS style files |
12. CSSPath |
meta[name=description][content*=siteanalyzer] |
The content of the description meta tag, if it contains the SiteAnalyzer text |
13. Regex |
['](GTM-.*?)['] |
Extract Google Tag Manager ID 1 |
14. Regex |
['](GTM-\w+)['] |
Extract Google Tag Manager ID 2 |
15. Regex |
['](UA-.*?)['] |
Retrieving Google Analytics ID |
16. Regex |
[a-zA-Z0-9][a-zA-Z0-9\.+-]+\@[\w-\.]+\.\w+ |
Looking for Email 1 |
17. Regex |
[a-zA-Z0-9-_.]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+ |
Looking for Email 2 |
18. Regex |
\w+ |
Looking for single words |
19. XPath |
//*[@hreflang] |
Content of all hreflang elements |
20. XPath |
//*[@hreflang]/@hreflang |
Specific values ??of hreflang elements |
21. XPath |
//*[@id="our_price"] |
Parsing prices 1 |
22. XPath |
//*[@class="price"] |
Price parsing 2 |
23. XPath |
//*[@itemprop]/@itemprop |
Itemprop rules |
24. XPath |
//*[@itemtype]/@itemtype |
Structured data schema types |
25. XPath |
//*[contains(@class, 'watch-view-count')]" |
Youtube Views |
26. XPath |
//*[contains(@class,'like-button-renderer-dislike-button')])[1] |
Number of video dislikes on Youtube |
27. XPath |
//*[contains(@class,'like-button-renderer-like-button')])[1] |
Number of video likes on Youtube |
28. XPath |
//a[contains(.,'SEO Spider')]/@href |
Links that include anchor SEO Spider |
29. XPath |
//a[contains(@class, 'my_class')] |
Retrieving pages containing a hyperlink with a specific class |
30. XPath |
//a[contains(@href, 'linkedin.com/in') or contains(@href, 'twitter.com/') or contains(@href, 'facebook.com/')]/@href; |
Links to social networks |
31. XPath |
//a[contains(@href, 'site-analyzer.pro')]/@href |
Links to internal pages |
32. XPath |
//a[contains(@href,'screamingfrog.co.uk')] |
Extract links with entry (full code or anchor text) |
33. XPath |
//a[contains(@href,'screamingfrog.co.uk')]/@href |
Extracting exactly the URL with the entry |
34. XPath |
//a[contains(translate(., 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'seo spider')]/@href |
Case sensitive search |
35. XPath |
//a[not(contains(@href, 'site-analyzer.pro'))]/@href |
Links to external pages |
36. XPath |
//a[starts-with(@href, 'mailto')] |
All emails on the page |
37. XPath |
//a[starts-with(@href, 'tel:')] |
All phones on the page |
38. XPath |
//div[@class="example"] |
Content by class |
39. XPath |
//div[@class="main-blog--posts_single--inside"]//a |
Getting anchor text |
40. XPath |
//div[@class="main-blog--posts_single--inside"]//a |
Link source code |
41. XPath |
//div[@class="main-blog--posts_single--inside"]//a/@href |
URL content |
42. XPath |
//div[contains(@class ,'main-blog--posts_single-inner--text--inner')]//h3|//a[@class="comments-link"] |
Several rules in one expression |
43. XPath |
//div[contains(@class, 'rating-box')] |
Parsing rating |
44. XPath |
//div[contains(@class, 'rating-box')] |
Rating parsing |
45. XPath |
//div[contains(@class, 'right-text')]/span[1] |
Parsing the price of a product |
46. XPath |
//div[contains(@class, 'video-line')]/iframe |
Number of videos per page by class |
47. XPath |
//h1/text() |
Getting h1 page |
48. XPath |
//h3 |
Content of all H3 subheadings |
49. XPath |
//head/link[@rel='amphtml']/@href |
Looking for links to APM versions of pages |
50. XPath |
//iframe/@src |
All URLs in IFrame Containers |
51. XPath |
//iframe[contains(@src ,'www.youtube.com/embed/')] |
Find all URLs in IFrame that contain Youtube |
52. XPath |
//iframe[not(contains(@src, 'https://www.googletagmanager.com/'))]/@src |
Find all URLs in IFrame that do not contain GTM |
53. XPath |
//meta[@name='description']/@content |
Description Meta Tag Content |
54. XPath |
//meta[@name='robots']/@content |
Getting Meta Robots values ??(Index / Noindex) |
55. XPath |
//meta[@name='theme-color']/@content |
Content of the header color meta tag for mobile version |
56. XPath |
//meta[@name='viewport']/@content |
Viewport Tag Content |
57. XPath |
//meta[starts-with(@property, 'fb:page_id')]/@content |
Open Graph 1 markup content |
58. XPath |
//meta[starts-with(@property, 'og:title')]/@content |
Open Graph 2 markup content |
59. XPath |
//meta[starts-with(@property, 'twitter:title')]/@content |
Open Graph 3 markup content |
60. XPath |
//span[@class="example"] |
Content by class |
61. XPath |
//table[@class="chars-t"]/tbody/tr[2]/td[2] |
Parsing specific cells in table 1 |
62. XPath |
//table[@class="chars-t"]/tbody/tr[4]/td[2] |
Parsing specific cells in table 2 |
63. XPath |
//title/text() |
Getting the title of the page |
64. XPath |
/descendant::h3[1] |
Content of the first listed subheading H3 |
65. XPath |
/descendant::h3[position() >= 0 and position() <= 10] |
Contents of the first 10 according to the list of H3 subheadings |
66. XPath |
count(//h3) |
Number of subheadings H3 |
67. XPath |
product: "(.*?)" |
JSON-LD structured data 1 |
68. XPath |
ratingValue: "(.*?)" |
JSON-LD structured data 2 |
69. XPath |
reviewCount: "(.*?)" |
JSON-LD structured data 3 |
70. XPath |
string-length(//h3) |
Retrieved string length |
71. XPath |
//a[contains(@rel,'ugc')]/@href |
UGC |
72. XPath |
//a[contains(@rel,'sponsored')]/@href |
Sponsored |
73. XQuery |
if (count(//a[starts-with(@href, 'mailto:')])) then "Email is available" else "No email available" |
Check if there is an Email on the page or not |
74. XQuery |
for $a in //li return $a |
Get contents of all elements of the LI list |
75. HTML templates |
<table id="t2"><template:loop><tr><td></td><td>{text()}</td></tr></template:loop></table> |
Search for a table with attribute id = "t2" and extract text from the second column |
76. HTML templates |
<table id="t2"><tr></tr><tr><template:loop><td>{text()}</td></template:loop></tr></table> |
Retrieving data from the second row of a table |
77. HTML templates |
<table id="t2">{_tmp := 0}<template:loop><tr><td>{_tmp := $_tmp + .}</td></tr></template:loop>{result := $_tmp}</table> |
Calculating the sum of numbers in a table column |
The BatchURLScraper software is implemented in SiteAnalyzer as a separate module and will not be further developed in its current form. Read more...

Author Andrey Simagin
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Other articles:



















