






















 8,594
8,594Hello everyone! We are with you again!
Today we present the version of SiteAnalyzer 2.0, which is incredibly happy! All because in version 2.0, we added we added website structure visualization on a graph (visualization of link associations, like Screaming Frog SEO Spider does it), and also worked on eliminating errors of previous versions that interfered with productive performance.
We hope that the new version will be your indispensable assistant in promotion, optimization and improvement of your projects!

Key Changes
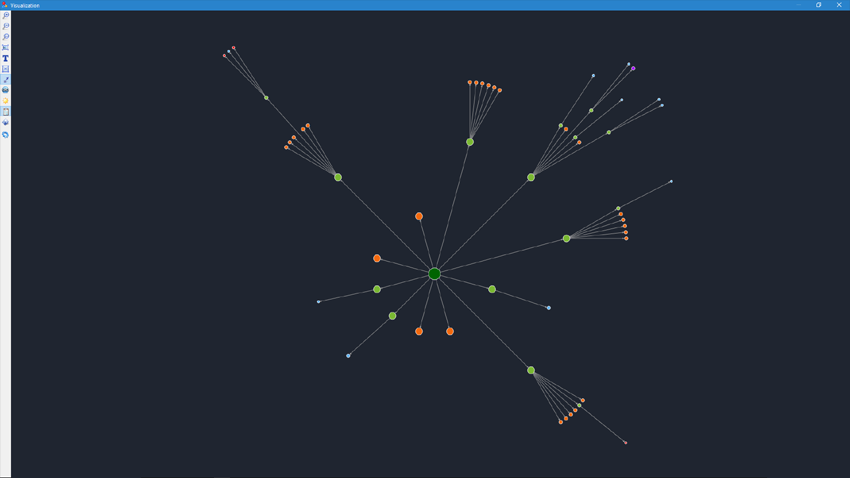
1. Added website structure visualization on a graph.
- The mode of link association visualization on a graph will help SEO specialist assess the internal PageRank distribution on webpages, as well as understand which of the pages get the most link mass (and, accordingly, the higher internal link weight for search engines), and which webpages and website sections lack internal links.
- Thus, using the website structure visualization mode, SEO specialist will be able to visually evaluate how internal linking is organized on the website, as well as by visually presenting the PageRank mass assigned to particular pages, quickly make adjustments to the current website linking, and thereby increase relevance of the pages of interest.


2. Added the website crawling feature by internal URLs.
- In previous versions, website crawling always started from the main page, regardless of the URL being added, so no matter what URL was added to the program: internal or external, website crawling always started from its root.
- Starting from version 2.0, new websites will be crawled relative to the URL being added, not just on the main webpage, as it was before.
3. Added a feature to crawl local websites.
- Now you can crawl URLs of websites operating on stationary computers running the local Live Server web server and similar (for example, you can crawl a website by the local address http://127.0.0.1:5500/ etc.).
4. Added automatic re-crawling of pages if their loading is timed out.
- When crawling websites, sometimes a situation occurs when the website administrator sets up protection against unnecessarily frequent requests to his web resource (for example, to protect websites from DDoS attacks), and as a result the website blocks a large number of simultaneous external requests to it and returns undefined response codes not suitable to get data about the type of loaded content or the content itself.
- Therefore, we have added automatic re-crawling of pages if their loading ends with a server timeout. As a result, if one of the pages got a response of server timeout error during loading instead of the content, then such a page will be queued and crawled again.
5. Optimized control of load speed and saving data to the database.
- Now, saving data to the database will not be so long with a large number of crawling threads, since the scanner algorithm now balances the speed of page loading and the speed of saving data to the database.
6. Added automatic update of program versions.
- Each time the program starts, it checks for a new version on the server, and if there is one, offers to update the version in automatic mode without the need for the user to manually download the archive and update the program files.
7. Added counter for the remaining time of the current project crawling.
- The counter shows a forecast of the crawling duration based on the current crawling speed and the number of links in the queue.

Other changes
- Added the option to copy text from the URL entry field by Ctrl-C.
- Restored the option to scan large arrays of links when importing URLs from a file, clipboard, or by link.
- Fixed a bug with an incorrect server response when parsing pages containing a plus sign (+) in the URL.
- Fixed incorrect export of the website structure to CSV (the number of webpages was not completely exported).
- Fixed incorrect accounting of the BASE tag content when parsing pages (when BASE HREF was a domain).
- Fixed a bug that occurred when deleting arbitrary lines immediately after project crawling (also added URL deletion by the Delete button).
- Fixed a bug where the scanner took into account the contents of "noindex, nofollow" meta tags when disabling this option in the program settings.
- Fixed a bug where the area of the selected cell range was not displayed upon the cursor removal in the table with the basic data.

Thank you for support! Check for updates! :-)

Author Andrey Simagin
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
News about last versions:



















