






















 8,946
8,946We added the option to scan arbitrary URL lists to version 1.9, as well as XML maps of Sitemap.xml (including index) for their subsequent analysis to find "inactive" links, incorrect meta tags, empty headers and the like errors.
Key Changes
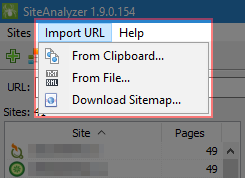
We added the option to scan a list of arbitrary URLs using the clipboard or loading URLs from a file on disk.
- Clipboard. The easiest and fastest option to scan arbitrary URL is using –the clipboard. With a list of URLs for analysis in the clipboard, you select "URL Import" -> "From Clipboard", then the program automatically copies the clipboard contents into a separate form where you can add new URLs or edit the current URLs. After clicking OK, a list of URLs is added to the program, and it starts scanning them, just as if you were scanning a regular website.
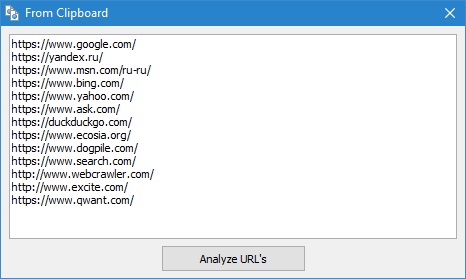
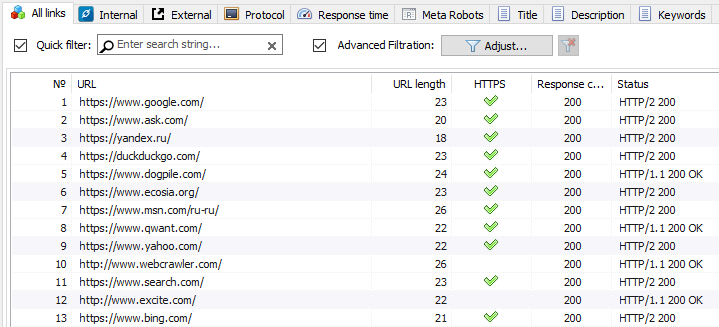
- From a file on disk. This option is useful if the list of URLs for verification is on the hard disk in a text file or in a Sitemap file (*.txt and *.xml formats). In this case, importing URLs from this type of files is similar to importing from the clipboard, with the only exception that after opening files, they are parsed to find URLs in them, and then the procedure of adding found URLs to the form is repeated, followed by their scanning by SiteAnalyzer.
- Note: when importing Sitemap.xml from a hard disk, it is analyzed for whether it is an index file, and if so, the form displays a list of internal XML files which contents will be downloaded and added to the program. When importing text files that contain URL lists, they are simply added to the form to send URLs for subsequent scanning.
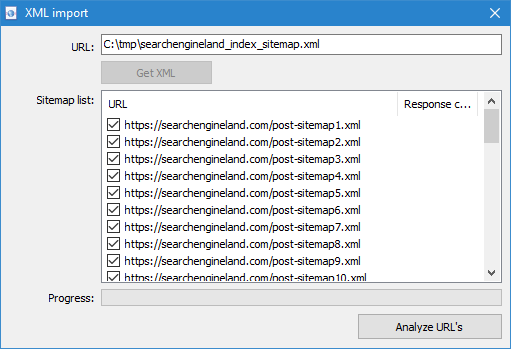
We added a feature to scan Sitemap.xml files (a classic or index Sitemap with a list of XML files).
- Sitemap.xml scanning directly from the website is available through the menu item "URL Import" -> "Download Sitemap". In the window that appears, specify the URL for downloading and parsing the Sitemap.xml contents. After clicking "Import", the program will analyze file contents to determine whether this sitemap is index or is it a classic Sitemap.xml with a list of the site URLs.
- Classic Sitemap.xml. If it turned out to be a classic Sitemap.xml, the program parses all its URLs and, after clicking OK, adds them to the program and starts scanning them.
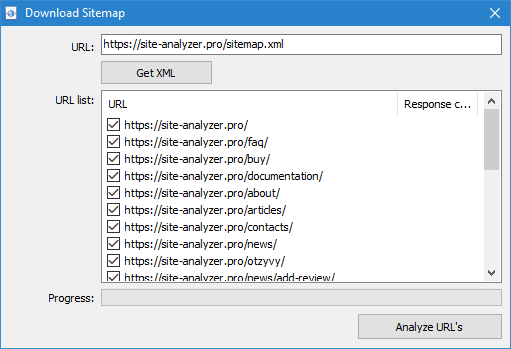
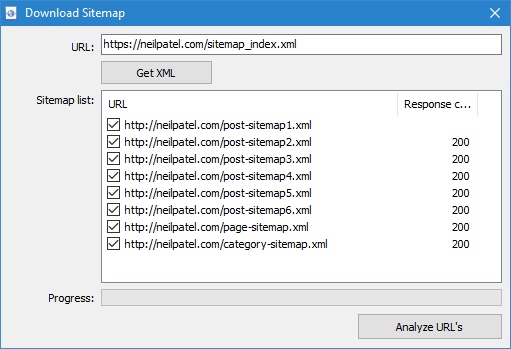
- Index Sitemap.xml. If Sitemap.xml is an index file, the program will display a list of its internal *.xml files in the same window, as well as the response code of each of them. By using checkboxes, you can select the files with contents you plan to scan. After clicking OK button, the contents of these XML files will also be added to the program and scanning will begin.
Notes:
- URL importing is accompanied by automatic validation of links for correctness. If the string is not a URL, it will not be added to the scan queue.
- The program only scans URLs sent for validation. Thus, when parsing an URL, the scanner does not follow the links and does not add them to the scan list, as in case of scanning full-fledged websites. The number of URLs imported at the input – will be scanned at the output. This feature applies to all types of arbitrary URL scans.
- When scanning arbitrary URLs, the "project" itself is not saved in the program and data on it is not added to the database. "Website Structure" and "Dashboard" sections are also unavailable.
Other changes
- We added a feature to select and copy cell values to the clipboard by clicking Ctrl+A.
- We made faster the operation of deleting projects (to completely delete projects compress the database via the program menu).
- We fixed problem with not always correct counting of empty H1 tags.
- We fixed problem with not always correct parsing of attribute <title> in images.
- We fixed program hang-up when scrolling through records during scanning.
We do not stop on what has already been achieved and are already developing a new feature for you, which we plan to release in the nearest future.
Check for updates! :-)

Author Andrey Simagin
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
What to read about Sitemap.xml:



















