






















BatchURLScraper is designed to extract data from web pages according to a list of URLs. The app supports parsing and data extraction using XPath, CSSPath, XQuery, HTML templates and Regex methods.
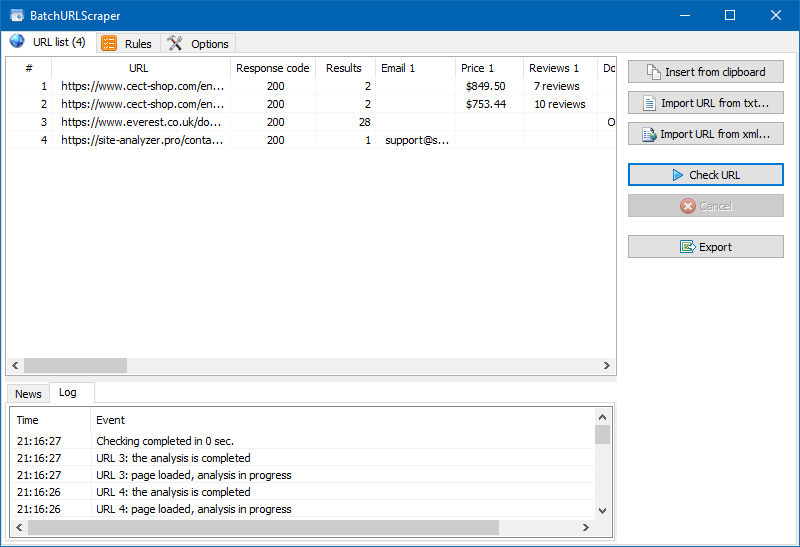
Configuring data extraction rules
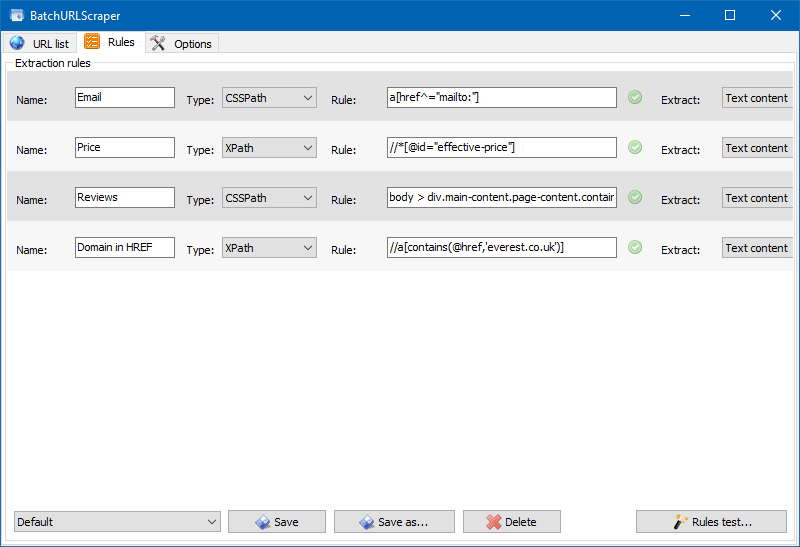
Test Rules
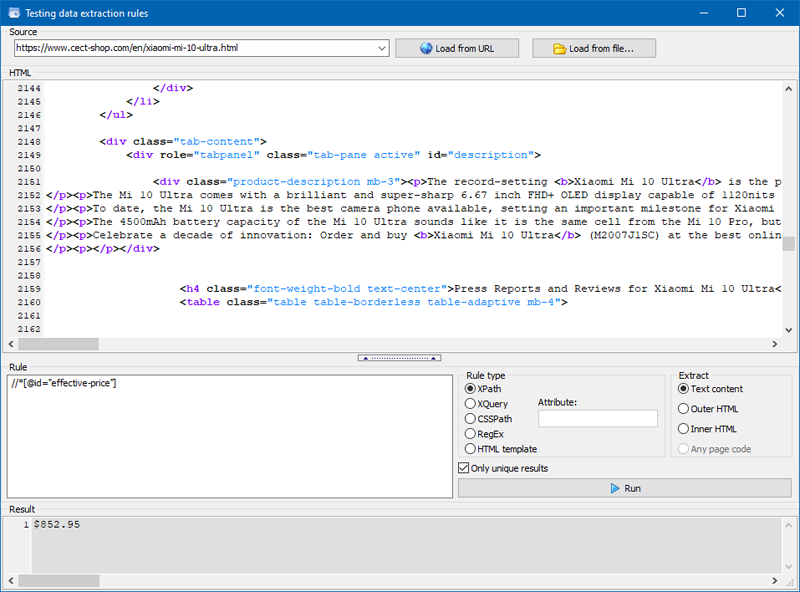
General Settings
Terms of use: Freeware
The BatchURLScraper software is implemented in SiteAnalyzer as a separate module and will not be further developed in its current form. Read more...
Key Features
- Data parsing and extraction from a list of URLs
- Parsing by XPath, CSSPath, XQuery, HTML templates and Regex extraction methods
- Proxy lists support
- Export reports to Excel (CSV format)
Differences From Analogues
- Multithreading and quick data scraping
- Portable format (works without installation from any internal or external storage drive)
- Freeware
Version History
Version 1.4 (build 29), 27.04.2021:
- fixed program freezing if data for one of the rules was not found
Version 1.4 (build 28), 25.02.2021:
- fixed incorrect work of the program with threads
- the number of URL validation errors should be significantly less
Version 1.4 (build 27), 08.12.2020:
- fixed error with validation of HTML templates
- optimized work with regular expressions
- we added ability to ignore duplications in scraping results
Version 1.4 (build 26), 07.12.2020:
- fixed problem with not correct using pauses between requests to web pages
- range of pauses between requests has been extended to one and a half minutes
- finalized and improved translation
- fixed memory leaks
Version 1.3 (build 25), 26.11.2020:
- expanded the number of pages for parsing from 1000 to 5000 URLs
- added the ability to scrape through HTML templates
- added the ability to extract data through CSSpath attributes
- added the ability to scrape through External and Internal HTML
- added the ability to use Proxy Servers lists
- fixed bug with incorrect User-Agent saving
Version 1.2 (build 19), 17.11.2020:
- we added scraping method via XQuery
- we optimized HTML parsing
- we optimized filter settings for data extraction
- we optimized setting of presets for parsing
- we added a module for testing parsing rules
Version 1.1 (build 12), 04.11.2020:
- we added multithreaded data parsing and extraction from a list of URLs (up to 10 threads simultaneously)
- we added flexible filters for data extraction
- we added export reports to Excel (CSV)
Version 1.0 (build 6), 29.10.2020:
- data parsing and extraction from a list of URLs
- XPath, CSSPath, and RegExp data extraction methods support
- customizable parsing presets
Minimum system requirements
– 1 GB RAM (recommended 8 GB and more)
– Microsoft Windows 10/8/7/Vista/XP
– Internet



















