






















 6,221
6,221Hello everyone! It’s been a long time since the last release of SiteAnalyzer. However, we did not sit still and implemented plenty of new features, as well as fixed a number of existed bugs and errors.

The latest version of SiteAnalyzer includes around 30 new features. Some of the major ones are the custom HTTP headers support, virtual Robots.txt files, and the "Source" column for images. Let us talk about them in detail.
Major changes
1. Custom HTTP headers
We have added the ability to use custom HTTP headers when accessing a server.
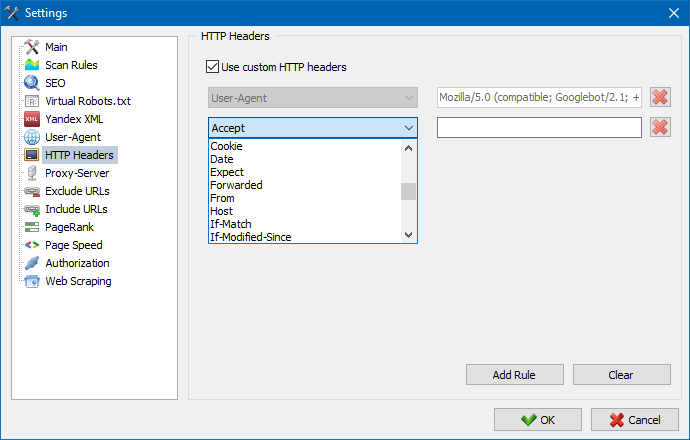
This option allows analyzing the behavior of a website and pages when dealing with different requests.
For example, someone may need to send a Referer in a request. The administrator of a multilingual site might want to send Accept-Language|Charset|Encoding. Some people might need to send unusual data in the Accept-Encoding, Cache-Control, Pragma headers, etc.
Note: the User-Agent header is configured on a separate tab in the "User-Agent" settings.
2. Virtual Robots.txt
Added the support of a virtual robots.txt file. You can use it instead of the real one, which is located at the root of the site.
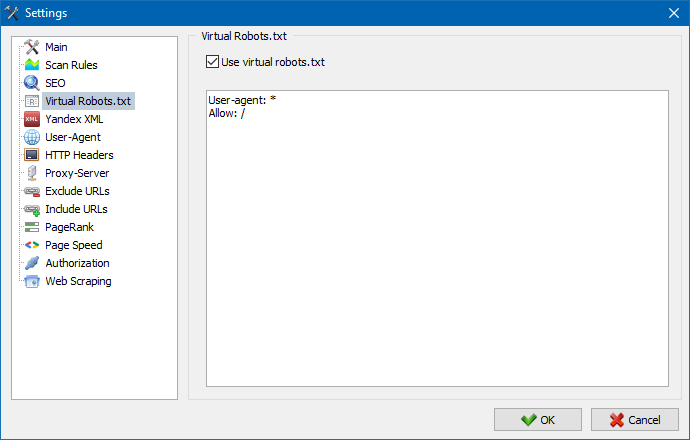
This feature is especially convenient for website performance testing. For example, when you need to scan specific non-indexable sections – or do not include them during the scan. You will not need to waste the developer's time changing the real robots.txt.
A virtual Robots.txt file is stored in the program settings and is common for all projects.
Note: when importing the list of URLs, the instructions in the virtual robots.txt are taken into account (if this option is activated). Otherwise, no robots.txt is taken into account for the URL list.
3. Uniqueness check
The uniqueness check tab now features the list of URLs with the most similar content.
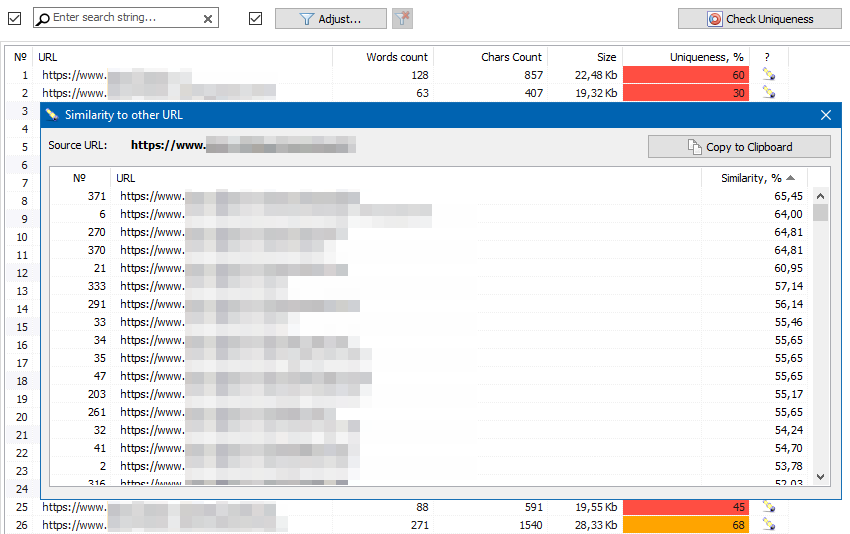
If necessary, you can export data from the table to the clipboard.
4. "Source" column in the "Images" tab
The "Images" tab now features a "Source" column, which shows the URL source of the image.
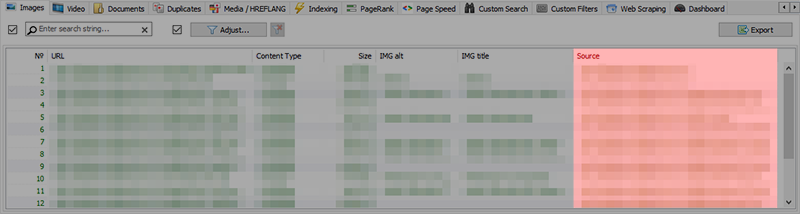
Note: This column features the first scanned page of a website, which has the URL of the image.
5. The date of the last scan
The project list now features the date of the last scan for each project.
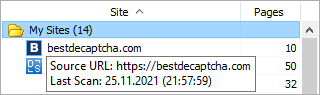
This hint is displayed when you hover the mouse over the site in the list of projects. At the moment, it has an informational purpose only.
6. Check websites at Web.Archive.org and open Robots.txt files in a web-browser
Now you can open the specific URL at Web.Archive.org, as well as open a robots.txt file of a specific site in a web browser.
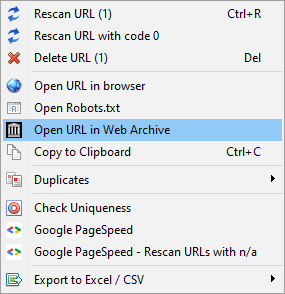
This feature is designed to improve user experience and speed up the work process.
7. URL exception list
Optimized the work of the exception list for website scan. It now supports regular expressions (RegEx).
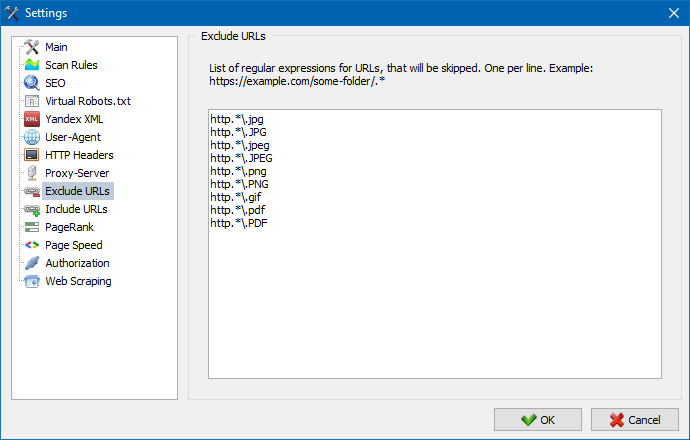
The RegEx support makes the exception list even more flexible. Check this article to see the examples of regular expressions.
Other changes
- Added the ability to cancel the proxy list test at any moment after its launch.
- Rescan of the project’s custom URLs can now be multithreaded according to the settings.
- Added the SERPRiver service to the Yandex XML settings tab, which provides information about page indexing on Yandex Search Engine.
- Fixed the Custom Search feature, used for content search on websites.
- Added the ability to move several projects to folders using drag-and-drop or context menu.
- Added extra buttons to check Google PageSpeed and content uniqueness on the corresponding tabs.
- Optimized and enhanced the rule setting for robots.txt files.
- Fixed an issue that occurred when a robots.txt file has incorrect rules.
- Fixed incorrect subdomain inclusion when the "Include subdomain" option is active.
- Fixed incorrect encoding of the HTML code in the data extraction test form.
- Fixed incorrect sorting of the "TOP domains" tab, as well as other filters of the "Custom Filters" tab.
- Fixed a bug that occurred when adding unlisted URLs to the filter of projects.
- Fixed incorrect encoding for sites that use the Windows-1251 encoding.
- Fixed incorrect data filtering when switching between regular tabs and Custom Filters.
- Fixed a bug that occurred when scanning a large number of sites in the list of projects.
- Fixed the detailed decryption of data received from Google PageSpeed.
- Fixed error statistics display for Title, Description and H1 headings.
- The redundant context menu has been hidden in the Custom filters section.
- Optimized adding a large number of URLs to the list of projects.
- Fixed incorrect detection of URL nesting level.
- Optimized the process of URLs removal in projects.


Author Andrey Simagin
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
News about last versions:


















