






















 7,640
7,640In version 1.9.2, we adapted the program to 64-bit Windows systems (now it can scan websites of up to 10 million pages or more), as well as increased website crawling speed and at the same time reduced memory consumption. Along with this, we fixed a lot of accumulated bugs and introduced several of the most important wishes of our users.

Key Changes
1. Switch to the 64-bit version.
- We are pleased to announce the release of SiteAnalyzer x64 optimized to work on 64-bit Windows systems. Thus, crawling websites of up to 10 million or more pages became available for users who downloaded SiteAnalyzer x64, since in 64-bit Windows systems you can use the entire amount of installed RAM. Therefore, now you can crawl websites of almost any volume (volumes are limited only by the power of your hardware and hard disk capacity). At the same time, we do not forget about users of 32-bit systems, so we plan to continue supporting the 32-bit version of SiteAnalyzer.
2. We increased website crawling speed and reduced memory consumption.
- We optimized memory consumption when crawling pages with a lot of hyperlinks. We also increased crawling speed.
- We conducted a study with the participation of our main competitors: 100,000 pages of theguardian.com were crawled in Screaming Frog SEO Spider and Netpeak Spider with similar settings (without JavaScript rendering). RAM consumption test results:
- Screaming Frog SEO Spider 11.0: 15 802 Mb.
- Netpeak Spider 3.2: 1 286 Mb.
- SiteAnalyzer 1.9.2: 815 Mb.
- Thus, SiteAnalyzer overcomes Screaming Frog SEO Spider by 19 (!) times in terms of RAM consumption, and Netpeak Spider by 1.5 times.
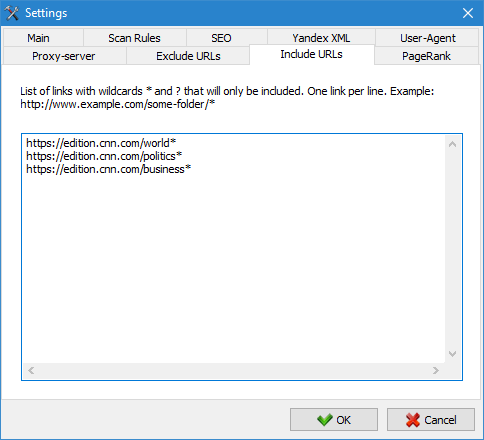
3. We added an option of crawling specific URL groups, without having to crawl the entire website.
- A new tab "Follow URL" has been added to the program settings to add URLs that must be crawled. In this case, all other URLs outside of these folders will be ignored during crawling.
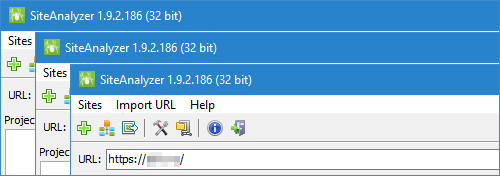
4. We added an option to run multiple program copies at the same time.
- Taking into account the wishes of our users, we added an option to run multiple program copies at the same time. Thus, simply by copying the distribution package of the program to a new folder, you can simultaneously run two or more program copies, and, accordingly, simultaneously crawl several websites.
Other changes
- Added an option of saving advanced filtering parameters when switching between tabs of the active project.
- Added memorization of column widths on tabs.
- Added an option to pause crawling a list of imported URLs.
- The lastmode parameter is taken into account when generating a Sitemap.
- Added Server column indicating the type of server hosting the website (example: nginx/1.16.0).
- Added display of states <null> and < empty> for H1-H6 headers.
- Added an option to crawl pages that do not respond with the Content-type header value.
- Optimized calculation of H1-H6 duplicates (null or empty H1-H6 are now not taken into account).
- Contents of the "Exclude URL" tab of the general program settings have become common to all projects.
- Improved page encoding detection.
- Fixed incorrect display of pages with 3xx redirects.
- Fixed a bug related to incorrect accounting for "robots.txt" rules.
- Fixed incorrect parsing of pages containing a plus sign (+) in the URL.
- Fixed accounting of images when crawling a website when only HTML parsing is allowed in the settings (if, for example, disabled objects issue a 404 response code).
- Fixed a crash that occurred when loading large projects.
- Fixed a bug that occurred when loading large projects when the lower progress bar showed more than 100%.
- Assigned a blue icon to 301 and 302 redirects instead of an orange when calculating SEO statistics, and set 1 weight point instead of 3.
Note: due to updating the database structure, all projects must be re-scanned. How to add projects from the old version to the new one is described in the FAQ section.

Thank you for support! Check for updates! :-)

Author Andrey Simagin
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
News about last versions:



















