






















 3,839
3,839Das Problem der Ermittlung doppelter Seiten und der Eindeutigkeit von Texten innerhalb der Website ist eines der wichtigsten in der Liste der Arbeiten zur technischen Prüfung. Das Vorhandensein doppelter Seiten bestimmt sowohl das allgemeine Wohlbefinden der Website als auch die Verteilung des Suchmaschinen-Crawling-Budgets, das möglicherweise verschwendet wird. Im Allgemeinen kann das Ranking der Website aufgrund der großen Menge doppelter Inhalte zu Schwierigkeiten führen.

Und wenn Sie leicht eine große Anzahl von Diensten und Programmen finden können, um die Eindeutigkeit einzelner Texte im Internet zu überprüfen, gibt es nicht viele ähnliche Dienste, um die Eindeutigkeit einer Gruppe spezifischer URLs untereinander zu überprüfen, obwohl das Problem selbst wichtig und relevant ist.
Welche Optionen für Probleme mit nicht eindeutigen Inhalten können auf der Website vorhanden sein?
1. Gleicher Inhalt für verschiedene URLs.
Normalerweise ist dies eine Seite mit Parametern und derselben Seite, jedoch in Form einer SEF (lesbare URL).
- Beispiel:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Dies ist ein ziemlich häufiges problem, wenn der Programmierer nach dem Einrichten der SEF vergisst, eine 301-Umleitung von Seiten mit Parametern zu Seiten mit SEF einzurichten.
Dieses Problem kann leicht von jedem Webcrawler gelöst werden, der nach einem Vergleich aller Seiten der Site feststellt, dass zwei von ihnen denselben Hash-Code (MD5) haben, und den Optimierer informiert, der die Aufgabe festlegen muss, denselben Programmierer, um 301 Weiterleitungen zu installieren zu SEF-Seiten.
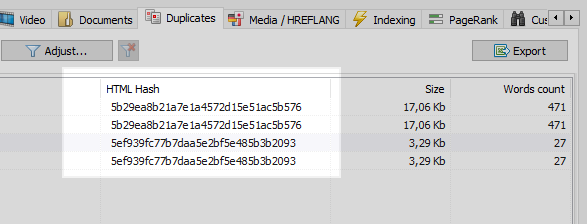
Es ist jedoch nicht alles so einfach.
2. Überlappender Inhalt.
Ähnliche Inhalte werden generiert, wenn wir unterschiedliche Seiten haben, jedoch tatsächlich dieselben oder ähnliche Inhalte.
Beispiel 1
Auf der Website für den Verkauf von Kunststofffenstern im News-Bereich gratulierte ein Texter vor einem Jahr am 8. März zu 500 Zeichen und gab 15% Rabatt auf die Installation von Kunststofffenstern.
Und in diesem Jahr entschied sich der Content Manager für "Betrug" und fand ohne weiteres die zuvor veröffentlichten Nachrichten mit Rabatten, kopierte sie und änderte die Größe des Rabatts von 15 auf 12% + fügte mit zusätzlichen Glückwünschen 50 Zeichen von sich hinzu.
Am Ende haben wir also zwei fast identische, zu 90% ähnliche Texte, die an sich unscharfe Duplikate sind, von denen einer aus gutem Grund dringend umgeschrieben werden muss.
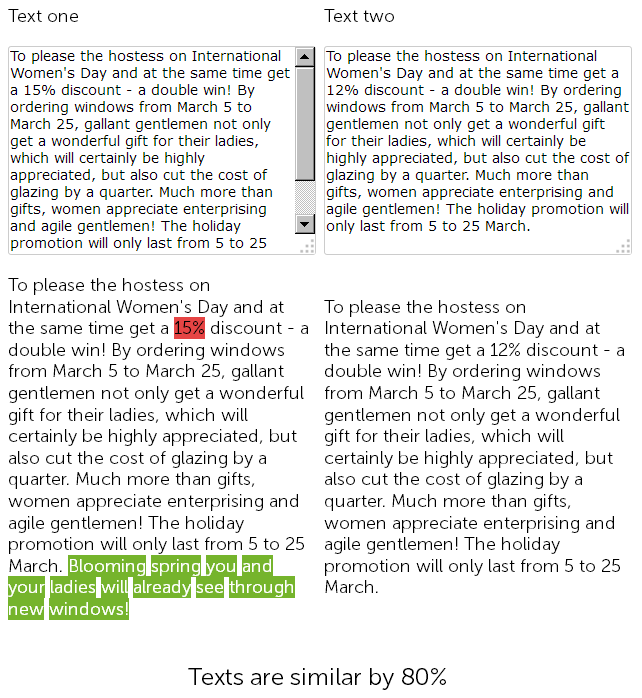
Gleichzeitig sind diese beiden Nachrichten für technische Auditdienste unterschiedlich, da die SEF auf der Site bereits konfiguriert wurde und die Prüfsummen der Seiten nicht übereinstimmen, was auch immer man sagen mag.
Am Ende ist es eine große Frage, welche Seite besser rangiert...
Aber sie sind solche Neuigkeiten - sie sind in der Regel schnell veraltet. Nehmen wir also ein interessanteres Beispiel.
Beispiel 2
Sie haben einen Artikelbereich auf Ihrer Website oder Sie pflegen eine persönliche Seite für Ihr Hobby / Hobby, zum Beispiel ist es ein "kulinarischer Blog".
Und zum Beispiel hat Ihr Blog bereits eine Bestellung von Artikeln für die gesamte Zeit gesammelt, mehr als 100 oder sogar mehrere Hundert. Und so haben Sie ein Thema aufgegriffen und einen neuen Artikel geschrieben, gepostet und später irgendwie entdeckt, dass ein ähnlicher Artikel bereits vor 3 Jahren geschrieben wurde. Obwohl es so aussieht, als hätten Sie vor dem Schreiben des Inhalts alle Titel durchgesehen, Excel mit einer Liste der veröffentlichten Themen geöffnet, aber nicht berücksichtigt, dass der frühere Inhalt des Artikels "Wie man heiße Schokolade zu Hause macht" stark mit dem gerade geschriebenen Material übereinstimmt. Und wenn man diese beiden Artikel in einem der Onlinedienste überprüft, stellt sich heraus, dass sie zu 78% einzigartig sind, was natürlich nicht gut ist, da Suchabfragen zwischen diesen Seiten und der Suchmaschine aufgrund teilweiser Duplizierung ausschlachten Fragen und Schwierigkeiten ergeben sich bei der Einstufung solcher Duplikate.
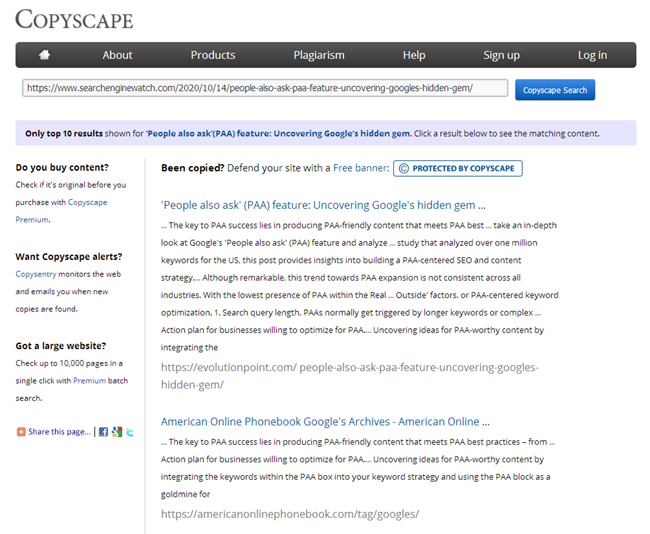
Natürlich muss jeder Texter nach dem Schreiben eines Artikels prüfen, ob er in einem der bekannten Dienste eindeutig ist, und jeder SEO ist verpflichtet, neue Inhalte zu überprüfen, wenn er auf der Website in denselben Diensten veröffentlicht wird.
Was tun, wenn eine Website gerade zur Werbung bei Ihnen eingetroffen ist und Sie alle Seiten schnell auf Duplikate überprüfen müssen? Oder Sie haben zu Beginn der Eröffnung Ihres Blogs eine Reihe von Artikeln des gleichen Typs geschrieben, und jetzt begann die Website höchstwahrscheinlich aufgrund dieser Artikel zu sinken. Überprüfen Sie nicht 100.500 Seiten in Online-Diensten von Hand. Fügen Sie hinzu, um jeden Artikel von Hand zu überprüfen, und verbringen Sie viel Zeit damit.
BatchUniqueChecker
Aus diesem Grund haben wir das Programm BatchUniqueChecker erstellt, mit dem eine Gruppe von URLs stapelweise auf Eindeutigkeit untereinander überprüft werden kann.
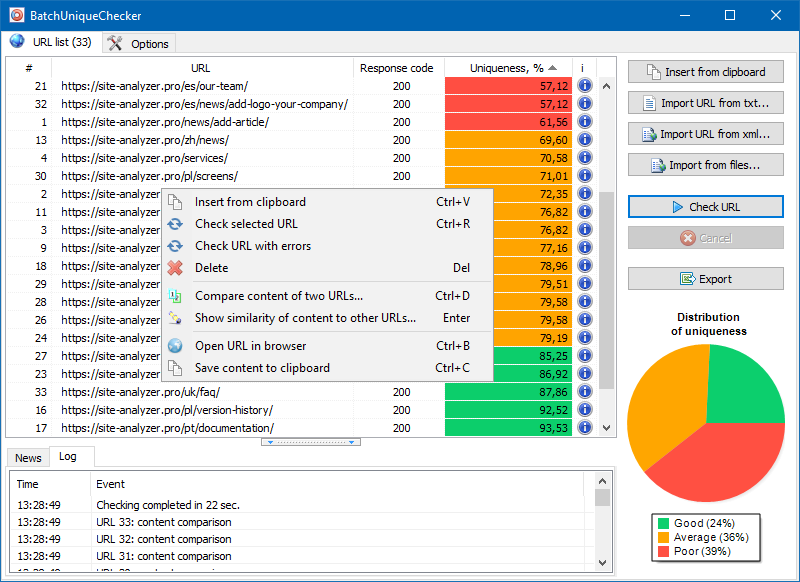
Das Funktionsprinzip von BatchUniqueChecker ist einfach: Das Programm lädt seinen Inhalt unter Verwendung einer zuvor vorbereiteten Liste von URLs herunter, empfängt PlainText (den Textinhalt der Seite ohne HEAD-Block und ohne HTML-Tags) und vergleicht sie dann unter Verwendung des Shingle-Algorithmus miteinander.
Mit Hilfe von Schindeln bestimmen wir daher die Eindeutigkeit von Seiten und können sowohl vollständige Duplikate von Seiten mit 0% Eindeutigkeit als auch teilweise Duplikate mit unterschiedlichem Grad an Eindeutigkeit des Textinhalts berechnen.
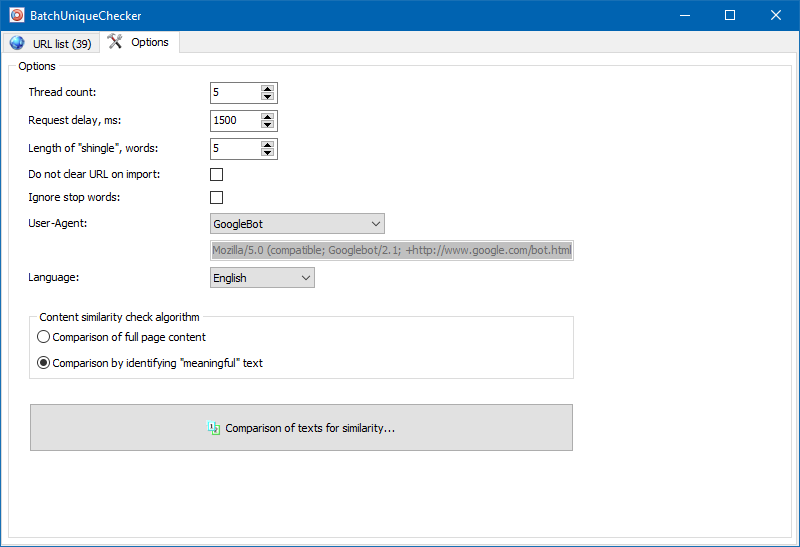
In den Programmeinstellungen können Sie die Größe der Schindel manuell einstellen (Schindel ist die Anzahl der Wörter im Text, deren Prüfsumme abwechselnd mit den nachfolgenden Gruppen verglichen wird). Wir empfehlen, den Wert = 4 zu setzen. Für große Textmengen ab 5. Für relativ kleine Mengen - 3-4.
Sinnvolle Texte
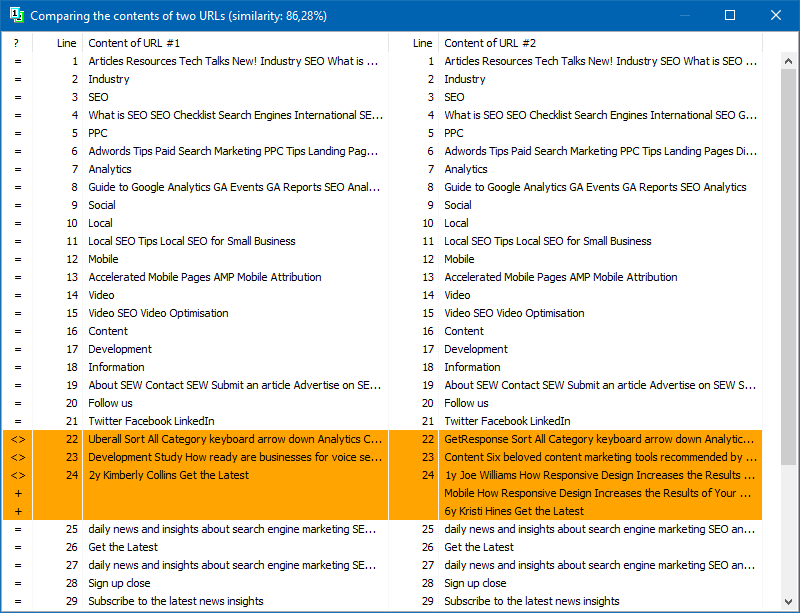
Neben dem Volltextvergleich von Inhalten enthält das Programm einen Algorithmus zur "intelligenten" Isolierung sogenannter "signifikanter" Texte.
Das heißt, vom HTML-Code der Seite erhalten wir nur den Inhalt, der in den Tags H1-H6, P, PRE und LI enthalten ist. Aus diesem Grund verwerfen wir sozusagen alles "Nicht Wesentliche", z. B. Inhalte aus dem Site-Navigationsmenü, Text aus der Fußzeile oder dem Seitenmenü.
Als Ergebnis solcher Manipulationen erhalten wir nur "aussagekräftigen" Seiteninhalt, der im Vergleich genauere Eindeutigkeitsergebnisse mit anderen Seiten zeigt.
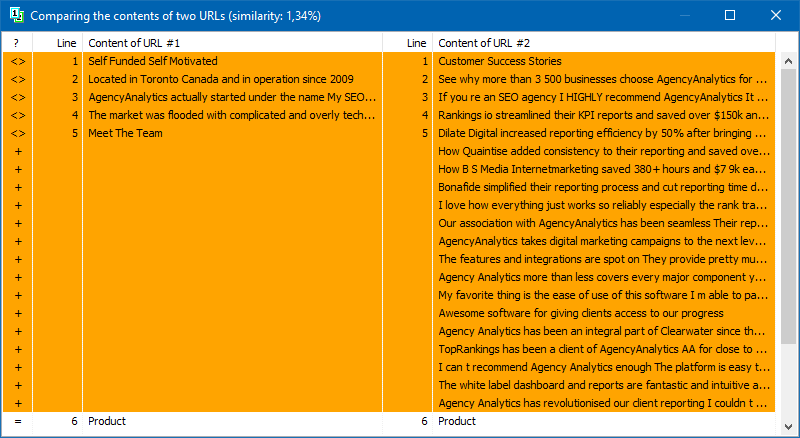
Die Liste der Seiten für die nachfolgende Analyse kann auf verschiedene Arten hinzugefügt werden: Einfügen aus der Zwischenablage, Laden aus einer Textdatei oder Importieren aus Sitemap.xml von Ihrer Computerdiskette.
Aufgrund des Multithread-Vorgangs des Programms kann das Überprüfen von Hunderten oder mehr URLs nur wenige Minuten dauern, was im manuellen Modus über Onlinedienste einen Tag oder länger dauern kann.
Auf diese Weise erhalten Sie ein einfaches Tool, mit dem Sie schnell die Eindeutigkeit von Inhalten für eine Gruppe von URLs überprüfen können, die auch von Wechselmedien ausgeführt werden können.
BatchUniqueChecker ist kostenlos, benötigt nur 4 MB im Archiv und erfordert keine Installation.
Sie müssen lediglich das Distributionskit herunterladen und eine Liste der für die Überprüfung interessanten URLs hinzufügen, die über ein kostenloses technisches Audit-Programm abgerufen werden können SiteAnalyzer.

Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Andere Artikel



















