






















 4,022
4,022在技术审核工作清单中,确定重复页面和站点内文本唯一性的问题是最重要的问题之一。重复页面的存在决定了网站的整体状况和搜索引擎抓取预算的分配,这可能是浪费的,并且通常,由于重复内容的数量很多,网站的排名可能很困难。

并且,如果您可以轻松地找到大量服务和程序来检查Internet上单个文本的唯一性,那么尽管问题本身很重要且相关,但没有很多类似的服务可以检查一组特定URL之间的唯一性。
网站上可以有哪些解决非唯一内容问题的选项?
1.不同URL的内容相同。
通常,这是带有参数的页面和同一页面,但是形式为SEF(人类可读的URL)。
- 例:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
当设置SEF后,程序员忘记设置从带有参数的页面到带有SEF的页面的301重定向时,这是一个相当普遍的问题。
任何Web爬网程序都可以轻松解决此问题,在对站点的所有页面进行比较之后,它们会发现其中两个页面具有相同的哈希码(MD5),并通知优化器,后者必须由同一程序员设置任务,以安装301重定向。到SEF页面。
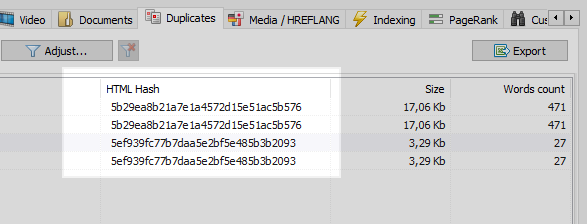
但是,并非一切都那么简单。
2.重叠内容。
当我们拥有不同的页面,但实际上具有相同或相似的内容时,会生成相似的内容。
例 1
一年前,在塑料窗销售网站的新闻部分,一名撰稿人在3月8日祝贺500个字符,并为安装塑料窗提供了15%的折扣。
今年,内容经理决定"作弊”,并且事不宜迟,找到了以前发布的带有折扣的新闻,将其复制,然后将折扣的大小从15%更改为12%,并通过额外的祝贺从自己身上添加了50个标志。
因此,最后我们有两个几乎完全相同的文本,其中90%相似,它们本身就是模糊重复,其中一个出于充分的理由需要紧急重写。
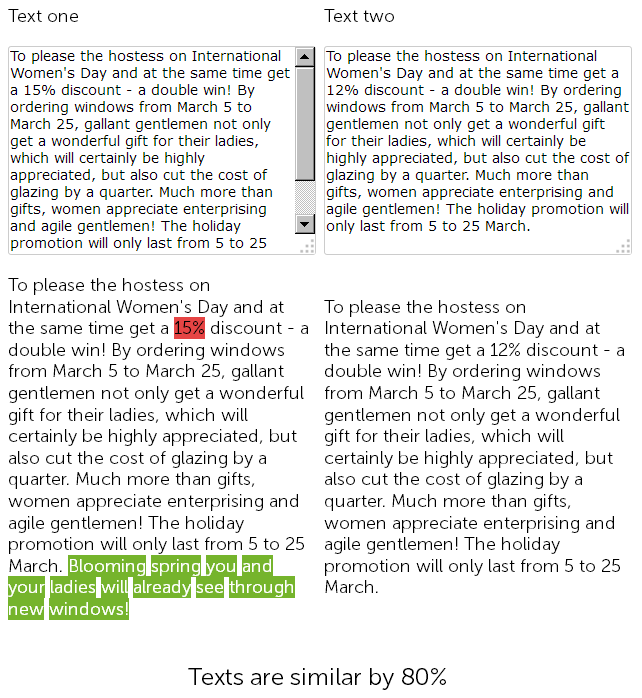
同时,对于技术审核服务,这两个消息将有所不同,因为已经配置了站点上的SEF,并且页面的校验和将不匹配,无论怎么说。
最后,哪个页面排名更好是一个大问题...
但是它们就是这样的新闻-它们往往很快就会过时,所以让我们举一个更有趣的例子。
例 2
您在您的网站上有一个文章板块,或维护一个或多个爱好的个人页面,例如,它是一个"烹饪博客”。
并且,例如,您的博客在整个时间内已经累积了超过100甚至数百个文章的顺序。因此,您选择了一个主题并撰写了一篇新文章,然后发表,后来以某种方式发现三年前已经写过一篇类似的文章。尽管看起来在编写内容之前,您已经浏览了所有标题,并打开了Excel,并列出了已发布的主题,但是并没有考虑到文章"如何在家中制作热巧克力”的过去内容与所写内容非常一致。而且,当在其中一项在线服务中查看这两篇文章时,发现它们之间的独特性为78%,这当然不好,因为由于部分重复,这些页面和搜索引擎之间的搜索查询之间存在自相残杀的关系。在对此类副本进行排名时会出现问题和困难。
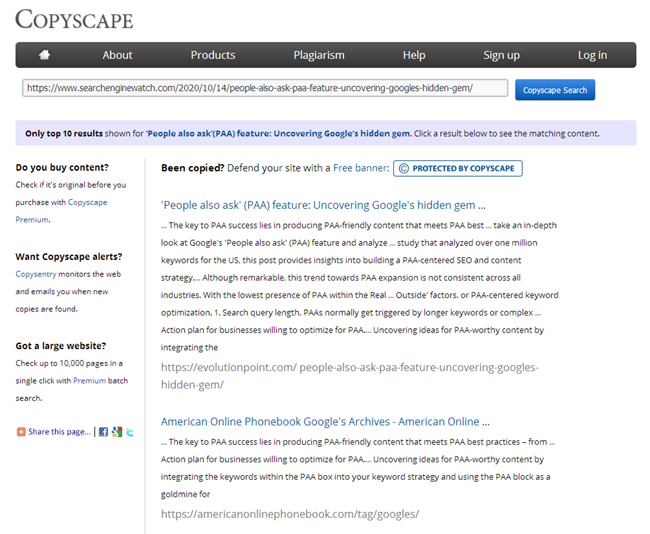
当然,写完文章后,每个撰稿人都必须在一项知名服务中检查其唯一性,并且每个SEO都有义务在网站上以相同服务发布时检查新内容。
但是,如果一个网站刚来找您进行推广并且您需要快速检查其所有页面是否重复,该怎么办?或者,在打开博客的曙光中,您写了一堆相同类型的文章,现在,很可能由于这些原因,该网站开始下陷。不要手动检查在线服务中的100,500页,而要手工检查每篇文章,并且要花费大量时间。
BatchUniqueChecker
这就是为什么我们创建了BatchUniqueChecker程序的原因,该程序旨在批量检查一组URL之间的唯一性。
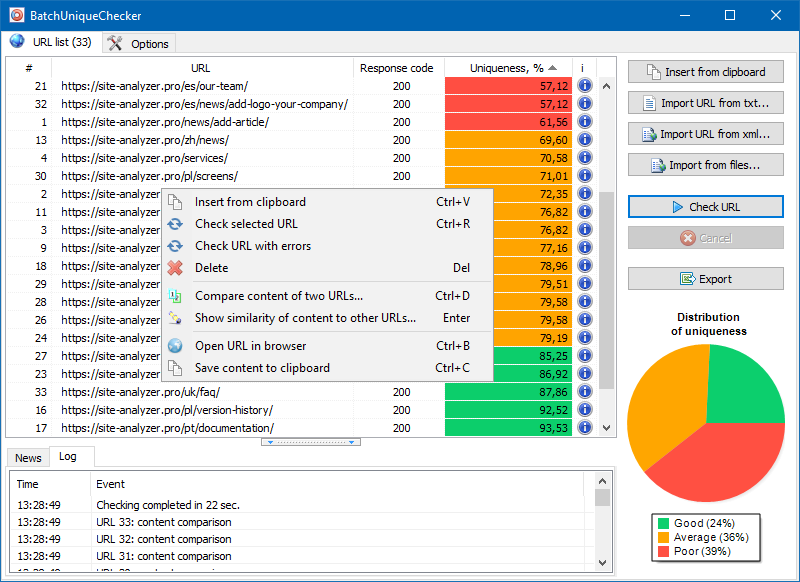
BatchUniqueChecker的操作原理很简单:程序使用预先准备的URL列表下载其内容,接收PlainText(无HEAD块且无HTML标记的页面的文本内容),然后使用带状疱疹算法将它们相互比较。
因此,使用带状疱疹,我们可以确定页面的唯一性,并且可以计算具有0%唯一性的页面的完整副本,以及具有不同程度的文本内容唯一性的部分副本。
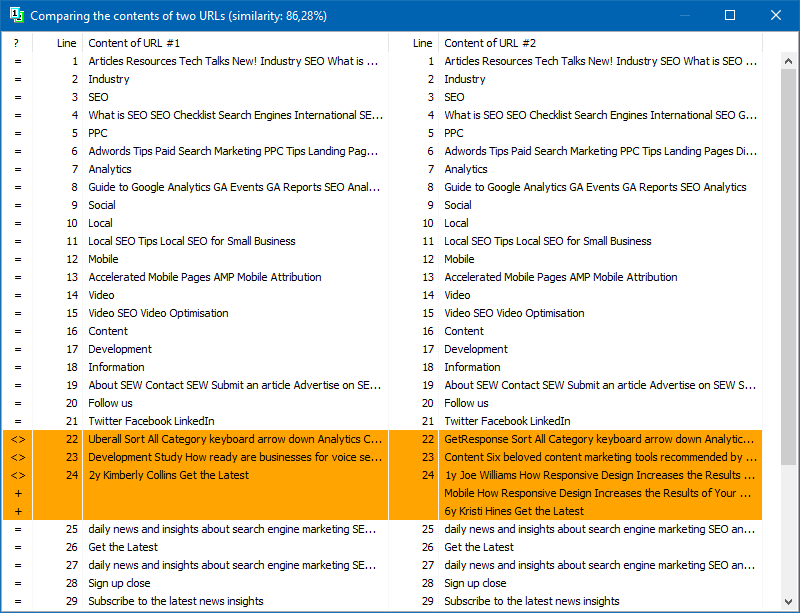
在程序设置中,您可以手动设置带状疱疹的大小(带状疱疹是文本中的单词数,其校验和与后面的组交替比较)。我们建议将值设置为4。对于5以上的大量文本。对于相对较小的体积-3-4。
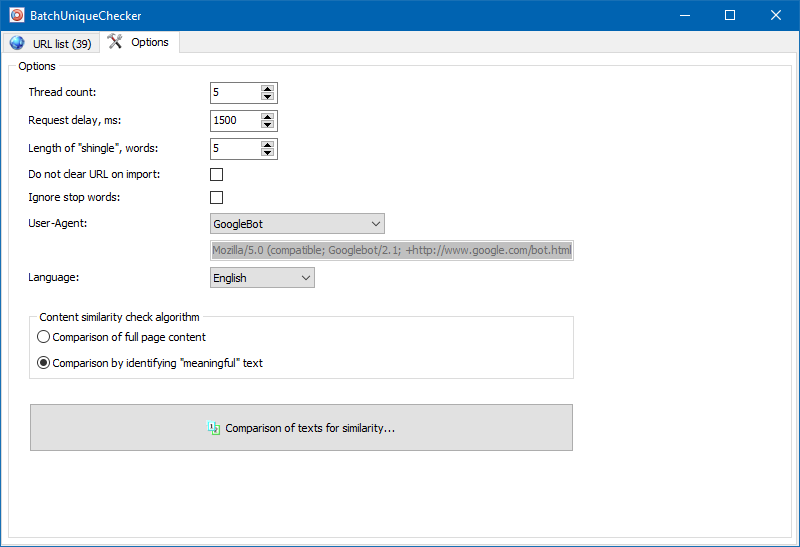
有意义的文字
除了内容的全文比较之外,该程序还包括用于"智能”隔离所谓"重要”文本的算法。
也就是说,从页面的HTML代码中,我们仅获得标签H1-H6,P,PRE和LI中包含的内容。因此,我们会舍弃所有"无关紧要”的内容,例如站点导航菜单中的内容,页脚或侧面菜单中的文本。
这种操作的结果是,我们仅获得"有意义的”页面内容,与之相比,该页面内容将显示与其他页面更准确的唯一性结果。
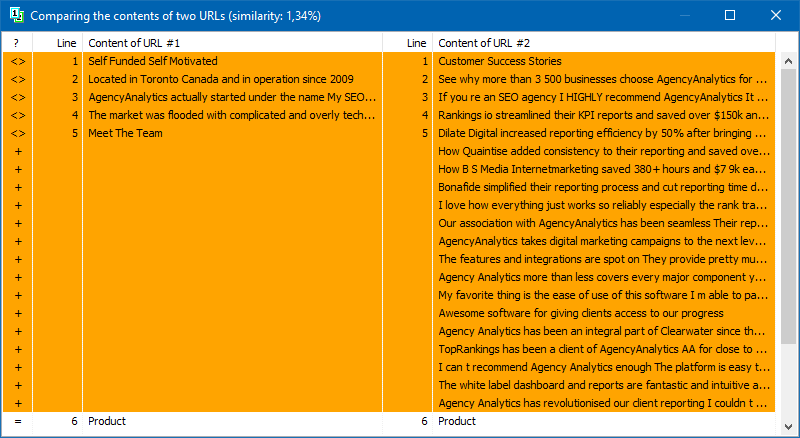
可以以几种方式添加用于后续分析的页面列表:从剪贴板粘贴,从文本文件加载或从计算机磁盘从Sitemap.xml导入。
由于程序的多线程操作,检查数百个或更多URL可能只需要几分钟,而在手动模式下,通过在线服务可能需要一天或更长的时间。
因此,您将获得一个简单的工具,可以快速检查一组URL的内容唯一性,甚至可以从可移动媒体上运行这些URL。
BatchUniqueChecker 它是免费的,存档中仅占用4 MB,并且不需要安装。
您只需要下载分发工具包并添加感兴趣的URL列表即可进行验证,可以通过免费的技术审核程序获得该列表。 SiteAnalyzer.

Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →



















