





















计划的目的
该程序SiteAnalyzer的目的是为了分析的网站并鉴别技术上的错误(搜索损坏的链接,重复网页,以不正确的服务器应对)的错误和遗漏SEO(空白元的标签,多余的或完全没有网页的标题h1,分析的页面内容、质量链接,以及许多其他搜索引擎优化参数)。

主要特点
- 扫描所有网页以及图像、脚本和文件
- 获得服务器回应代码,用于在网站的每个页面(200, 301, 302, 404, 500, 503 等等)。
- 确定存在和内容标题、关键词、描述、H1-H6
- 搜索和显示的"重复"的网页,元的标签和标题
- 确定存在的rel="典型"的每一页的网站
- 遵循文件“robots.txt”的指令,元標記“robots”或X-Robots-Tag
- 在抓取網站頁面時記帳“noindex”和“nofollow”
- 使用 XPath、CSS、XQuery、RegEx 抓取数据
- 检查网站内容的唯一性
- 通过 Google PageSpeed 检查页面加载速度
- 參考分析:網站任何頁面的內部和外部鏈接的定義
- 計算站點每個頁面的內部PageRank
- 圖上站點結構的可視化
- 確定頁面重定向的數量(重定向)
- 掃描任意URL和外部Sitemap.xml
- Sitemap“sitemap.xml”生成(可能分成幾個文件)
- 通過任何參數過濾數據(任何復雜度的過濾器的靈活配置)
- 在网站上搜索任意内容
- 出口报告中CSV和Excel(完整的报告以Excel格式)
不同于类似
- 低要求的计算机资源、低消耗的RAM
- 扫描站在几乎任何大小由于低要求的计算机资源
- 便携式格式(工作没有安装在电脑或直接从移动媒体)
部分的文件
- 工作的开始
- 该计划设置
- 基本的设置
- 扫描
- SEO
- 虚拟机器人.txt new
- Yandex XML
- User-Agent
- 任意 HTTP 标头 new
- 代理服务器
- 排除網址
- 關注網址
- PageRank
- 授权
- 工作与程序
- 代Sitemap.xml
- 扫描一个任意的URL
- Dashboard
- 出口数据
- 多语言
- 數據庫壓縮
工作的开始
当你开始的程序提供给用户的地址栏进入网址的分析网站(可以进入的网站的页面作为一个搜索机器人,链接的初始转的网站,包括主页,提供,所有链接都在HTML和不使用Javascript)。
之后按"开始"按钮,搜索引擎开始爬的所有网页或内部链接(外部资源,他不走,也不要求使用Javascript)。
一旦机器人将绕过所有网页变为可用的报告的形式提出一个表,显示收到的数据分组成的专题的标签。
所有分析的项目都显示在左侧的一部分的程序,并自动保存在数据库一起收到的数据。 删除网站,使用的上下文的菜单中的项目清单。
注意到:
- 当你点击按钮"暂停"扫描项目被暂停,并对目前的进展的扫描储存在一个数据库,从而允许例如关闭程序和继续扫描项目之后重新启动该程序。
- "停止"按钮中断扫描述当前项目不可能继续扫描
该计划设置
主菜单部分"设置"是用于精细的调整程序的工作与外部网站,包含7个标签:

节的主要设置是用于指定用户的指令时要使用扫描一个网站。
说明的参数:
- 数线
- 更多线程的数量,更多的网址将能够处理每单位时间。 应当指出的是,数量较多的线导致的更大数量的资源使用的电脑。 它建议设置的数量线范围为5-10。
- 扫描的时间
- 用于设置的限制扫描站的时间。 是衡量小时。
- 最大深度
- 此参数用于指定的深度扫描的网站。 该主页的网站具有一个嵌套的水平=0. 例如,如果您需要扫描页类型"somedomain.ru/catalog.html"和"somedomain.ru/catalog/tovar.html"在这种情况下,必须设置的最大深度=2.
- 之间的延迟请求
- 设置暂停,当呼吁的扫描仪的网页。 这是非常有用的网站与"弱"的主人,不承受沉重的负荷和频繁的呼吁。
- 超时的请求
- 设置时间超时的响应从该网站要求的程序。 如果任何这些网页的响应缓慢(漫长的货物),扫描站可能需要相当长的时间。 这些页面可以切断通过指定一个价值,其后该扫描仪进行扫描的其他网页的网站,因而不会拖延总体进展情况。
- 这些页的扫描
- 一个限制数量最大的网页的扫描。 是有用的,例如,如果您需要扫描的第N网页的网站(不包括图像、样式表脚本和其他类型的文件)。

考虑的内容
- 在本节你选择的数据类型将考虑通过分析程序,同时穿越页(图像、视频、样式脚本),或消除不必要信息的当分析。
扫描规则
- 这些设置相关的设置例外时爬这网站使用的文件扫描仪"robots.txt"链接类型的"希望",并且使用的指令"meta-name=的机器人"直接在你的代码页。

这一节指定的基本分析搜索引擎优化的因素,这在未来将被检验用于正在分析网页,其后得到的统计数据将显示在卡"搜索引擎优化统计数据"右侧的主要窗口。
借助這些設置,您可以選擇一項服務,通過該服務檢查搜索引擎Yandex中的頁面索引。檢查索引有兩種選擇:使用Yandex XML服務或Majento.ru服務。

選擇Yandex XML服務時,您需要考慮可能的限制(每小時或每天),這可以在檢查頁面索引時應用,關於您的Yandex帳戶的現有限制,因此通常會出現您的帳戶限制不足以檢查的情況一次一頁,你必須等待下一個小時。
使用Majento.ru服務時,實際上不存在每小時或每日限制,因為您的限製字面上合併到一般限制池中,這個限製本身並不小,但是與Yandex XML上的任何單個用戶帳戶相比,每小時限制具有更大的限制。 。

可以使用虚拟 robots.txt 代替网站上托管的真实 robots.txt。
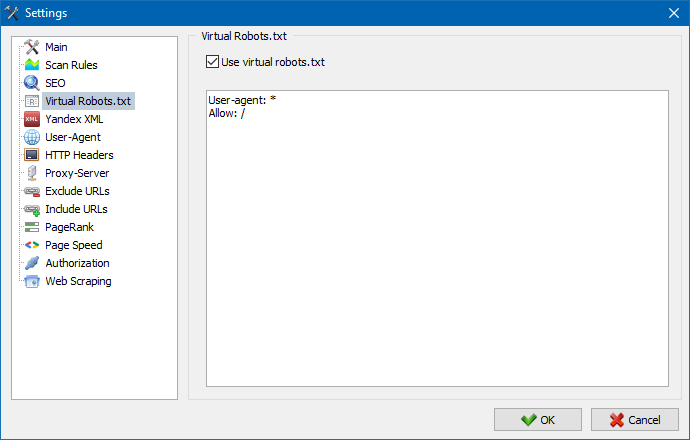
这在测试站点时很有用,例如,当您需要抓取站点中因索引而关闭的某些部分时(反之亦然 - 抓取时不要考虑它们),而您不需要物理地制作更改真实的 robots.txt 并花费开发人员的时间。
注意:导入 URL 列表时,会考虑虚拟 robots.txt 的指令(如果此选项已激活),否则 URL 列表中不考虑 robots.txt。
在部分用户的代理,你可以指定哪些用户代理将提交计划时访问外部网站在他们的扫描。 通过默认设置一个自定义用户的代理,但如果必要的话,你可以选择一个标准剂最经常遇到的互联网。 其中包括例如:机器人的搜索引擎YandexBot的,蜘蛛,MicrosoftEdge,机器人浏览器铬、火狐,IE8和移动设备的iPhone,安卓,和其他许多人。

使用此选项,您可以分析站点和页面对不同请求的反应。例如,有人可能需要在请求中发送一个 Referer,多语言站点的所有者想要传输 Accept-Language | Charset | Encoding,有人需要在 Accept-Encoding、Cache-Control、Pragma 标头中传输异常数据等 NS。
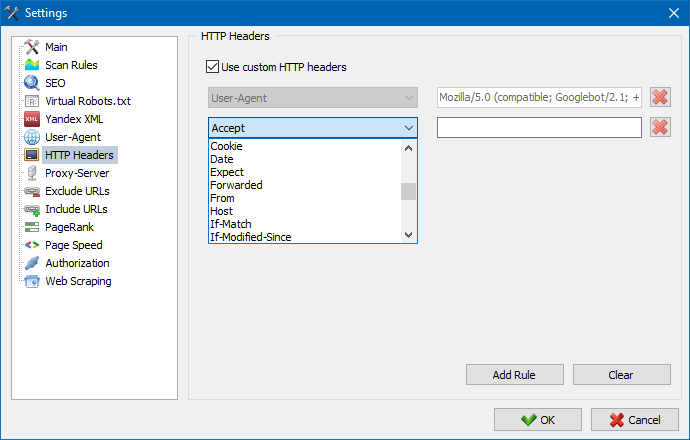
使用此选项,您可以分析站点和页面对不同请求的反应。例如,有人可能需要在请求中发送一个 Referer,多语言站点的所有者想要传输 Accept-Language | Charset | Encoding,有人需要在 Accept-Encoding、Cache-Control、Pragma 标头中传输异常数据等 NS。
如果有必要的工作,通过代理,在这一页你可以添加一个清单服务器代理通过该程序将访问外部资源。 此外,还有一种可能性,检查代理绩效,并且删除不活动的代理服务器。

这部分是旨在排除绕过某些网页和网站,当分析。
使用搜索模式*和? 您可以指定爬網程序不應爬網站點的哪些部分,因此不應包含在程序數據庫中。 这个名单是一个地方列出的例外扫描期间的网站(相对于他的"全球"列表是一个文件"robots.txt"在根本的网站)。

同樣,您可以添加必須抓取的網址。 在這種情況下,掃描期間將忽略這些文件夾之外的所有其他URL。 此選項也適用於搜索模式*和?

使用PageRank參數,您可以分析站點的導航結構,以及優化Web資源的內部鏈接系統,以便將參考權重傳輸到最重要的頁面。

該程序有兩個計算PageRank的選項:經典算法及其更現代的算法。通常,對於站點內部鏈接的分析,使用第一種或第二種算法時沒有太大區別,因此您可以使用這兩種算法中的任何一種。
有關算法的詳細說明和計算PageRank的原則,請參閱“內部PageRank的計算”一文: >>

在通過.htpasswd關閉並受BASIC服務器授權保護的頁面上輸入用於自動授權的登錄名和密碼。
工作与程序
扫描完成后,你会看到的信息包含在方框"掌握的数据"。 每个选项包含的数据进行分组方面,以他们的名字(例如,标签的标题中将包含的内容的页的标题,标题>和lt;/title>在标签上的"图像"列表显示的所有图像从网站等等)。 与这些数据,可以分析内容的网站,查找"破"链接的或不完整的元的标签。

如果有必要(例如,进行更改后的网站上)通过使用上下文的菜单有可能的新的扫描的个人网址,以反映变化中的程序。
使用这个菜单,你可以显示重复的页面的相关参数(双倍的标题,说明、关键词、h1,h2,内容页)。

項目“使用代碼0重新掃描URL”旨在自動仔細檢查所有給出響應代碼0(讀取超時)的頁面。 通常,當服務器沒有時間交付內容並且連接分別通過超時關閉,無法加載頁面並且無法從中提取信息時,通常會給出此響應代碼。
你可以现在选择这片显示,在该接口的主数据(最后成为可能说再见了过时的标签元关键词)。 这是有用的,当片不适合在屏幕上或很少使用它们。

列也可以隐藏或转移到想要的位置。
显示标签和列可使用的上下文的菜单上的工具条的主数据。 转移列进行通过。
为便于分析网站的统计数据,应用程序可以筛选数据。 过滤可能在两种变体:
- 对于任何字段,使用"快速"过滤器
- 使用一个定义过滤器(用的先进设置的样品数据)
快速的过滤器
用于快速筛选数据和同时施加的所有领域的当前的标签。

定义过滤器
设计用于广泛的筛选并且可以包含多个条件。 例如,对于元"标题"的标签要过滤网页,通过他们的长度,它不超过70个字符,并且也会包含的案文"新闻"。 然后这个过滤器,将是这样的:

因此,施加一个自定义过滤器的任何标签,你可以得到采样数据的任何复杂性。
該站點的技術統計選項卡位於“附加數據”面板上,包含一組基本站點技術參數:鏈接統計信息,元標記,頁面響應代碼,頁面索引參數,內容類型等。參數。
單擊其中一個參數,它們將在站點主數據的相應選項卡中自動過濾,同時統計信息顯示在頁面底部的圖表上。

SEO-statistics選項卡用於進行全面的站點審核,包含50多個主要的SEO參數,並識別超過60個關鍵的內部優化錯誤!錯誤映射分為多個組,而這些組又包含一組分析的參數和過濾器,用於檢測站點上的錯誤。
本文將詳細介紹所有已檢查的參數。 >>

對於所有過濾結果,可以快速將它們導出到Excel而無需其他對話(報告保存在程序文件夾中)。
在这个标签是预设的过滤器,允许您可以创建一个样本,为所有外部的链接,404错误、图像和其他参数的所有网页上,他们的存在。 所以,现在你可以很容易地和迅速获得名单的外部联系和网页上,他们的位置,或者选择的所有中断的链接和对网页上他们的位置。

所有报告均可在该方案在网上和上显示的"定义"标签的主板的数据。 此外,还有一种可能性的出口到使用Excel的主菜单。
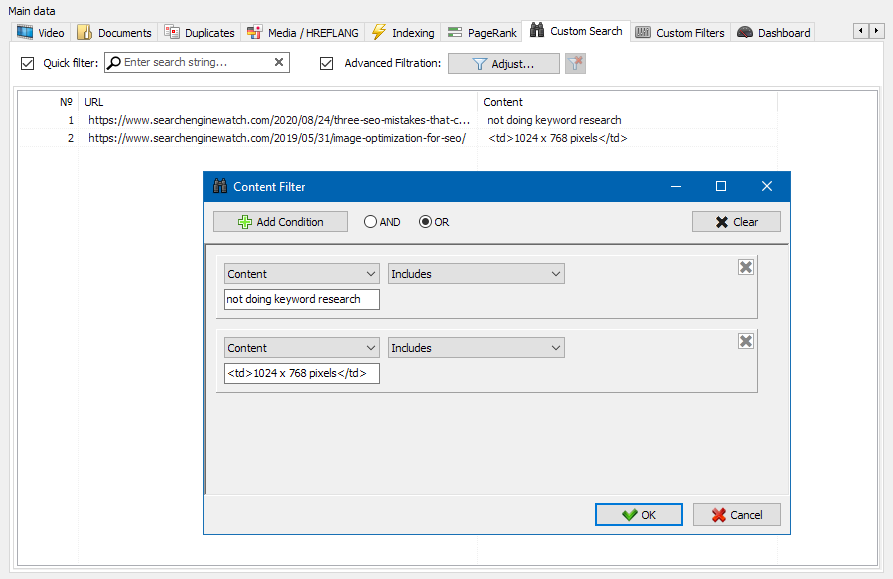
网站内容搜索功能使您可以搜索源代码,并显示包含所需内容的网页。
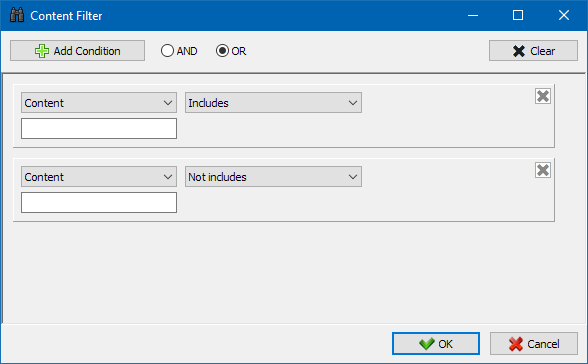
自定义过滤器模块使您可以检查网站上是否存在微标记,元标记,分析系统,自由文本或HTML代码的片段。
在过滤器配置窗口中,有几个参数用于搜索站点页面上的某些文本片段,或者相反,用于从搜索结果中排除包含某些文本或HTML代码片段的页面(此功能类似于使用Ctrl-F在页面的源代码中搜索内容) ...
通常,抓取用于解决难以手动处理的任务。这可以是提取产品描述以创建新的在线商店,抓取营销研究以监控价格或监控广告。

在 SiteAnalyzer 中,抓取是在数据提取选项卡上配置的,其中配置了提取规则。可以保存规则,并在必要时进行编辑。
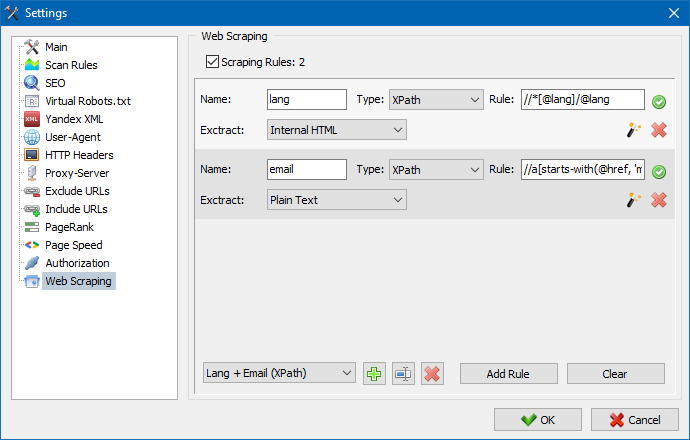
还有一个规则测试模块。使用内置的规则调试器,您可以快速轻松地获取站点上任何页面的HTML内容并测试查询的工作,然后使用调试后的规则在SiteAnalyzer中解析数据。

完成数据提取后,所有收集的信息都可以导出到Excel。
有关模块操作的更详细研究以及最常见规则和正则表达式的列表,请参阅文章
此工具允许您搜索重复页面并检查站点内文本的唯一性。换句话说,这是对一组 URL 之间的唯一性的批量检查。
这在以下情况下很有用:
- 搜索完整的重复页面(例如,具有参数的页面和相同的页面,但在 CNC 视图中)。
- 搜索部分内容匹配(例如,烹饪博客中的两个罗宋汤食谱,彼此相似度为 96%,这表明应删除其中一篇文章以摆脱可能的流量蚕食)。
- 在文章网站上,您不小心写了一篇关于您 10 年前已经写过的主题的文章。在这种情况下,我们的工具还将检测此类文章的副本。
检查内容唯一性的工具的原理很简单:程序从网站 URL 列表中下载它们的内容,接收页面的文本内容(没有 HEAD 块和 HTML 标签),然后将它们与每个其他使用shingle算法。

因此,使用带状疱疹,我们可以确定页面的唯一性,并且可以计算具有 0% 唯一性的页面的完全重复,以及具有不同程度的文本内容唯一性的部分重复。该程序使用长度为 5 的木瓦。
您可以在本文中了解有关该模块如何工作的更多信息。: >>
谷歌搜索巨头的 PageSpeed Insights 工具可以让你检查某些页面元素的加载速度,还可以显示桌面和移动版本浏览器感兴趣的 URL 的整体加载速度分数。

Google 的工具对每个人都有好处,但是,它有一个明显的缺点 - 它不允许您创建组 URL 检查,这在检查您网站的许多页面时会造成不便:同意手动检查 100 个或更多 URL 的下载速度一页是一件苦差事,可能需要很多时间。
因此,我们创建了一个模块,允许您通过 Google PageSpeed Insights 工具中的特殊 API 免费创建页面加载速度的组检查。

主要分析参数:
- FCP (First Contentful Paint) – 显示第一个内容的时间。
- SI (Speed Index) – 内容在页面上显示的速度的指示器。
- LCP (Largest Contentful Paint) – 页面上最大元素的显示时间。
- TTI (Time to Interactive) – 页面完全准备好进行用户交互的时间。
- TBT (Total Blocking Time) – 从第一次呈现内容到准备好进行用户交互的时间。
- CLS (Cumulative Layout Shift) – 累积布局偏移。用于衡量页面的视觉稳定性。
同时,只需单击几下即可对 URL 本身进行分析,然后可以下载报告,包括在 Excel 中以方便的形式检查的主要特征。
您需要开始的只是获取 API 密钥。
本文介绍了如何执行此操作。 >>
这一功能目的是创造一个网站结构的基础上获得的数据。 该网站的结构产生的嵌套的网址。 后产生的结构,其出口CSV格式(Excel)。

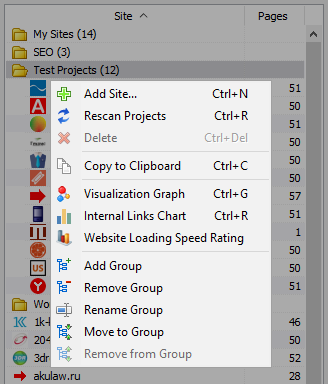
- 在该列表中的项目提供大规模的扫描通过选择所需的网站并点击"重新扫描"的。 在这之后,所有网站都在地方和被扫描交替在标准模式。
- 此外,为方便使用的程序、大量删除选择的地点也可用于"清除"按钮。
- 除了一个扫描站,有一个方法可以批量增加网站的项目列表中使用的一种特殊形式,然后,用户可以扫描有趣的项目作为一个整体。
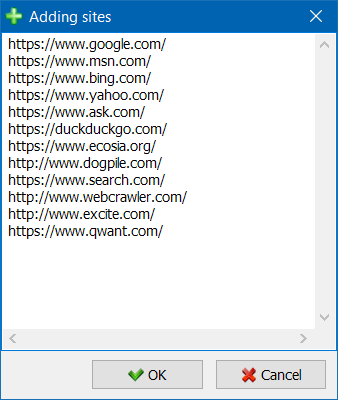
- 為了更方便地瀏覽項目列表,可以按文件夾對站點進行分組,以及按名稱過濾項目列表。

所呈现的模式的参考连接,该图将帮助你的搜索引擎优化专家评估的分配标在内部网页的网站,并了解哪些页面获得最大的链接,重量(因此,更多的内部链接汁眼中的搜索引擎),是什么网页和网站都没有足够的内部联系。

使用的呈现方式构的网站搜索引擎优化专家将能够评估如何有组织的内联网站上,并且还通过视表示Pr质量是分派给特定的网页,做出快速的调整目前的链接的网站,从而增加的相关性页。
在左侧的一部分可视化窗口的主要工具的图:
- 放在图形上
- 把图形成一个任意的角度
- 切换的图形窗口,在全屏幕模式(还按F11)
- 显示标签的节点 (Ctrl-T)
- 显示隐藏着的箭头从线
- 显示出隐藏的外部链接 (Ctrl-E)
- 换颜色方案的一天/夜 (Ctrl-D)
- 显示/隐藏传说和统计数据图表 (Ctrl-L)
- 保存有图在巴布亚新几内亚的格式 (Ctrl-S)
- 窗口的可视化的设置 (Ctrl-O)
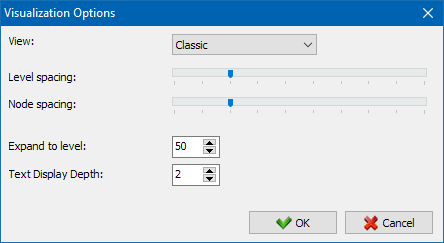
该部的"外观"改变的显示格式上的节点的曲线图。 在绘制模式的节点"排名",节点尺寸的设置是相对于他们先前计算出的指标,Pr,导致曲线图,可以清楚地看到哪些页面获得更多的链接汁,但是得到什么小的链接。
在典型模式中,节点尺寸的设置是相对于所选择的规模曲线的可视化。
此图显示了站点页面上内部链接质量的分布(我们可以说这是以可视形式显示的链接的可视化,而不是在可视化图上显示)。 阅读更多 >>
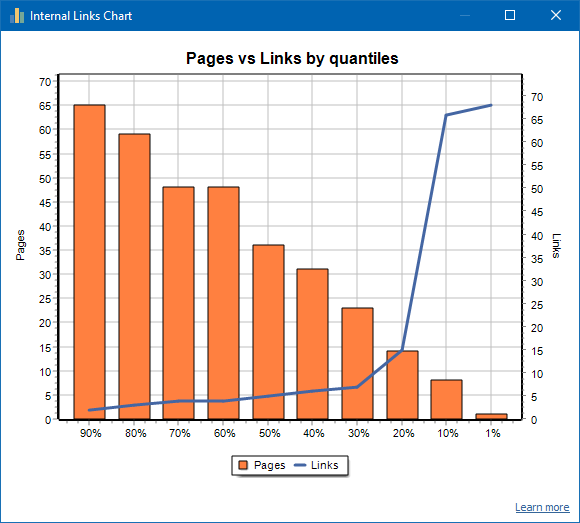
左边是页面数,右边是链接数。以下是按页面分位数的百分比。绘制图形时,重复的链接将被丢弃(如果从A页到B页有3个链接,则我们将它们视为一个)。
例如,根据上面的屏幕快照,对于约70页的网站:
- 1% 页面有 ~68 传入链接.
- 10% 页面有 ~66 传入链接.
- 20% 页面有 ~15 传入链接.
- 30% 页面有 ~8 传入链接.
- 40% 页面有 ~7 传入链接.
- 50% 页面有 ~6 传入链接.
- 60% 页面有 ~5 传入链接.
- 70% 页面有 ~5 传入链接.
- 80% 页面有 ~3 传入链接.
- 90% 页面有 ~2 传入链接.
也就是说,如果我们看到有少于10个入站链接指向的页面,则可以认为此类页面链接不牢固,并且通常有60%的页面链接。基于此,我们可以为这些链接薄弱的页面添加更多内部链接(如果这些页面对提升很重要),或者如果这些页面的重要性和优先级较低,则可以保持原样。
通常,内部链接少于10个的页面不太可能被搜索引擎机器人(尤其是Google机器人)抓取。
因此,如果您看到一个网站,通常只有该网站总数的20-30%的页面链接到该网站,则有必要深入研究链接设置或考虑如何处理80-70%的弱链接页面(删除,隐藏索引,放置重定向)。
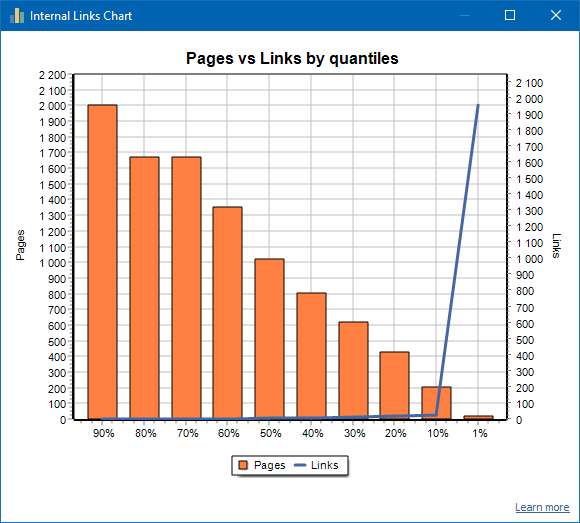
弱链接站点的示例:
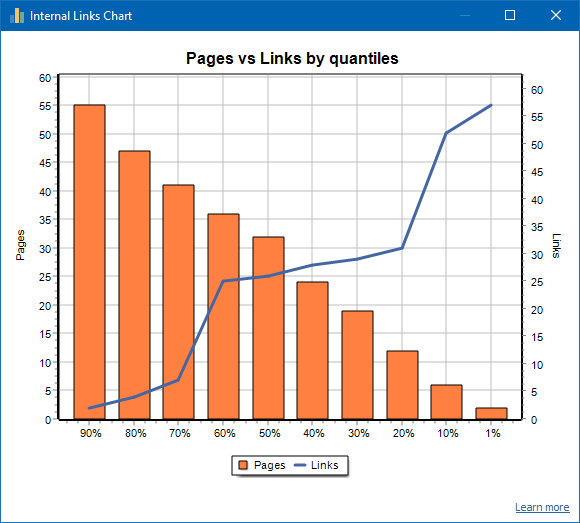
一个链接良好的网站的示例:
页面加载速度图使您可以评估站点的性能。为了清楚起见,将页面分为组和时间间隔,步长为100毫秒。
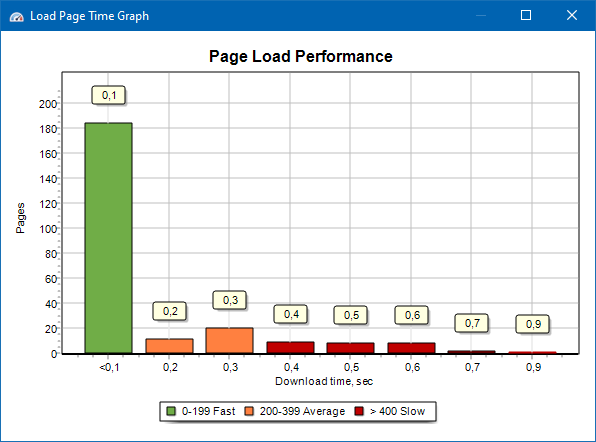
因此,基于该图,您可以确定快速(在0-100毫秒内)加载站点页面的比例,以平均速度(100-200毫秒)加载站点页面的时间以及加载足够长(400毫秒或更长时间)的页面。
注意:显示的时间是加载HTML源代码的时间,而不是完全加载页面的时间(不考虑页面渲染以及页面元素的加载,例如图像和样式)。
代Sitemap.xml
Sitemap是根据抓取的页面或网站图像生成的。
- 生成由页面组成的站点地图时,会将"文本/ html”格式的页面添加到其中。
- 生成包含图像的站点地图时,会向其中添加JPG,PNG,GIF和类似图像。
生成地图的网站后,立即扫描网站使用的主菜单项"的项目>网站地图产生的"。

网站有大量的50 000页自动划分的"sitemap.xml"在多个文件(在这种情况下,该文件包含链接到其他含有直接链接页面的网站)。 这是由于要求的搜索引擎对于处理网站地图的大尺寸。

如果有必要,数量页的文件"sitemap.xml"可以通过改变价值的50 000(默认)的期望值在主要程序的设置。
扫描一个任意的URL
菜单项目"进口URL"被设计用扫描任意列出的网址和XML网站地图Sitemap.xml (包括索引),用于以后分析。
扫描定义URL可能在三个方面:
- 通过插入清单的网址从剪贴板
- 启动时从硬盘格式的文件*.txt,并且*.xml的URL清单
- 通过下载的文件Sitemap.xml 直接从网站
这个模式是,当你扫描一个任意的URL"项目"是不存在的程序及其数据不是添加到数据库。 还不可用部分的"结构"和"仪表板".
了解更多有关该工作的选择"进网址的",在这篇文章: 概述的新版本 SiteAnalyzer 1.9.
Dashboard
仪表板签显示的详细报告关于目前的质量网站的优化。 该报告是基于产生数据的标签"搜索引擎优化统计数据的"。 除了这些数据报告中包含的指示总体质量指数化,计算出在100点的规模相对于目前程度的优化。 它可以导出的数据的标签"仪表板"在一个方便的PDF格式的报告。

出口数据
为更加灵活的数据的分析可供下载的CSV格式(出口到当前活动"标签"),以及产生一份完整的报告,以Microsoft Excel所有的标签,在一个文件。

当出口数据以Excel有一个特殊的窗口,用户可以从中选择所需的列,然后生成报告所需的数据。

多语言
该方案有选择优选用语文的工作。
主要的支持语言:俄语、英语、德语、意大利、西班牙、法国...目前,该软件已被翻译成超过十五(15)最受欢迎的语言。

如果你要翻译的程序,以自己的母语,只是翻译的文件"*的。天然气"你的语言,然后翻译的文件应送至该地址"support@site-analyzer.pro"(意见,信中必须写在俄语或英语),并翻译将包括在新释放的程序。
更详细的说明翻译成语言正在分发的文件("lcids.txt").
P.S.如果你有任何评论意见翻译质量发送评论和修正"support@site-analyzer.ru"上。
數據庫壓縮
主菜单项的"缩小数据库"的目的是为了操作的包装数据库(清洁数据库以前删除的项目,以及组织数据(类似的碎片的数据在个人计算机)项)。
这一程序是有效的情况下,例如,从该方案是删除了一个大型项目中含有大量的记录。 在一般情况下,建议进行定期压缩的数据,以摆脱的冗余数据和降低数据库的大小.
与回答其他问题可以发现的常见问题部分 >>



















