






















 1,799
1,799Питання визначення дублікатів сторінок і унікальності текстів всередині сайту є одним з найважливіших в списку робіт з технічного аудиту. Від наявності дублів сторінок залежить як загальне самопочуття сайту, так і розподіл краулінгового бюджету пошукових систем, можливо витрачається даремно, та й в цілому ранжування сайту може зазнавати труднощів через великої кількості дубльованого контенту.

І якщо для перевірки унікальності окремих текстів в інтернеті можна легко знайти велику кількість сервісів і програм, то для перевірки унікальності групи певних URL між собою подібних сервісів існує небагато, хоча сама по собі проблема є важливою і актуальною.
Які варіанти проблем з не унікальним контентом можуть бути на сайті?
1. Однаковий контент з різних URL.
Зазвичай це сторінка з параметрами і та ж сама сторінка, але у вигляді ЧПУ (людино-зрозумілий урл).
- приклад:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Це досить поширена проблема, коли після настройки ЧПУ, програміст забуває налаштувати 301 редирект зі сторінок з параметрами на сторінки з ЧПУ.
Дана проблема легко вирішується будь-яким веб-краулер, якій порівнявши всі сторінки сайту, виявить, що у двох з них однакові хеш-коди (MD5), і повідомить про це оптимізатора, якому залишиться поставити задачу, все того ж програмісту, на установку 301 редиректів на сторінки з ЧПУ.
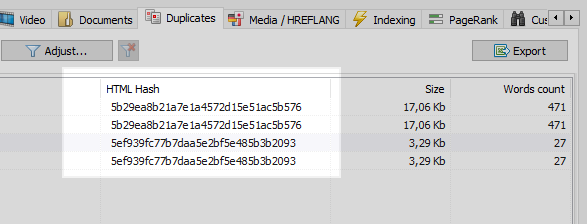
Однак не все буває так однозначно.
2. Частково збігається контент.
Подібний контент утворюється, коли ми маємо різні сторінки, але, по суті, з однаковим або схожим змістом.
приклад 1
На сайті з продажу пластикових вікон, в новинному розділі, копірайтер рік тому написав привітання з 8 березня на 500 знаків і дав знижку на установку пластикових вікон в 15%.
А в цьому році контент-менеджер вирішив "схалтурити", і не мудруючи лукаво, знайшов раніше розміщену новина зі знижками, скопіював її, і замінив розмір знижки з 15 на 12% + дописав від себе 50 знаків з додатковими вітаннями.
Таким чином, в результаті ми маємо два практично ідентичних тексту, схожих на 90%, які самі по собі є нечіткими дублікатами, одному з яких по хорошому потрібно терміновий рерайт.
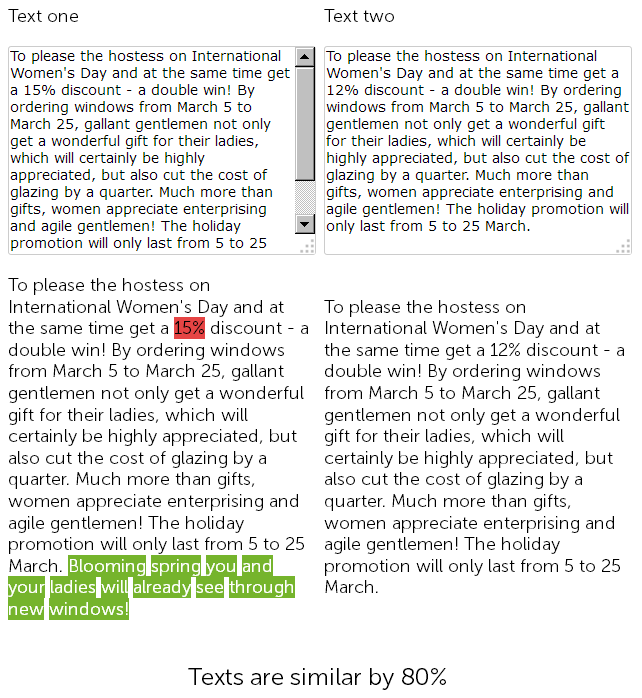
При цьому, для сервісів технічного аудиту дані дві новини будуть різними, так як ЧПУ на сайті вже налаштовані, і контрольні суми у сторінок не співпадуть, як не крути.
У підсумку, яка зі сторінок ранжируватиметься краще - велике питання ...
Але новини вони такі - мають властивість швидко застарівати, тому візьмемо приклад цікавіше.
приклад 2
У вас на сайті є статейний розділ, або ви ведете особисту сторінку за своїм хобі / захоплення, наприклад це "кулінарний блог".
І, наприклад, в вашому блозі набралося вже порядком статей за весь час, більше 100, а то і зовсім кілька сотень. І ось ви підібрали тему і написали нову статтю, розмістили, а згодом якимось чином виявилося, що аналогічна стаття вже була написана 3 роки тому. Хоча, здавалося б, перед написанням контенту ви пробіглися по всіх назв, відкрили Excel зі списком розміщених тим, але не врахували, що минуле вміст статті "Як приготувати гарячий шоколад в домашніх умовах" сильно збігається з тільки що написаним матеріалом. А при перевірці цих двох статей в одному з онлайн-сервісів виходить, що вони унікальні між собою на 78%, що, звичайно ж, не добре, так як через часткового дублювання виникає канібалізація пошукових запитів між цими сторінками, а у пошукової системи виникають питання і складнощі при ранжируванні подібних дублів.
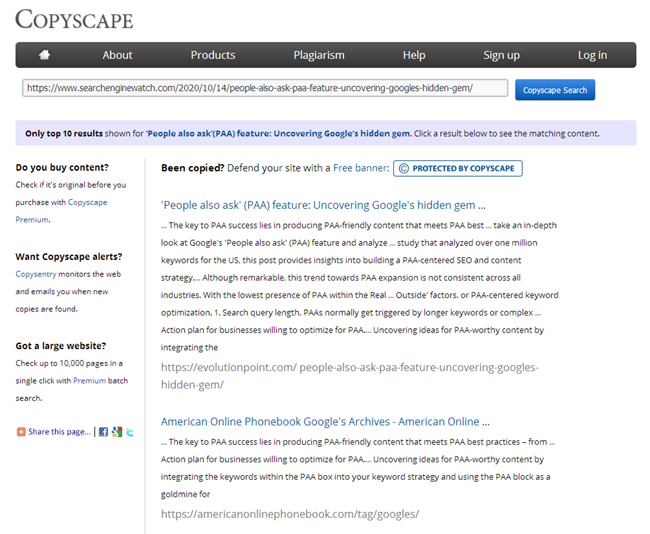
Само собою, кожен копірайтер після написання статті повинен перевіряти її на унікальність в одному з відомих сервісів, а кожен сеошник зобов'язаний перевіряти новий контент при розміщенні на сайті в тих же сервісах.
Але, що робити, якщо до вас тільки-тільки прийшов сайт на просування і вам потрібно оперативно перевірити всі його сторінки на дублі? Або, на зорі відкриття свого блогу ви написали купу однотипних статей, а тепер, швидше за все через них сайт почав просідати. Чи не перевіряти ж руками 100500 сторінок в онлайн сервісах, додаючи на перевірку кожну статтю руками і витрачаючи на це багато часу.
BatchUniqueChecker
Саме для цього ми і створили програму BatchUniqueChecker, призначену для пакетної перевірки групи URL на унікальність між собою.
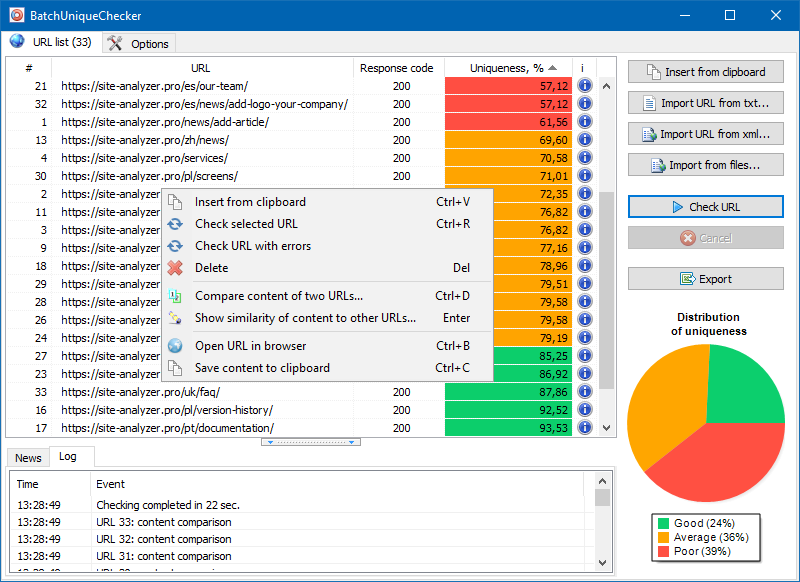
Принцип роботи BatchUniqueChecker простий: за заздалегідь підготовленим списком URL програма завантажує їх вміст, отримує PlainText (текстовий вміст сторінки без блоку HEAD і без HTML-тегів), а потім за допомогою алгоритму шинглів порівнює їх один з одним.
Таким чином, за допомогою шинглів ми визначаємо унікальність сторінок і можемо обчислити як повні дублі сторінок з 0% унікальністю, так і часткові дублі з різними ступенями унікальності текстового вмісту.
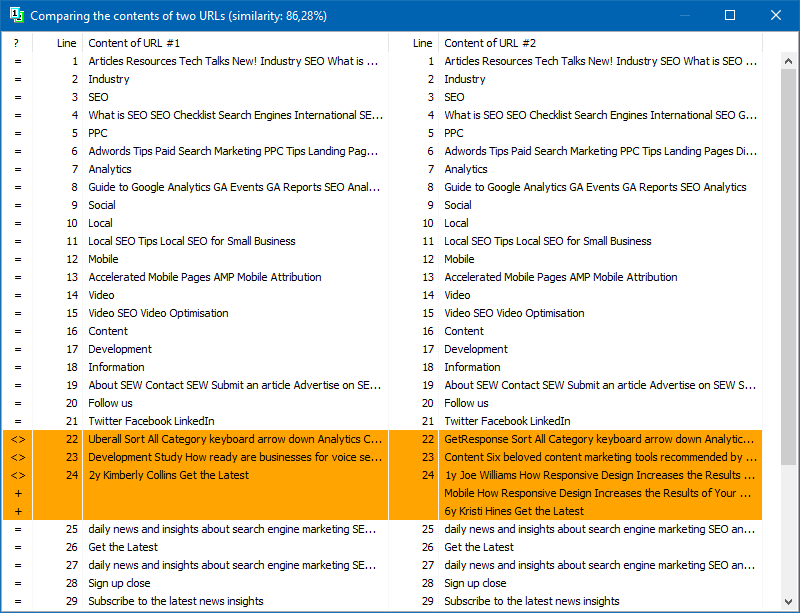
У налаштуваннях програми є можливість ручного регулювання розміру шингли (шингл - це кількість слів у тексті, контрольна сума яких поперемінно порівнюється з подальшими групами). Ми рекомендуємо встановити значення = 4. Для великих обсягів тексту від 5 і вище. Для відносно невеликих обсягів - 3-4.
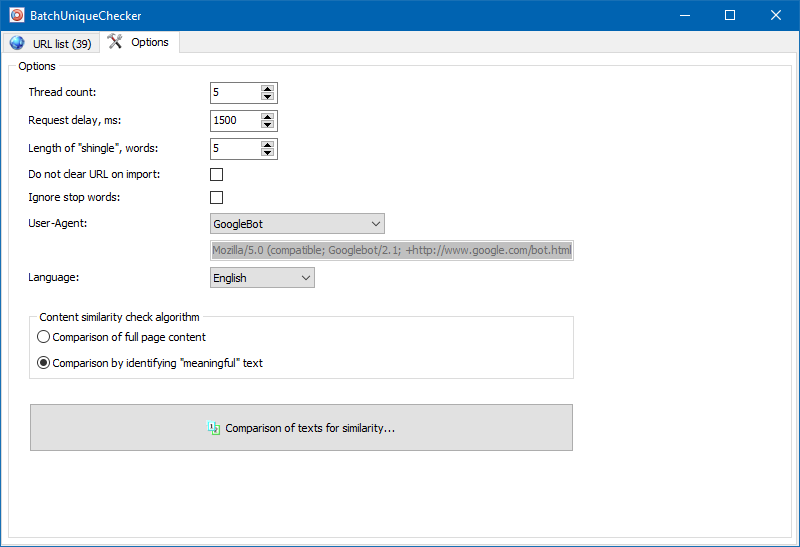
значні тексти
Крім повнотекстового порівняння контенту, в програму закладено алгоритм "розумного" виокремлення так званих "значущих" текстів.
Тобто, з HTML-коду сторінки ми отримуємо тільки контент, що міститься в тегах H1-H6, P, PRE і LI. За рахунок цього ми як би відкидаємо все »не значуще", наприклад, контент з меню навігації сайтів, текст з футера або бокового меню.
В результаті подібних маніпуляцій ми отримуємо тільки "значимий" контент сторінок, який при порівнянні покаже більш точні результати унікальності з іншими сторінками.
Список сторінок для їх подальшого аналізу можна додати кількома способами: вставити з буфера обміну, завантажити з текстового файлу, або імпортувати з Sitemap.xml з диска вашого комп'ютера.
Завдяки многопоточной роботі програми, перевірка сотні і більше URL може зайняти всього декілька хвилин, на що в ручному режимі, через онлайн-сервіси, міг би піти день або більше.
Таким чином, ви отримуєте простий інструмент для оперативної перевірки унікальності контенту для групи URL, який можна запускати навіть зі змінного носія.
BatchUniqueChecker безкоштовна, займає всього 4 Мб в архіві і не вимагає установки.
Все що необхідно для початку роботи - завантажити дистрибутив і додати на перевірку списку відповідних URL, які можна отримати через безкоштовну програму технічного аудиту SiteAnalyzer.
Iнші статті



















