






















 3,631
3,631La questione della determinazione delle pagine duplicate e dell'unicità dei testi all'interno del sito è una delle più importanti nell'elenco dei lavori di revisione tecnica. La presenza di pagine duplicate determina sia il benessere generale del sito che la distribuzione del budget di crawling del motore di ricerca, che può andare sprecato, e in generale il posizionamento del sito può incontrare difficoltà a causa dell'elevata quantità di contenuti duplicati.

E se riesci a trovare facilmente un gran numero di servizi e programmi per verificare l'unicità dei singoli testi su Internet, allora non ci sono molti servizi simili per verificare l'unicità di un gruppo di URL specifici tra di loro, sebbene il problema stesso sia importante e rilevante.
Quali opzioni per problemi con contenuti non univoci possono essere presenti nel sito?
1. Stesso contenuto per URL diversi.
Di solito questa è una pagina con parametri e la stessa pagina, ma nella forma di un SEF (URL leggibile dall'uomo).
- Esempio:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Questo è un problema abbastanza comune quando, dopo aver impostato il SEF, il programmatore si dimentica di impostare un reindirizzamento 301 da pagine con parametri a pagine con SEF.
Questo problema può essere facilmente risolto da qualsiasi web crawler, il quale, confrontando tutte le pagine del sito, scoprirà che due di esse hanno gli stessi codici hash (MD5), e informerà l'ottimizzatore, che dovrà impostare il task, lo stesso programmatore, di installare i redirect 301 alle pagine del SEF.
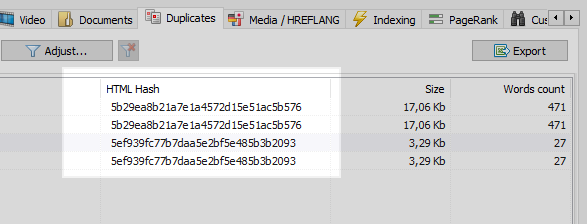
Tuttavia, non tutto è così semplice.
2. Contenuti sovrapposti.
Contenuti simili vengono generati quando abbiamo pagine diverse, ma, di fatto, con contenuto uguale o simile.
Esempio 1
Sul sito web per la vendita di finestre di plastica, nella sezione notizie, un anno fa un copywriter ha scritto una congratulazione l'8 marzo per 500 caratteri e ha concesso uno sconto del 15% sull'installazione di finestre di plastica.
E quest'anno, il gestore dei contenuti ha deciso di "barare" e, senza ulteriori indugi, ha trovato le notizie precedentemente pubblicate con sconti, le ha copiate e ha cambiato la dimensione dello sconto dal 15 al 12% + ha aggiunto 50 segni da se stesso con ulteriori congratulazioni.
Così, alla fine, abbiamo due testi quasi identici, simili al 90%, che di per sé sono duplicati sfocati, uno dei quali, per una buona ragione, richiede una riscrittura urgente.
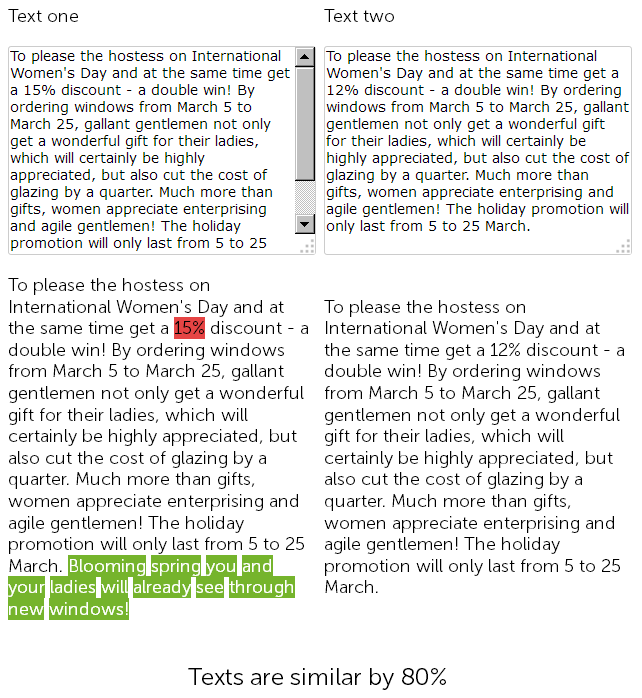
Allo stesso tempo, per i servizi di audit tecnico, queste due novità saranno diverse, poiché il SEF è già configurato sul sito, e le checksum delle pagine non coincideranno, qualunque cosa si dica.
Alla fine, quale pagina si classificherà meglio è una grande domanda ...
Ma sono una notizia del genere: tendono a diventare obsolete rapidamente, quindi facciamo un esempio più interessante.
Esempio 2
Hai una sezione di articoli sul tuo sito, o mantieni una pagina personale per il tuo hobby / hobby, ad esempio, è un "blog culinario".
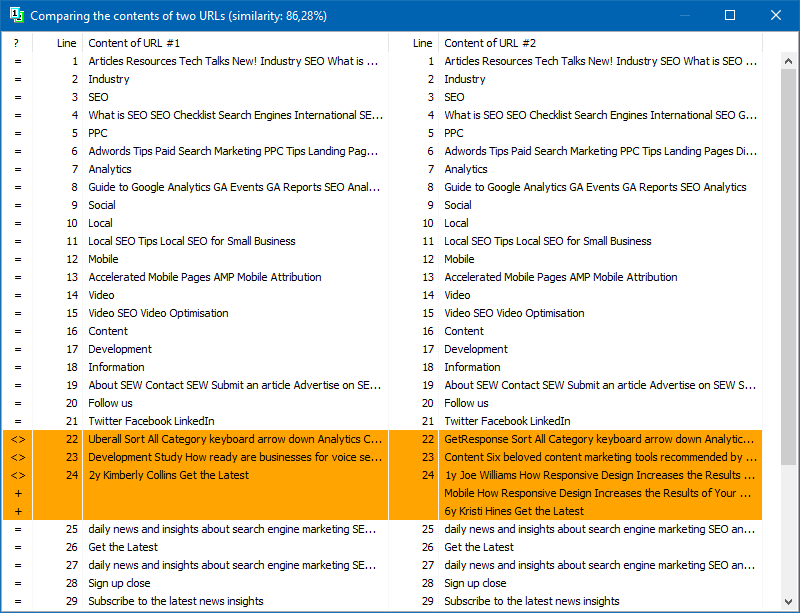
E, ad esempio, il tuo blog ha già accumulato un ordine di articoli per tutto il tempo, più di 100 o anche diverse centinaia. E così hai scelto un argomento e hai scritto un nuovo articolo, lo hai pubblicato e in seguito hai scoperto in qualche modo che un articolo simile era già stato scritto 3 anni fa. Anche se sembrerebbe che prima di scrivere il contenuto tu abbia passato in rassegna tutti i titoli, aperto Excel con un elenco di argomenti postati, ma non hai tenuto conto che il contenuto passato dell'articolo "Come fare la cioccolata calda in casa" coincide fortemente con il materiale appena scritto. E controllando questi due articoli in uno dei servizi online, si scopre che sono unici al 78% tra di loro, il che, ovviamente, non va bene, poiché a causa della duplicazione parziale c'è una cannibalizzazione delle query di ricerca tra queste pagine e il motore di ricerca sorgono domande e difficoltà quando si classificano tali duplicati.
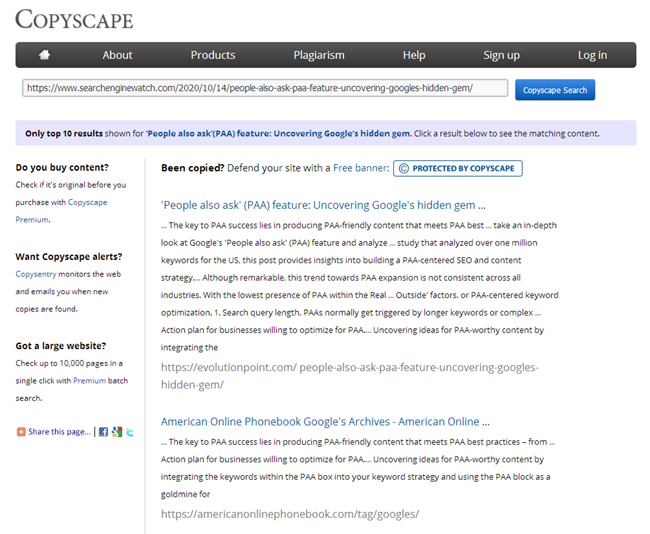
Naturalmente, dopo aver scritto un articolo, ogni copywriter deve verificarne l'unicità in uno dei servizi ben noti, e ogni SEO è obbligato a controllare i nuovi contenuti quando pubblicati sul sito negli stessi servizi.
Ma cosa fare se un sito Web è appena arrivato da te per la promozione e devi controllare rapidamente tutte le sue pagine per i duplicati? Oppure, all'alba dell'apertura del tuo blog, hai scritto un sacco di articoli dello stesso tipo e ora, molto probabilmente, a causa loro, il sito ha iniziato a cedere. Non controllare manualmente 100.500 pagine nei servizi online, aggiungendo per controllare ogni articolo a mano e dedicando molto tempo ad esso.
BatchUniqueChecker
Ecco perché abbiamo creato il programma BatchUniqueChecker, progettato per controllare in batch un gruppo di URL per l'unicità tra di loro.
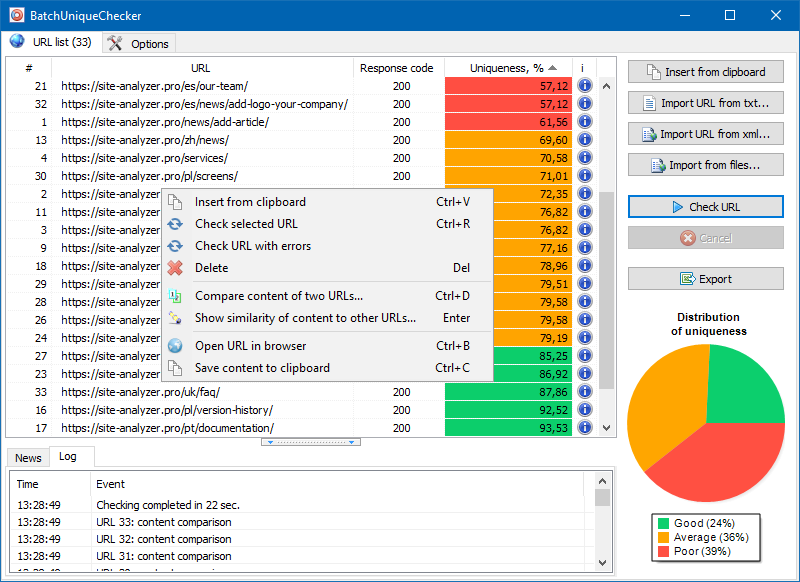
Il principio di funzionamento di BatchUniqueChecker è semplice: il programma scarica il loro contenuto utilizzando un elenco di URL precedentemente preparato, riceve PlainText (il contenuto di testo della pagina senza un blocco HEAD e senza tag HTML), quindi li confronta tra loro utilizzando l'algoritmo di scandole.
Pertanto, utilizzando l'herpes zoster, determiniamo l'unicità delle pagine e possiamo calcolare sia i duplicati completi delle pagine con 0% di unicità, sia i duplicati parziali con vari gradi di unicità del contenuto del testo.
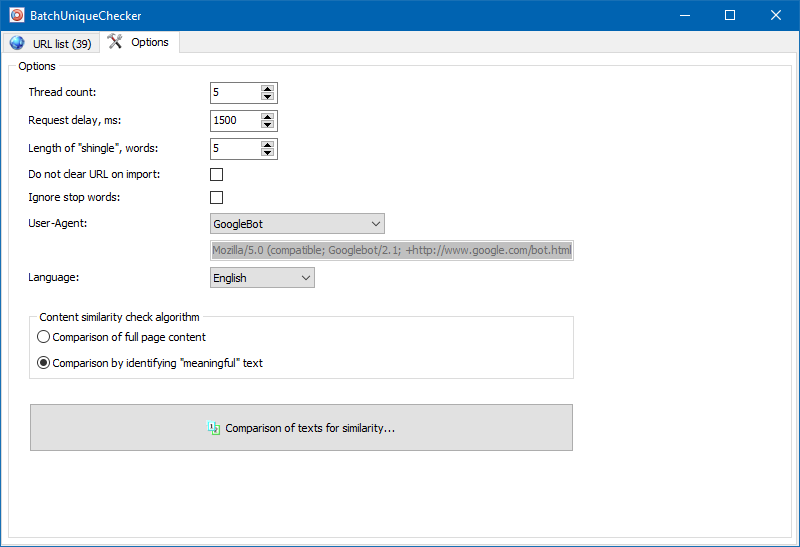
Nelle impostazioni del programma, è possibile impostare manualmente la dimensione della tegola (tegola è il numero di parole nel testo, il cui checksum viene confrontato alternativamente con i gruppi successivi). Si consiglia di impostare il valore = 4. Per grandi quantità di testo da 5 in su. Per volumi relativamente piccoli - 3-4.
Testi significativi
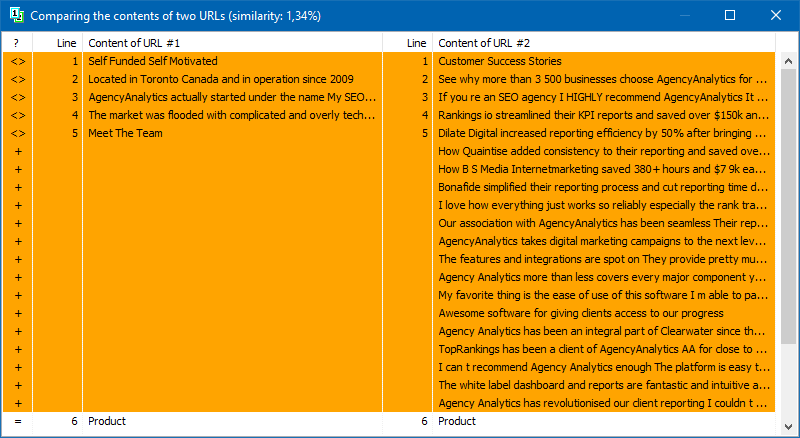
Oltre al confronto full-text dei contenuti, il programma include un algoritmo per l'isolamento "intelligente" dei testi cosiddetti "significativi".
Cioè, dal codice HTML della pagina riceviamo solo il contenuto contenuto nei tag H1-H6, P, PRE e LI. Per questo motivo, scartiamo tutto ciò che è "non significativo", ad esempio, il contenuto dal menu di navigazione del sito, il testo dal piè di pagina o dal menu laterale.
Come risultato di tali manipolazioni, otteniamo solo contenuti di pagina "significativi", che, se confrontati, mostreranno risultati di unicità più accurati con altre pagine.
L'elenco delle pagine per la loro successiva analisi può essere aggiunto in diversi modi: incollare dagli appunti, caricare da un file di testo o importare da Sitemap.xml dal disco del computer.
A causa del funzionamento multithread del programma, il controllo di centinaia o più URL può richiedere solo pochi minuti, che in modalità manuale, tramite servizi online, potrebbero richiedere un giorno o più.
In questo modo, ottieni un semplice strumento per controllare rapidamente l'unicità del contenuto per un gruppo di URL, che può essere eseguito anche da un supporto rimovibile.
BatchUniqueChecker è gratuito, richiede solo 4 MB di archivio e non richiede installazione.
Tutto ciò che serve per iniziare è scaricare il kit di distribuzione e aggiungere un elenco di URL di interesse per la verifica, che può essere ottenuto tramite un programma di audit tecnico gratuito SiteAnalyzer.

Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Altri articoli



















