





















Lo scopo del programma
Il programma SiteAnalyzer è stato progettato per l'analisi del sito e individuare errori tecnici (ricerca di collegamenti interrotti, di pagine duplicate, errate risposte del server), ma anche di errori e omissioni nell'ottimizzazione SEO (vacanti meta-tag, in eccesso o in totale assenza di titoli delle pagine h1, l'analisi del contenuto di una pagina, la qualità di ricollegare e numerosi altri parametri SEO).

Caratteristiche principali
- La scansione di tutte le pagine del sito, ma anche di immagini, script e documenti
- Come ottenere i codici di risposta del server per ogni pagina del sito (200, 301, 302, 404, 500, 503 ecc)
- La determinazione della presenza e del contenuto Title, Keywords, Description, H1-H6
- La ricerca e la visualizzazione di "duplicati" pagine, meta-tag e titoli
- La definizione della presenza dell'attributo rel="canonical" per ogni pagina del sito
- Seguendo le direttive del file "robots.txt", il meta tag "robots", o X-Robots-Tag
- Contabilità "noindex" e "nofollow" durante la scansione delle pagine del sito
- Raschiare i dati con XPath, CSS, XQuery, RegEx
- Verifica dell'unicità dei contenuti all'interno del sito
- Controllo della velocità di caricamento della pagina tramite Google PageSpeed
- Analisi di riferimento: la definizione di collegamenti interni ed esterni per qualsiasi pagina del sito
- Calcolo del PageRank interno per ogni pagina del sito
- Visualizzazione della struttura del sito sul grafico
- Determinazione del numero di reindirizzamenti dalla pagina (reindirizzamenti)
- Scansiona URL arbitrari e Sitemap.xml esterni
- Generazione Sitemap "Sitemap.xml" (con la possibilità di suddividere in più file)
- Filtraggio dei dati in base a qualsiasi parametro (configurazione flessibile di filtri di qualsiasi complessità)
- Cerca contenuti arbitrari sul sito
- Esportazione dei report in formato CSV, Excel e PDF
Le differenze da analoghi
- Bassi requisiti di risorse del computer, piccolo consumo di ram
- La scansione di siti quasi qualsiasi quantità a causa di bassi requisiti di risorse del computer
- Formato portatile (funziona senza installazione sul PC o direttamente da un supporto removibile)
La documentazione
- L'inizio del lavoro
- Le impostazioni del programma
- Impostazioni di base
- La scansione
- SEO
- Robot virtuali.txt new
- Yandex XML
- User-Agent
- Intestazioni HTTP arbitrarie new
- Proxy-server
- Escludi URL
- Segui URL
- PageRank
- Autorizzazione
- Il lavoro con il programma
- Personalizzazione delle colonne e delle schede
- Filtraggio dei dati
- Statistiche del sito tecnico
- Statistiche SEO
- Custom Filters
- Custom Search
- Raschiamento dei dati
- Controllo dell'unicità dei contenuti
- Controllo della velocità di caricamento della pagina
- La struttura del sito
- Il menu di scelta rapida elenco dei progetti
- Visualizzazione della struttura del sito Web
- Grafico distribuzione link interni
- Grafico della velocità di caricamento della pagina
- Generazione Sitemap.xml
- La scansione arbitrarie URL
- Dashboard
- Esportazione dei dati
- Multilanguage
- Compressione del database
L'inizio del lavoro
Quando si esegue il programma, l'utente è disponibile la barra degli indirizzi per l'inserimento di un URL analizzato sito (è possibile inserire qualsiasi pagina del sito, così come il robot di ricerca, cliccando sul link della pagina di origine bypassare l'intero sito, tra cui la home page, a condizione che tutti i collegamenti sono realizzati in HTML e non utilizzano Javascript).
Dopo aver premuto il pulsante "Start", il robot di ricerca inizia la ricerca per indicizzazione di tutte le pagine del sito web per link interni (risorse esterne non va, inoltre, non va il link, realizzato in Javascript).
Dopo che, come un robot escluderà tutte le pagine del sito è disponibile il rapporto, realizzato in forma di tabella e visualizzare i dati ottenuti, raggruppati per tematiche schede.
Tutti analizzati i progetti vengono visualizzati nella parte sinistra del programma e vengono automaticamente salvati nel database del programma insieme con i dati ricevuti. Per eliminare i siti, utilizzare il menu di scelta rapida di un elenco di progetti.
Nota:
- quando si fa clic sul pulsante "Pausa" scansione progetto è sospeso, in parallelo, l'attuale stato di avanzamento della scansione viene salvato nel database, che consente, ad esempio, chiudere il programma e continuare la scansione del progetto dopo il riavvio del programma.
- il pulsante "Stop" interrompe la scansione del progetto corrente, senza la possibilità di continuare la sua scansione
Le impostazioni del programma
La sezione del menu principale "Impostazioni" è stato progettato per le impostazioni del programma con siti esterni e contiene 7 schede:

La sezione delle impostazioni di base serve per specificare un programma personalizzato delle linee guida utilizzati quando si esegue la scansione del sito.
Descrizione delle opzioni:
- Il numero di thread
- Maggiore è il numero di thread, più l'URL sarà in grado di trattare nell'unità di tempo. Per questo è necessario considerare che un numero crescente di flussi conduce ad un maggior numero di risorse del PC. Si consiglia di impostare il numero di thread in un intervallo di 5-10.
- Il tempo di scansione
- Serve per impostare i limiti di scansione del sito da tempo. È misurato in ore.
- La profondità massima
- Questo parametro consente di specificare la profondità di scansione del sito. La pagina principale del sito ha un livello di nidificazione = 0. Ad esempio, se si desidera eseguire la scansione di una pagina del sito della specie "somedomain.ru/catalog.html" e "somedomain.ru/catalog/tovar.html" allora in questo caso è necessario esporre la profondità massima = 2.
- Il ritardo tra le richieste
- Serve per l'installazione pause richieste di scanner alle pagine del sito. Questo è necessario per i siti su "deboli" hosting gratuito, non sopportare grandi carichi e frequenti a loro casi.
- Il timeout di query
- Impostazione del tempo di attesa della risposta di sito su richiesta del programma. Se alcune pagine del sito rispondono lentamente (lungo caricati), quindi eseguire la scansione del sito può richiedere molto tempo. Queste pagine si possono accorciare, specificando il valore, dopo di che, lo scanner per la scansione le altre pagine del sito e quindi non ritardare il progresso comune.
- Il numero di scansione delle pagine del sito
- Limitazione sul numero massimo di immagini scansionate. È utile se, ad esempio, è necessario analizzare i primi N pagine del sito (in questo caso non contano le immagini, i fogli di stile, script e altri tipi di file).

In considerazione dei contenuti
- In questa sezione è possibile selezionare i tipi di dati che saranno conteggiati un analizzatore durante la ricerca per indicizzazione di pagine (immagini, video, gli stili, gli script), o eliminare l'eccesso di informazioni nel parsing di numeri in.
Le regole di scansione
- I dati di configurazione associati con le impostazioni di eccezione durante la ricerca per indicizzazione del sito сканнером utilizzando il file di "robots.txt" per i link di tipo "nofollow", ma anche utilizzando le linee guida di "meta name=robots" direttamente nel codice delle pagine del sito.

Questa sezione serve per specificare le principali analizzati i parametri SEO, che in futuro verrà verificata la correttezza nel parsing di numeri in pagine, dopo di che le statistiche verranno visualizzate nella scheda "Statistiche SEO" nella parte destra della finestra principale del programma.
Con l'aiuto di queste impostazioni, puoi scegliere un servizio attraverso il quale controllerai l'indicizzazione delle pagine nel motore di ricerca Yandex. Esistono due opzioni per il controllo dell'indicizzazione: utilizzando il servizio XML Yandex o il servizio Majento.ru.

Quando si sceglie il servizio Yandex XML, è necessario tenere conto delle possibili restrizioni (orarie o giornaliere), che possono essere applicate quando si controlla l'indicizzazione delle pagine, riguardo ai limiti esistenti sul proprio account Yandex, in conseguenza delle quali spesso possono verificarsi situazioni in cui i limiti del proprio account non saranno sufficienti per controllare tutti pagine alla volta e per questo devi aspettare l'ora successiva.
Quando si utilizza il servizio Majento.ru, le restrizioni orarie o giornaliere sono praticamente assenti, poiché il limite si confonde letteralmente nel pool generale di limiti, che non è di per sé limitato, ma ha anche un limite significativamente più grande con restrizioni orarie rispetto a qualsiasi account utente individuale su XML Yandex.

È possibile utilizzare il file robots.txt virtuale al posto del file robots.txt reale ospitato sul sito.
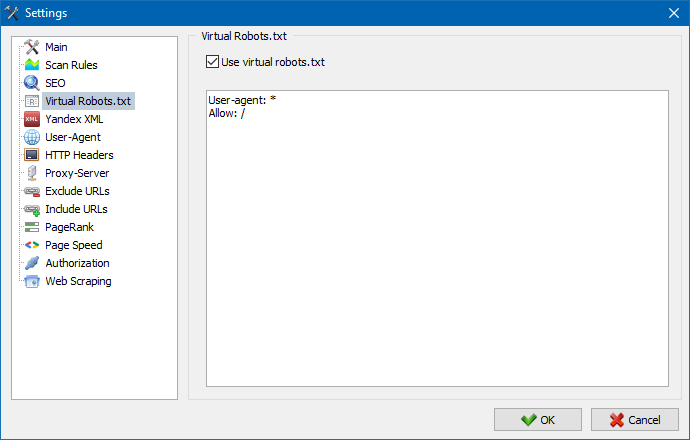
Ciò è utile durante il test di un sito, quando, ad esempio, è necessario eseguire la scansione di alcune sezioni del sito che sono chiuse dall'indicizzazione (o viceversa - non tenerne conto durante la scansione), mentre non è necessario effettuare fisicamente modifiche al vero robots.txt e dedicare il tempo dello sviluppatore su questo.
Nota: quando si importa un elenco di URL, vengono prese in considerazione le direttive del robots.txt virtuale (se questa opzione è attivata), altrimenti non viene preso in considerazione robots.txt per l'elenco di URL.
Nella sezione User-Agent è possibile specificare la modalità utente-agente sarà presentato il programma quando si accede a siti esterni durante la loro scansione. Per умочанию, installato utente utente-agente, tuttavia, se necessario, è possibile scegliere uno dei standard agenti, più frequenti in internet. Tra questi c'è, come: i bot dei motori di ricerca YandexBot, GoogleBot, MicrosoftEdge, bot browser Chrome, Firefox, IE8, e anche i dispositivi mobili iPhone, Android e molti altri.

Usando questa opzione, puoi analizzare la reazione del sito e delle pagine alle diverse richieste. Ad esempio, qualcuno potrebbe aver bisogno di inviare un Referer in una richiesta, i proprietari di siti multilingue vogliono trasmettere Accept-Language | Charset | Encoding e qualcuno ha bisogno di trasmettere dati insoliti nelle intestazioni Accept-Encoding, Cache-Control, Pragma , ecc. NS.
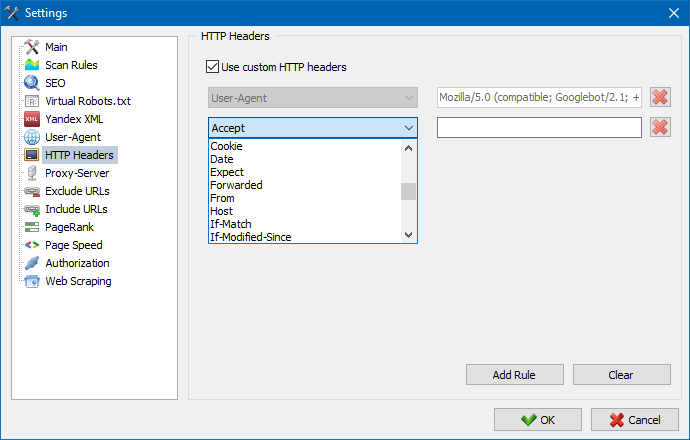
Usando questa opzione, puoi analizzare la reazione del sito e delle pagine alle diverse richieste. Ad esempio, qualcuno potrebbe aver bisogno di inviare un Referer in una richiesta, i proprietari di siti multilingue vogliono trasmettere Accept-Language | Charset | Encoding e qualcuno ha bisogno di trasmettere dati insoliti nelle intestazioni Accept-Encoding, Cache-Control, Pragma , ecc. NS.
Se c'è la necessità di operare attraverso un proxy, in questa sezione è possibile aggiungere un elenco di server proxy, attraverso cui il programma si rivolge a risorse esterne. Inoltre, c'è la possibilità di verificare proxy per le prestazioni, ma anche la funzione di rimuovere i server proxy.

Questa sezione è stata progettata per l'eliminazione di ricerca per indicizzazione di alcune pagine e sezioni del sito nel parsing di numeri in.
Utilizzando i modelli di ricerca * e ? è possibile specificare quali sezioni del sito non devono essere sottoposte a scansione dal crawler e, di conseguenza, non devono essere incluse nel database del programma. Questo elenco è locale un elenco di eccezioni sul tempo di scansione del sito (su di lui "globale" l'elenco è il file "robots.txt" nella root del sito).

Allo stesso modo, ti consente di aggiungere URL che devono essere sottoposti a scansione. In questo caso, tutti gli altri URL al di fuori di queste cartelle verranno ignorati durante la scansione. Questa opzione funziona anche con i modelli di ricerca * e ?

Utilizzando il parametro PageRank, è possibile analizzare la struttura di navigazione dei propri siti, nonché ottimizzare il sistema di collegamenti interni di una risorsa Web per la trasmissione del peso di riferimento alle pagine più importanti.

Il programma ha due opzioni per il calcolo del PageRank: l'algoritmo classico e la sua controparte più moderna. In generale, per l'analisi del collegamento interno del sito non c'è molta differenza quando si utilizza il primo o il secondo algoritmo, quindi è possibile utilizzare uno dei due algoritmi.
Per una descrizione dettagliata dell'algoritmo e dei principi di calcolo del PageRank, consultare l'articolo "Calcolo del PageRank interno" >>

Immettere login e password per l'autorizzazione automatica nelle pagine chiuse tramite .htpasswd e protette dall'autorizzazione del server BASIC.
Il lavoro con il programma
Al termine della scansione, l'utente diventa disponibile per le informazioni pubblicate nella sezione "dati di Base". Ogni scheda contiene i dati, raggruppati per quanto riguarda i loro nomi (ad esempio, la scheda "Title" contiene il contenuto dell'intestazione di pagina <title></title> scheda "Immagine" contiene un elenco di tutte le immagini del sito e così via). Con questi dati è possibile effettuare un'analisi del contenuto del sito, individuazione dei "rotti" link o non correttamente compilati meta-tag.

Se necessario (ad esempio, dopo la pubblicazione delle modifiche sul sito) tramite il menu contestuale c'è la possibilità di una nuova scansione dei singoli URL per visualizzare le modifiche nel programma.
Con l'aiuto di questo stesso menu è possibile visualizzare le pagine duplicate nei rispettivi parametri (duplicati title, description, keywords, h1, h2, dei contenuti delle pagine).

L'elemento "Rescan URL con codice 0" è progettato per ricontrollare automaticamente tutte le pagine che danno un codice di risposta 0 (Lettura timeout). Questo codice di risposta viene in genere fornito quando il server non ha il tempo di consegnare il contenuto e la connessione viene chiusa per timeout, rispettivamente, la pagina non può essere caricata e le informazioni da essa non possono essere estratte.
Personalizzazione delle colonne e delle schede
Ora è possibile selezionare le schede visualizzate nell'interfaccia di base di dati (finalmente, è stato possibile dire addio alla obsoleta la scheda del Meta di parole Chiavi). Questo è utile se taba non vengono visualizzati sullo schermo, o raramente si utilizzano.

Anche le colonne, è possibile nascondere o spostare nella posizione desiderata trascinando.
Visualizzazione schede e colonne, è possibile impostare tramite il menu a comparsa del pannello di base di dati. Lo spostamento delle colonne avviene tramite mouse.
Per facilitare l'analisi delle statistiche del sito in programma è disponibile filtraggio dei dati. Il filtro è disponibile in due versioni:
- per tutti i campi con l'aiuto di "veloce" del filtro
- con l'uso di un filtro personalizzato (con l'aiuto delle impostazioni avanzate di recupero dati)
Filtro rapido
Viene utilizzato per filtrare velocemente i dati e si applica anche a tutti i campi della scheda corrente.

Filtro personalizzato
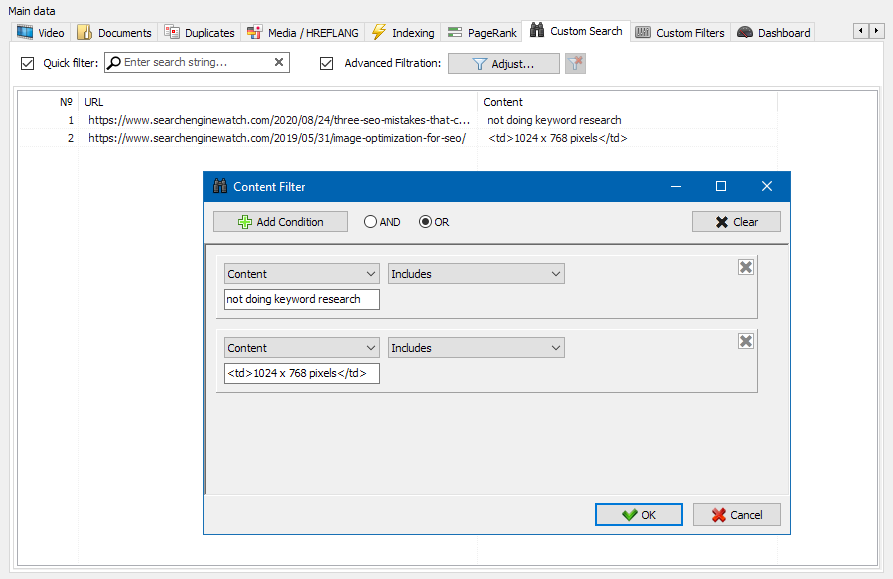
È stato progettato per ulteriori filtrazione e può contenere contemporaneamente più condizioni. Ad esempio, per il meta-tag "title" andate a filtrare le pagine per la loro lunghezza, in modo che non superi i 70 caratteri e contemporaneamente contiene il testo "notizie". Allora il filtro sarà così:

In questo modo, applicando un filtro personalizzato a qualsiasi delle schede è possibile ricevere un campione di dati di qualsiasi complessità.
La scheda delle statistiche tecniche del sito si trova nel pannello Dati aggiuntivi e contiene una serie di parametri tecnici di base del sito: statistiche sui collegamenti, meta tag, codici di risposta alle pagine, parametri di indicizzazione delle pagine, tipi di contenuto, ecc. parametri.
Facendo clic su uno dei parametri, questi vengono automaticamente filtrati nella scheda corrispondente dei dati anagrafici del sito e allo stesso tempo le statistiche vengono visualizzate sul diagramma nella parte inferiore della pagina.

La scheda Statistiche SEO è intesa per condurre audit di sito completi e contiene oltre 50 parametri SEO principali e identifica oltre 60 errori chiave di ottimizzazione interna! La mappatura degli errori è suddivisa in gruppi, che a loro volta contengono insiemi di parametri analizzati e filtri che rilevano errori nel sito.
Una descrizione dettagliata di tutti i parametri selezionati è in questo articolo. >>

Per tutti i risultati del filtraggio, è possibile esportarli rapidamente in Excel senza dialoghi aggiuntivi (il report viene salvato nella cartella del programma).
In questa scheda vengono posizionati i filtri predefiniti che consentono di creare campionamento per tutti i link esterni, errori 404, immagini e altri parametri con tutte le pagine in cui sono presenti. In questo modo, ora è possibile rapidamente e facilmente ottenere un elenco di link esterni e delle pagine in cui sono collocati, oppure selezionare tutti i collegamenti interrotti e una volta di vedere in quali pagine si trovano.

Tutti i report sono disponibili in programma in modalità on-line e sono visualizzati nella scheda "Custom" del pannello di base di dati. Inoltre, c'è la possibilità di esportare in Excel tramite il menu principale.
La funzione di ricerca del contenuto del sito ti consente di cercare nel codice sorgente e visualizzare le pagine web che contengono il contenuto che stai cercando.
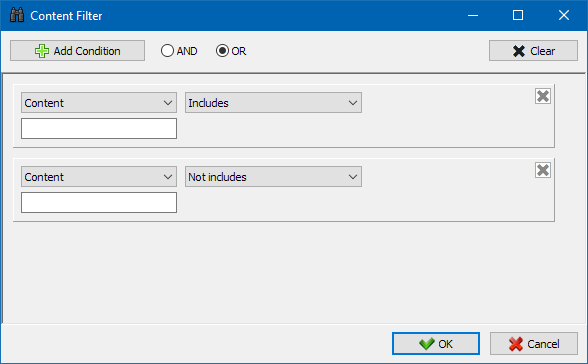
Il modulo filtri personalizzati permette di verificare la presenza di micro-markup, meta-tag, sistemi di analisi, frammenti di testo libero o codice HTML sul sito.
Nella finestra di configurazione del filtro sono presenti diversi parametri per la ricerca di determinati frammenti di testo nelle pagine del sito o, al contrario, per escludere pagine contenenti determinati frammenti di testo o codice HTML dai risultati di ricerca (questa funzione è simile alla ricerca di contenuto nel codice sorgente di una pagina utilizzando Ctrl-F) ...
In genere, lo scraping viene utilizzato per risolvere attività difficili da gestire manualmente. Questo può essere l'estrazione delle descrizioni dei prodotti per creare un nuovo negozio online, il raschiamento nelle ricerche di mercato per monitorare i prezzi o per monitorare gli annunci.

In SiteAnalyzer, lo scraping è configurato nella scheda Estrazione dati, dove sono configurate le regole di estrazione. Le regole possono essere salvate e, se necessario, modificate.
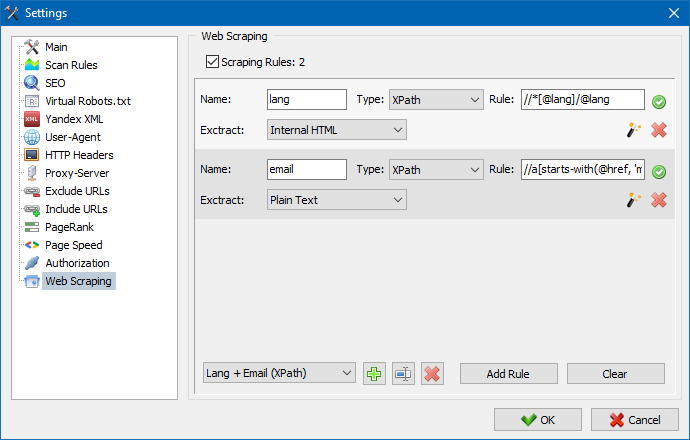
C'è anche un modulo di test delle regole. Utilizzando il debugger di regole integrato, puoi ottenere rapidamente e facilmente il contenuto HTML di qualsiasi pagina del sito e testare il lavoro delle query, quindi utilizzare le regole di debug per l'analisi dei dati in SiteAnalyzer.

Dopo aver terminato l'estrazione dei dati, tutte le informazioni raccolte possono essere esportate in Excel.
Per uno studio più dettagliato del funzionamento del modulo e un elenco delle regole e delle espressioni regolari più comuni, consultare l'articolo
Controllo dell'unicità dei contenuti
Questo strumento permette di cercare pagine duplicate e verificare l'unicità dei testi all'interno del sito. In altre parole, questo è un controllo batch di un gruppo di URL per verificarne l'unicità.
Questo può essere utile nei casi:
- Per cercare pagine duplicate complete (ad esempio, una pagina con parametri e la stessa pagina, ma nella vista del CNC).
- Per cercare corrispondenze parziali di contenuto (ad esempio, due ricette di borscht in un blog culinario, che sono simili al 96% tra loro, il che suggerisce che uno degli articoli dovrebbe essere eliminato per eliminare la possibile cannibalizzazione del traffico).
- Quando su un sito di articoli hai scritto accidentalmente un articolo su un argomento che hai già scritto 10 anni fa. In questo caso, il nostro strumento rileverà anche un duplicato di tale articolo.
Il principio dello strumento per verificare l'unicità dei contenuti è semplice: il programma scarica il loro contenuto dall'elenco degli URL del sito Web, riceve il contenuto testuale della pagina (senza il blocco HEAD e senza tag HTML), quindi li confronta con ciascuno altro utilizzando l'algoritmo shingle.

Pertanto, utilizzando l'herpes zoster, determiniamo l'unicità delle pagine e possiamo calcolare sia i duplicati completi di pagine con lo 0% di unicità, sia i duplicati parziali con vari gradi di unicità del contenuto del testo. Il programma funziona con una lunghezza di scandole di 5.
Puoi saperne di più su come funziona il modulo in questo articolo.: >>
Controllo della velocità di caricamento della pagina
Lo strumento PageSpeed Insights del gigante della ricerca di Google ti consente di controllare la velocità di caricamento di determinati elementi della pagina e mostra anche il punteggio complessivo della velocità di caricamento degli URL di interesse per le versioni desktop e mobile del browser.

Lo strumento di Google è buono per tutti, tuttavia, ha uno svantaggio significativo: non ti consente di creare controlli URL di gruppo, il che crea inconvenienti quando controlli molte pagine del tuo sito: accetta di controllare manualmente la velocità di download per 100 o più URL su una pagina è un lavoro ingrato e può richiedere molto tempo.
Pertanto, abbiamo creato un modulo che consente di creare controlli di gruppo della velocità di caricamento della pagina gratuitamente tramite un'API speciale nello strumento Google PageSpeed Insights.

Principali parametri analizzati:
- FCP (First Contentful Paint) – tempo per visualizzare il primo contenuto.
- SI (Speed Index) – un indicatore della velocità con cui il contenuto viene visualizzato su una pagina.
- LCP (Largest Contentful Paint) – tempo di visualizzazione per l'elemento più grande della pagina.
- TTI (Time to Interactive) – il tempo durante il quale la pagina diventa completamente pronta per l'interazione dell'utente.
- TBT (Total Blocking Time) – tempo dal primo rendering del contenuto alla sua disponibilità per l'interazione dell'utente.
- CLS (Cumulative Layout Shift) – spostamento cumulativo del layout. Serve a misurare la stabilità visiva della pagina.
Allo stesso tempo, l'analisi dell'URL stesso avviene in un paio di clic, dopodiché è possibile scaricare un report, contenente le principali caratteristiche dei controlli in un comodo modulo in Excel.
Tutto ciò che serve per iniziare è ottenere una chiave API.
Come farlo è descritto in questo articolo. >>
Questa funzionalità è stato progettato per creare la struttura del sito sulla base dei dati ricevuti. La struttura del sito è generato sulla base di nidificazione URL delle pagine. Dopo la generazione della struttura è disponibile la sua esportazione in formato CSV (Excel).

Il menu di scelta rapida elenco dei progetti
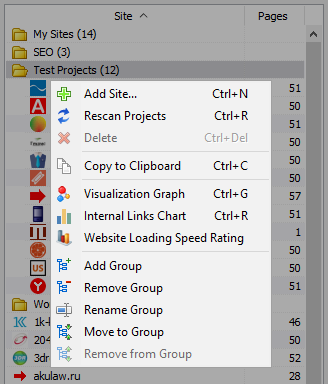
- Nell'elenco dei progetti è disponibile la scansione di massa attraverso l'assegnazione di siti necessari e aver premuto il pulsante "Rescan". Dopo di che tutti i siti diventano il luogo e analizzati alternativamente in modalità standard.
- Inoltre, per la comodità di lavorare con il programma, la cancellazione di siti selezionati anche disponibile sul pulsante "Rimuovi".
- L'unità di scansione di siti, c'è la possibilità di aggiungere siti alla lista dei progetti con l'aiuto di una speciale forma, dopo di che l'utente può eseguire la scansione di interesse per progetti intero.
- Per una navigazione più comoda nell'elenco dei progetti, è possibile raggruppare i siti per cartelle, nonché filtrare l'elenco dei progetti per nome.

Visualizzazione della struttura del sito Web
La modalità di rendering di riferimento legami sul grafico vi aiuterà SEO specialista di valutare la distribuzione interna PageRank delle pagine del sito, ma anche di capire quali delle pagine ottengono il maggior peso di riferimento (e di conseguenza, più interno riferimento peso agli occhi dei motori di ricerca), così come le pagine e sezioni del sito non manca di collegamenti interni.

Utilizzando la modalità di visualizzazione della struttura del sito SEO-specialista in grado di valutare visivamente come è organizzata interno di collegamento al sito, ma anche attraverso la rappresentazione visiva di massa PageRank assegnato un modo o nell'altro le pagine, prontamente apportare correzioni al corrente perelinkovka del sito e quindi aumentare l'attinenza interesse di pagine.
Nella parte sinistra della finestra di visualizzazione sono gli strumenti di base per lavorare con conte:
- zoom sul grafico
- ruotare il conte di un angolo arbitrario
- una finestra di commutazione del conte in modalità a schermo intero (funziona anche con il tasto F11)
- visualizzare / nascondere le firme ai nodi (Ctrl-T)
- per visualizzare / nascondere il tiratore linee
- mostra / nascondi link a risorse esterne (Ctrl-E)
- modalità di commutazione schema di colori Giorno / Notte (Ctrl-D)
- visualizzare / nascondere la legenda e le statistiche del conte (Ctrl-L)
- la conservazione del conte in formato PNG (Ctrl-S)
- la finestra delle impostazioni di visualizzazione (Ctrl-O)
La sezione "Vista" è stato progettato per modificare il formato di visualizzazione dei nodi sul grafico. In modalità di disegno nodi "PageRank", dimensioni nodi vengono installati per quanto riguarda il loro in precedenza, è stato calcolato un indicatore del PageRank, portando sul grafico si può chiaramente vedere le pagine che ricevono il maggior numero di riferimento di peso, e come va a meno di riferimenti.
In modalità classica dimensioni nodi vengono installati per quanto riguarda il candidato scala del grafico di rendering.
Grafico distribuzione link interni
Questo grafico mostra la distribuzione della massa di link interni sulle pagine del sito (possiamo dire che questa è una visualizzazione del link in una forma visiva, piuttosto che è presentata sul Visualization Graph). Leggi di più >>
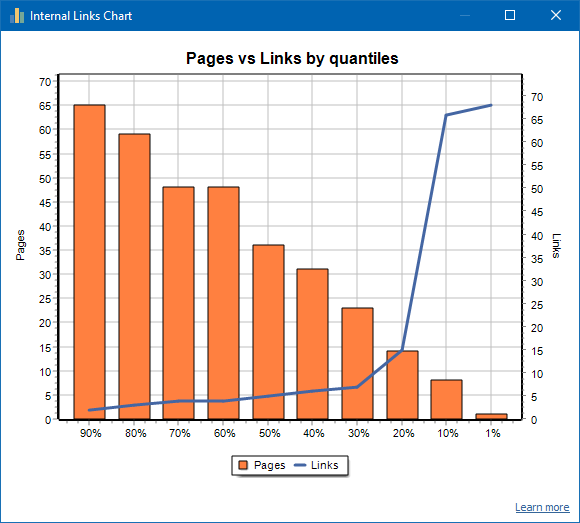
A sinistra è il numero di pagine, a destra è il numero di collegamenti. Di seguito sono riportati i quantili percentuali per pagina. Quando si disegna un grafico, i collegamenti duplicati vengono scartati (se ci sono 3 collegamenti dalla pagina A alla pagina B, li contiamo come uno).
Ad esempio, in base allo screenshot qui sopra, per un sito di circa 70 pagine:
- 1% pagine hanno ~68 link in entrata.
- 10% pagine hanno ~66 link in entrata.
- 20% pagine hanno ~15 link in entrata.
- 30% pagine hanno ~8 link in entrata.
- 40% pagine hanno ~7 link in entrata.
- 50% pagine hanno ~6 link in entrata.
- 60% pagine hanno ~5 link in entrata.
- 70% pagine hanno ~5 link in entrata.
- 80% pagine hanno ~3 link in entrata.
- 90% pagine hanno ~2 link in entrata.
Cioè, se vediamo che abbiamo pagine a cui portano meno di 10 link in entrata, allora tali pagine possono essere considerate debolmente collegate e il 60% delle nostre pagine sono normalmente collegate. Sulla base di ciò, possiamo inserire più link interni a queste pagine debolmente collegate (se le pagine sono importanti per la promozione), o lasciarlo così com'è, se tali pagine sono di bassa importanza e bassa priorità.
Nella pratica generale, le pagine con meno di 10 link interni hanno meno probabilità di essere scansionate dai robot dei motori di ricerca, in particolare i bot di Google.
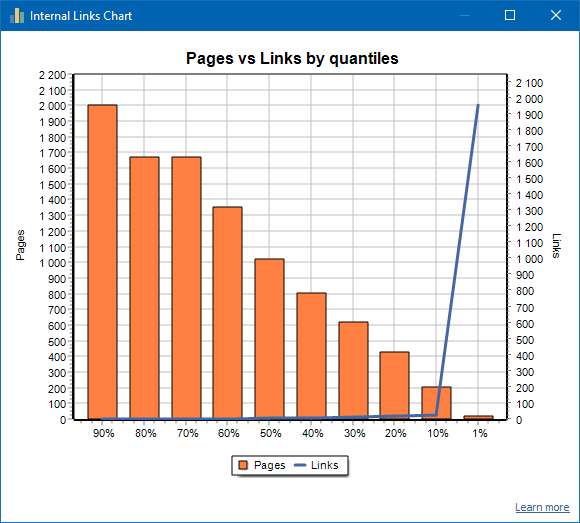
Pertanto, se vedi un sito che ha solo il 20-30% di pagine normalmente collegate dal numero totale di pagine del sito, allora ha senso approfondire l'impostazione del collegamento o pensare a come gestire l'80-70% di pagine con link debolmente (elimina, nascondi da indicizzazione, reindirizzamenti put).
Un esempio di un sito debolmente collegato:
Un esempio di un sito ben collegato:
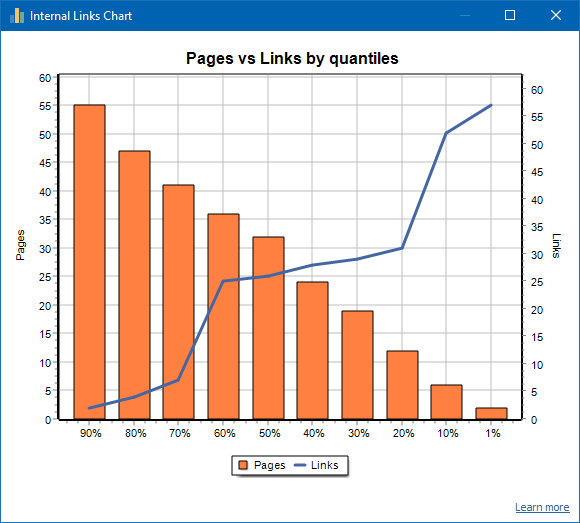
Grafico della velocità di caricamento della pagina
Il grafico della velocità di caricamento della pagina consente di valutare le prestazioni del sito. Per chiarezza, le pagine sono suddivise in gruppi e intervalli di tempo con un passo di 100 millisecondi.
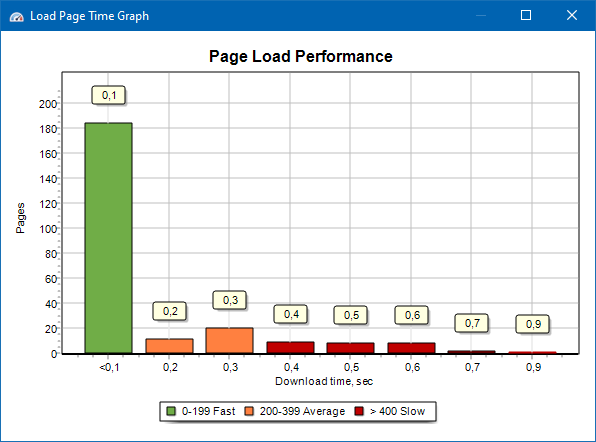
Pertanto, in base al grafico, è possibile determinare quale percentuale di pagine del sito viene caricata rapidamente (entro 0-100 millisecondi), quale a una velocità media (100-200 millisecondi) e quali pagine vengono caricate abbastanza a lungo (400 millisecondi o più).
Nota: il tempo mostrato è il tempo per caricare il codice sorgente HTML, non il tempo per caricare completamente le pagine (il rendering della pagina, così come il caricamento degli elementi della pagina, come immagini e stili, non vengono presi in considerazione).
Generazione Sitemap.xml
La mappa del sito viene generata in base alle pagine o alle immagini del sito sottoposte a scansione.
- Quando si genera una mappa del sito composta da pagine, vengono aggiunte pagine in formato "testo / html".
- Quando si genera una mappa del sito composta da immagini, vengono aggiunti JPG, PNG, GIF e immagini simili.
Generare una mappa del sito è possibile subito dopo la scansione di un sito attraverso il menu principale la voce "Progetti -> Generare Sitemap".

Per i siti di grandi dimensioni, da 50 000 pagine, dispone di una funzione di partizionamento automatico "sitemap.xml" in più file (in questo caso, il file contiene collegamenti a ulteriori contenenti direttamente i link alle pagine del sito). Ciò è dovuto alle esigenze dei motori di ricerca per la gestione dei file sitemap di grandi dimensioni.

Se necessario, la quantità di pagine in un file "sitemap.xml" può essere variata modificando il valore di 50 000 (impostazione predefinita) sul valore desiderato in impostazioni di base del programma.
La scansione arbitrarie URL
La voce di menu "Importa URL" progettato per eseguire la scansione arbitrarie elenchi di URL, e anche XML-sitemaps Sitemap.xml (tra cui e indice) per la loro successiva analisi.
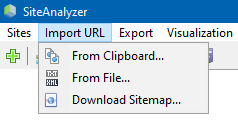
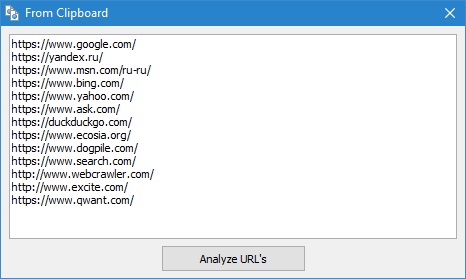
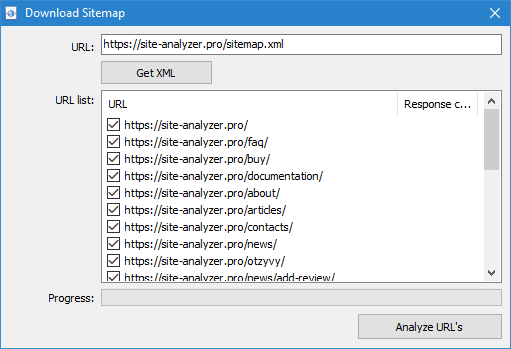
La scansione arbitrarie URL possibile in tre modi:
- mediante l'inserimento di un elenco di URL dagli appunti
- boot dal disco rigido i file in formato *.txt e *.xml contenenti elenchi di URL
- scaricando il file Sitemap.xml direttamente dal sito
Una caratteristica di questa modalità è che quando si esegue la scansione arbitrarie URL stesso "progetto" non è salvato il programma e le informazioni su di esso non viene aggiunto al database. Inoltre, non sono disponibili sezioni "Struttura del sito" e "Dashboard".
Più familiarità con il lavoro di voce "Import URL" può essere in questo articolo: Recensione della nuova versione SiteAnalyzer 1.9.
Dashboard
La scheda "Dashboard", consente di visualizzare un rapporto dettagliato sull'attuale come ottimizzazione del sito web. Il report viene generato sulla base di dati della scheda "Statistiche SEO". Oltre a questi dati in un report è presente l'indicazione generale del punteggio di qualità di ottimizzazione del sito web, calcolato per 100-scala di corrente per quanto riguarda il grado di ottimizzazione. C'è la possibilità di esportare i dati della scheda "Dashboard" in un comodo report in formato PDF.

Esportazione dei dati
Più flessibile per l'analisi dei dati ottenuti è possibile il loro scarico in formato CSV (esportati attuale scheda attiva), così come la generazione piena di report in Microsoft Excel con tutte le schede in un unico file.

Durante l'esportazione dei dati in Excel compare una finestra in cui l'utente può selezionare le colonne e quindi generare un report con i dati giusti.

Multilanguage
Il programma ha la possibilità di selezionare la lingua preferita, in cui verrà svolto il lavoro.
Le principali lingue supportate: inglese, russo, tedesco, italiano, spagnolo, francese... Per il momento il programma è tradotto in più di quindici (15) lingue più popolari.

Se si desidera tradurre il programma per la lingua, per questo è sufficiente trasferire qualsiasi tipo di file "*.lng" per la nostra lingua, dopo di che il file tradotto necessario inviare all'indirizzo "support@site-analyzer.pro" (commenti alla lettera devono essere scritti in russo o in inglese) e la traduzione sarà incluso nella nuova versione del programma.
Istruzioni più dettagliate per la traduzione del programma in lingue è in distribuzione (file "lcids.txt").
P.S. Se avete commenti sulla qualità della traduzione - di inviare osservazioni e correzioni "support@site-analyzer.ru".
Compressione del database
La voce del menu principale "Compattare un database" è stato progettato per eseguire le operazioni di confezionamento del database (pulizia di base dal eliminati in precedenza progetti e organizzare dati (analogo deframmentazione dei dati su personal computer)).
Questa procedura è efficace nel caso in cui, ad esempio, il programma è stato rimosso un grande progetto, contenente un gran numero di voci. In generale si consiglia di effettuare periodicamente la compressione dei dati per sbarazzarsi di eccesso di dati e ridurre la quantità di base.
Con le risposte alle altre domande è possibile consultare la sezione FAQ >>



















