






















 1,379
1,379साइट के भीतर डुप्लिकेट पृष्ठों और ग्रंथों की विशिष्टता का निर्धारण करने का मुद्दा तकनीकी ऑडिट कार्य की सूची में सबसे महत्वपूर्ण है। साइट की समग्र भलाई और खोज इंजन के क्रॉलिंग बजट का वितरण, जो बर्बाद हो सकता है, डुप्लिकेट पृष्ठों की उपस्थिति पर निर्भर करता है, और सामान्य तौर पर, साइट की रैंकिंग बड़ी संख्या में डुप्लिकेट के कारण कठिनाइयों का अनुभव कर सकती है। विषय।

और यदि आप अलग-अलग ग्रंथों की विशिष्टता की जांच करने के लिए इंटरनेट पर बड़ी संख्या में सेवाओं और कार्यक्रमों को आसानी से पा सकते हैं, तो आपस में कुछ यूआरएल के समूह की विशिष्टता की जांच करने के लिए कई समान सेवाएं नहीं हैं, हालांकि समस्या ही महत्वपूर्ण है और प्रासंगिक।
साइट पर गैर-अद्वितीय सामग्री के साथ समस्याओं के लिए कौन से विकल्प हो सकते हैं?
1. विभिन्न URL पर समान सामग्री।
आमतौर पर यह पैरामीटर और एक ही पेज वाला एक पेज होता है, लेकिन एक सीएनसी (मानव-पठनीय यूआरएल) के रूप में होता है।
- उदाहरण:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
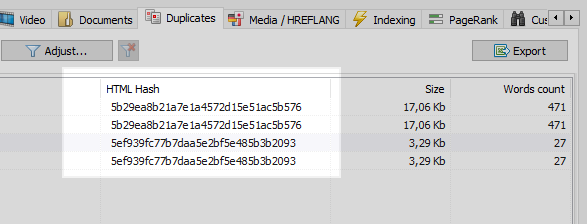
यह एक काफी सामान्य समस्या है, जब सीएनसी स्थापित करने के बाद, प्रोग्रामर पैरामीटर वाले पृष्ठों से सीएनसी पृष्ठों पर 301 रीडायरेक्ट सेट करना भूल जाता है।
यह समस्या किसी भी वेब क्रॉलर द्वारा आसानी से हल की जाती है, जो साइट के सभी पृष्ठों की तुलना करने के बाद, यह पायेगा कि उनमें से दो में समान हैश कोड (MD5) हैं, और इसके बारे में ऑप्टिमाइज़र को सूचित करें, जिसे कार्य सेट करना होगा , सभी समान प्रोग्रामर, सीएनसी पृष्ठों पर 301 रीडायरेक्ट स्थापित करने के लिए।
हालाँकि, सब कुछ इतना स्पष्ट नहीं है।
2. आंशिक रूप से मेल खाने वाली सामग्री।
समान सामग्री तब बनती है जब हमारे पास अलग-अलग पृष्ठ होते हैं, लेकिन वास्तव में, समान या समान सामग्री के साथ।
उदाहरण 1
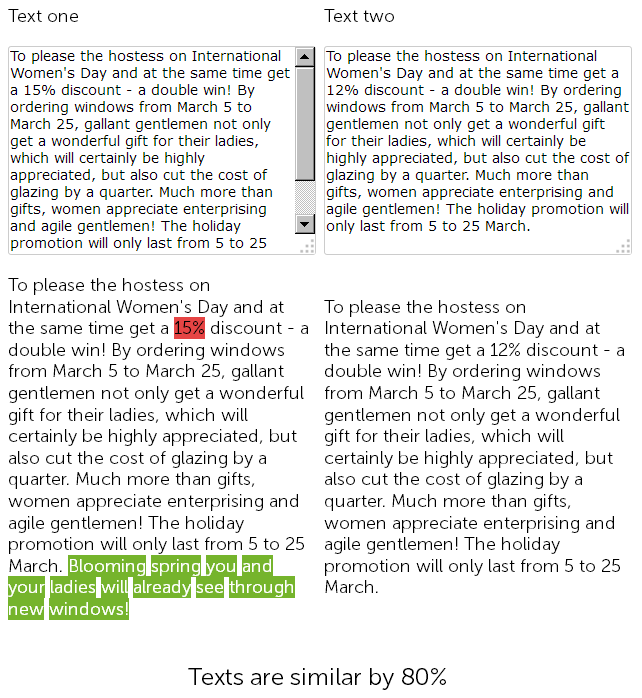
प्लास्टिक की खिड़कियां बेचने वाली साइट पर समाचार अनुभाग में एक कॉपीराइटर ने एक साल पहले 8 मार्च को 500 अक्षरों के लिए बधाई लिखी और प्लास्टिक की खिड़कियां लगाने पर 15% की छूट दी।
और इस साल, सामग्री प्रबंधक ने धोखा देने का फैसला किया, और आगे की हलचल के बिना, उसने पहले से पोस्ट की गई खबरों को छूट के साथ पाया, इसे कॉपी किया, और छूट को 15 से 12% में बदल दिया + अतिरिक्त बधाई के साथ अपने आप में 50 संकेत जोड़े।
इस प्रकार, परिणामस्वरूप, हमारे पास दो लगभग समान ग्रंथ हैं, जो 90% के समान हैं, जो अपने आप में फजी डुप्लिकेट हैं, जिनमें से एक, अच्छे के लिए, तत्काल पुनर्लेखन की आवश्यकता है।
उसी समय, तकनीकी ऑडिट सेवाओं के लिए, ये दो समाचार अलग होंगे, क्योंकि साइट पर सीएनसी पहले से ही कॉन्फ़िगर किया गया है, और पृष्ठों के चेकसम मेल नहीं खाएंगे, चाहे कोई कुछ भी कहे।
नतीजतन, कौन सा पेज बेहतर रैंक करेगा यह एक बड़ा सवाल है ...
लेकिन वे ऐसी खबरें हैं - वे जल्दी अप्रचलित हो जाती हैं, तो चलिए एक और दिलचस्प उदाहरण लेते हैं।
उदाहरण 2
आपकी साइट पर एक लेख अनुभाग है, या आप अपने शौक / जुनून के लिए एक व्यक्तिगत पृष्ठ बनाए रखते हैं, उदाहरण के लिए, यह एक "पाक ब्लॉग" है।
और, उदाहरण के लिए, आपके ब्लॉग ने पहले ही कई लेखों को जमा कर लिया है, 100 से अधिक, या कई सौ से भी अधिक। और इसलिए आपने एक विषय उठाया और एक नया लेख लिखा, उसे पोस्ट किया, और फिर किसी तरह यह पता चला कि इसी तरह का लेख 3 साल पहले भी लिखा जा चुका था। हालाँकि, ऐसा प्रतीत होता है, सामग्री लिखने से पहले, आप सभी शीर्षकों पर चले गए, एक्सेल को पोस्ट किए गए विषयों की सूची के साथ खोला, लेकिन इस बात पर ध्यान नहीं दिया कि लेख की पिछली सामग्री "घर पर हॉट चॉकलेट कैसे बनाएं" दृढ़ता से अभी लिखी गई सामग्री के साथ मेल खाता है। और ऑनलाइन सेवाओं में से एक में इन दो लेखों की जाँच करने पर, यह पता चलता है कि वे आपस में 78% अद्वितीय हैं, जो निश्चित रूप से अच्छा नहीं है, क्योंकि आंशिक दोहराव के कारण, खोज क्वेरी इन पृष्ठों और खोज के बीच नरभक्षी हो जाती हैं। ऐसे डुप्लिकेट की रैंकिंग करते समय इंजन के प्रश्न और कठिनाइयाँ उत्पन्न होती हैं।
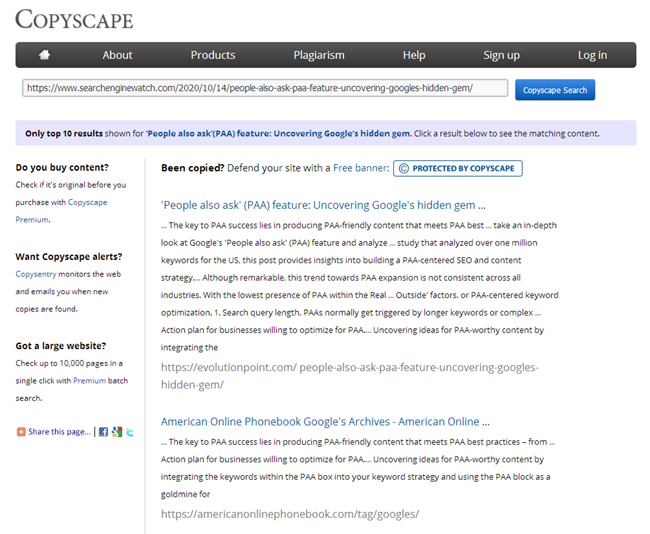
बेशक, एक लेख लिखने के बाद, प्रत्येक कॉपीराइटर को प्रसिद्ध सेवाओं में से एक में विशिष्टता के लिए इसकी जांच करनी चाहिए, और प्रत्येक एसईओ विशेषज्ञ को उसी सेवाओं में साइट पर पोस्ट किए जाने पर नई सामग्री की जांच करनी चाहिए।
लेकिन क्या करें यदि आपको अभी-अभी प्रचार के लिए कोई साइट मिली है और आपको डुप्लिकेट के लिए इसके सभी पृष्ठों की तुरंत जाँच करने की आवश्यकता है? या, अपने ब्लॉग को खोलने की शुरुआत में, आपने एक ही प्रकार के लेखों का एक गुच्छा लिखा था, और अब, सबसे अधिक संभावना है, उनकी वजह से, साइट शिथिल होने लगी। ऑनलाइन सेवाओं में मैन्युअल रूप से 100,500 पृष्ठों की जांच न करें, प्रत्येक लेख को मैन्युअल रूप से जांचने के लिए जोड़कर और उस पर बहुत समय व्यतीत करें।
BatchUniqueChecker
यही कारण है कि हमने बैचयूनिकचेकर प्रोग्राम बनाया है, जिसे बैच के लिए डिज़ाइन किया गया है ताकि आपस में अद्वितीयता के लिए यूआरएल के समूह की जांच की जा सके।
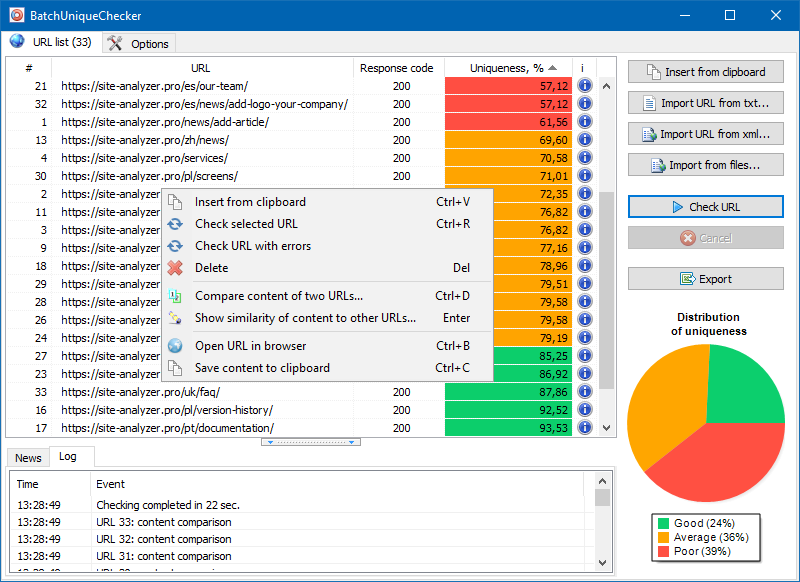
BatchUniqueChecker के संचालन का सिद्धांत सरल है: URL की पूर्व-तैयार सूची के अनुसार, प्रोग्राम उनकी सामग्री को डाउनलोड करता है, PlainText (HEAD ब्लॉक के बिना और HTML टैग के बिना पृष्ठ की पाठ सामग्री) प्राप्त करता है, और फिर प्रत्येक के साथ उनकी तुलना करता है। अन्य शिंगल एल्गोरिथ्म का उपयोग कर।
इस प्रकार, दाद की मदद से, हम पृष्ठों की विशिष्टता का निर्धारण करते हैं और 0% विशिष्टता वाले पृष्ठों के पूर्ण डुप्लिकेट और टेक्स्ट सामग्री विशिष्टता की विभिन्न डिग्री के साथ आंशिक डुप्लिकेट दोनों की गणना कर सकते हैं।
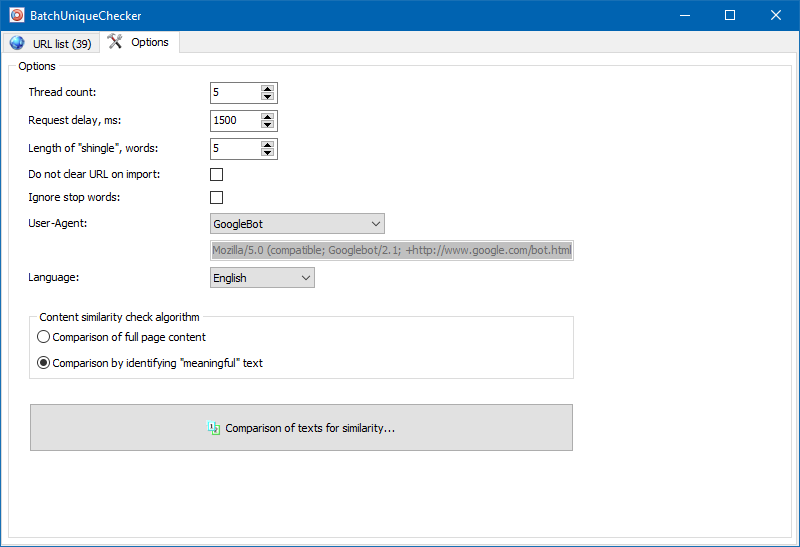
प्रोग्राम सेटिंग्स में, शिंगल के आकार को मैन्युअल रूप से सेट करना संभव है (शिंगल टेक्स्ट में शब्दों की संख्या है, जिसके चेकसम को बाद के समूहों के साथ वैकल्पिक रूप से तुलना की जाती है)। हम मान = 4 सेट करने की सलाह देते हैं। बड़ी मात्रा में टेक्स्ट के लिए, 5 या अधिक। अपेक्षाकृत छोटी मात्रा के लिए - 3-4।
महत्वपूर्ण ग्रंथ
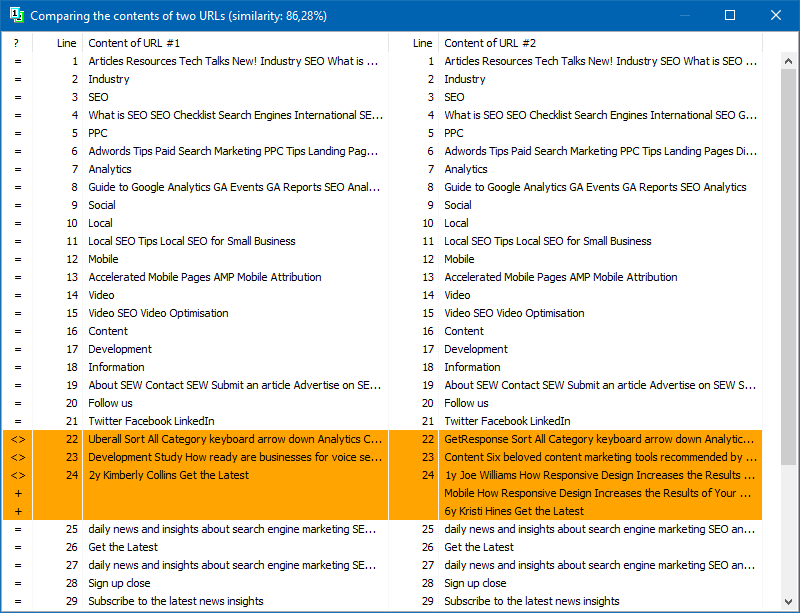
पूर्ण-पाठ सामग्री तुलना के अलावा, कार्यक्रम में तथाकथित "महत्वपूर्ण" ग्रंथों के "स्मार्ट" चयन के लिए एक एल्गोरिदम शामिल है।
यानी पेज के HTML कोड से ही हमें H1-H6, P, PRE और LI टैग्स में मौजूद कंटेंट ही मिलता है। इसके कारण, हम सब कुछ "महत्वपूर्ण नहीं" को छोड़ देते हैं, उदाहरण के लिए, साइट नेविगेशन मेनू से सामग्री, पाद लेख या साइड मेनू से टेक्स्ट।
इस तरह के जोड़तोड़ के परिणामस्वरूप, हमें पृष्ठों की केवल "सार्थक" सामग्री मिलती है, जिसकी तुलना करने पर, अन्य पृष्ठों के साथ विशिष्टता के अधिक सटीक परिणाम दिखाई देंगे।
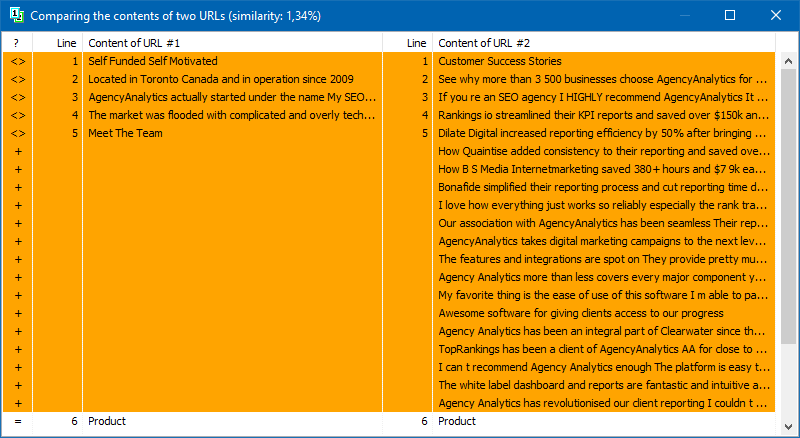
उनके आगे के विश्लेषण के लिए पृष्ठों की सूची को कई तरीकों से जोड़ा जा सकता है: क्लिपबोर्ड से चिपकाया गया, टेक्स्ट फ़ाइल से लोड किया गया, या आपके कंप्यूटर की डिस्क से Sitemap.xml से आयात किया गया।
कार्यक्रम के बहु-थ्रेडेड कार्य के लिए धन्यवाद, सैकड़ों या अधिक URL की जाँच में केवल कुछ मिनट लग सकते हैं, जो मैन्युअल रूप से, ऑनलाइन सेवाओं के माध्यम से, एक दिन या अधिक समय ले सकता है।
इस प्रकार, आपको URL के समूह के लिए सामग्री की विशिष्टता की शीघ्रता से जाँच करने के लिए एक सरल उपकरण मिलता है, जिसे हटाने योग्य मीडिया से भी चलाया जा सकता है।
BatchUniqueChecker नि: शुल्क, संग्रह में केवल 4 एमबी लेता है और स्थापना की आवश्यकता नहीं है।
आरंभ करने के लिए आपको केवल वितरण को डाउनलोड करना है और सत्यापन के लिए दिलचस्प URL की एक सूची जोड़ना है, जिसे एक मुफ्त तकनीकी ऑडिट कार्यक्रम के माध्यम से प्राप्त किया जा सकता है। SiteAnalyzer.

Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
अन्य लेख



















