





















कार्यक्रम का उद्देश्य
SiteAnalyzer प्रोग्राम साइट का विश्लेषण करने और तकनीकी त्रुटियों (टूटे हुए लिंक, डुप्लिकेट पेज, गलत सर्वर प्रतिक्रियाओं की खोज), साथ ही एसईओ अनुकूलन में त्रुटियों और कमियों की पहचान करने के लिए डिज़ाइन किया गया है (रिक्त मेटा टैग, h1 पृष्ठ शीर्षकों की अधिक या पूर्ण अनुपस्थिति, पृष्ठ सामग्री विश्लेषण, लिंक गुणवत्ता और कई अन्य एसईओ पैरामीटर)।

प्रमुख विशेषताऐं
- साइट के सभी पृष्ठों, साथ ही छवियों, लिपियों और दस्तावेजों को स्कैन करना
- प्रत्येक साइट पृष्ठ के लिए सर्वर प्रतिक्रिया कोड प्राप्त करना (200, 301, 302, 404, 500, 503, आदि)
- शीर्षक, कीवर्ड, विवरण, H1-H6 की उपस्थिति और सामग्री का निर्धारण
- "डुप्लिकेट" पृष्ठ, मेटा टैग और शीर्षक ढूँढना और प्रदर्शित करना
- साइट के प्रत्येक पृष्ठ के लिए rel="canonical" विशेषता की उपस्थिति का निर्धारण
- "robots.txt" फ़ाइल के निर्देशों के बाद, "robots" मेटा टैग, या X-Robots-Tag
- साइट पृष्ठों को क्रॉल करते समय "noindex" और "nofollow" के लिए लेखांकन
- XPath, CSS, XQuery, RegEx के साथ डेटा स्क्रैपिंग
- साइट के भीतर सामग्री की विशिष्टता की जाँच करना
- Google PageSpeed Checking Page Loading Speed
- लिंक विश्लेषण: साइट के किसी भी पृष्ठ के लिए आंतरिक और बाहरी लिंक का निर्धारण
- साइट के प्रत्येक पृष्ठ के लिए आंतरिक पेजरैंक की गणना
- ग्राफ़ पर साइट संरचना का विज़ुअलाइज़ेशन
- पृष्ठ से रीडायरेक्ट की संख्या निर्धारित करना (रीडायरेक्ट)
- मनमाने ढंग से URL और बाहरी Sitemap.xml क्रॉल करना
- साइटमैप जनरेशन "साइटमैप.एक्सएमएल" (एकाधिक फाइलों में विभाजित होने की संभावना के साथ)
- किसी भी पैरामीटर द्वारा डेटा फ़िल्टर करना (किसी भी जटिलता के फ़िल्टर की लचीली सेटिंग)
- साइट पर मनमानी सामग्री खोजें
- सीएसवी, एक्सेल और पीडीएफ प्रारूप में रिपोर्ट निर्यात करें
एनालॉग्स से अंतर
- कंप्यूटर संसाधनों के लिए कम आवश्यकताएं, RAM की कम खपत
- कंप्यूटर संसाधनों की कम आवश्यकताओं के कारण लगभग किसी भी मात्रा की साइटों को स्कैन करना
- पोर्टेबल प्रारूप (पीसी पर या सीधे हटाने योग्य मीडिया से स्थापना के बिना काम करता है)
दस्तावेज़ीकरण अनुभाग
- काम की शुरुआत
- कार्यक्रम सेटिंग्स
- मूल सेटिंग्स
- स्कैनिंग
- एसईओ
- वर्चुअल रोबोट्स.txt new
- Yandex XML
- उपभोक्ता अभिकर्ता
- मनमाना HTTP शीर्षलेख new
- प्रॉक्सी सर्वर
- यूआरएल बहिष्कृत करें
- यूआरएल का पालन करें
- PageRank
- प्राधिकार
- कार्यक्रम के साथ काम करना
- साइटमैप.एक्सएमएल पीढ़ी
- मनमाने ढंग से URL क्रॉल करना
- Dashboard
- डेटा निर्यात
- बहुभाषी
- डेटाबेस संपीड़न
काम की शुरुआत
जब प्रोग्राम लॉन्च किया जाता है, तो उपयोगकर्ता के पास विश्लेषण की जा रही साइट के URL को दर्ज करने के लिए एड्रेस बार तक पहुंच होती है (आप साइट के किसी भी पेज में प्रवेश कर सकते हैं, क्योंकि खोज रोबोट, स्रोत पृष्ठ के लिंक का अनुसरण करते हुए, पूरे को बायपास कर देगा) साइट, मुख्य पृष्ठ सहित, बशर्ते कि सभी लिंक HTML में बने हों और जावास्क्रिप्ट का उपयोग न करें)।
"प्रारंभ" बटन पर क्लिक करने के बाद, खोज रोबोट आंतरिक लिंक का उपयोग करके साइट के सभी पृष्ठों को क्रॉल करना शुरू कर देता है (यह बाहरी संसाधनों पर नहीं जाता है, न ही यह जावास्क्रिप्ट में बने लिंक का अनुसरण करता है)।
रोबोट द्वारा साइट के सभी पृष्ठों के माध्यम से जाने के बाद, एक रिपोर्ट उपलब्ध हो जाती है, एक तालिका के रूप में बनाई जाती है और प्राप्त डेटा को विषयगत टैब द्वारा समूहीकृत किया जाता है।
सभी विश्लेषण किए गए प्रोजेक्ट प्रोग्राम के बाईं ओर प्रदर्शित होते हैं और प्राप्त डेटा के साथ प्रोग्राम डेटाबेस में स्वचालित रूप से सहेजे जाते हैं। अनावश्यक साइटों को हटाने के लिए, परियोजना सूची के संदर्भ मेनू का उपयोग करें।
टिप्पणी:
- जब आप "रोकें" बटन पर क्लिक करते हैं, तो प्रोजेक्ट स्कैनिंग निलंबित हो जाती है, समानांतर में, वर्तमान स्कैनिंग प्रगति डेटाबेस में सहेजी जाती है, जो उदाहरण के लिए, प्रोग्राम को बंद करने और प्रोग्राम को पुनरारंभ करने के बाद प्रोजेक्ट को स्कैन करना जारी रखने की अनुमति देता है। रोक बिंदु
- "स्टॉप" बटन स्कैनिंग जारी रखने की संभावना के बिना वर्तमान प्रोजेक्ट की स्कैनिंग को बाधित करता है
कार्यक्रम सेटिंग्स
मुख्य मेनू का "सेटिंग" खंड बाहरी साइटों के साथ कार्यक्रम के संचालन को ठीक करने के लिए है और इसमें 7 टैब हैं:

साइट को स्कैन करते समय उपयोग किए जाने वाले प्रोग्राम उपयोगकर्ता निर्देशों को निर्दिष्ट करने के लिए मुख्य सेटिंग्स अनुभाग का उपयोग किया जाता है।
मापदंडों का विवरण:
- धागों की संख्या
- थ्रेड्स की संख्या जितनी अधिक होगी, प्रति यूनिट समय उतने अधिक URL संसाधित किए जा सकते हैं। यह ध्यान में रखा जाना चाहिए कि अधिक संख्या में थ्रेड्स अधिक संख्या में उपयोग किए गए पीसी संसाधनों की ओर ले जाते हैं। धागे की संख्या को 5-10 की सीमा में सेट करने की अनुशंसा की जाती है।
- स्कैन का समय
- इसका उपयोग साइट क्रॉलिंग के लिए समय सीमा निर्धारित करने के लिए किया जाता है। घंटों में मापा जाता है।
- अधिकतम गहराई
- इस पैरामीटर का उपयोग साइट क्रॉलिंग की गहराई को निर्दिष्ट करने के लिए किया जाता है। साइट के मुख्य पृष्ठ में नेस्टिंग स्तर = 0 है। उदाहरण के लिए, यदि आपको "somedomain.ru/catalog.html" और "somedomain.ru/catalog/product.html" जैसे साइट पृष्ठों को क्रॉल करने की आवश्यकता है, तो इस स्थिति में आप अधिकतम गहराई मान = 2 सेट करने की आवश्यकता है।
- अनुरोधों के बीच देरी
- जब स्कैनर साइट के पेजों को एक्सेस करता है तो पॉज़ सेट करने का काम करता है। यह "कमजोर" होस्टिंग वाली साइटों के लिए आवश्यक हो सकता है जो भारी भार और उन तक लगातार पहुंच का सामना नहीं कर सकते।
- ब्रेक का अनुरोध
- किसी प्रोग्राम अनुरोध के लिए साइट प्रतिक्रिया की प्रतीक्षा करने के लिए समय निर्धारित करें। यदि साइट के कुछ पृष्ठ धीरे-धीरे प्रतिक्रिया करते हैं (लोड होने में लंबा समय लेते हैं), तो साइट को स्कैन करने में काफी लंबा समय लग सकता है। ऐसे पृष्ठों को एक मान निर्दिष्ट करके काटा जा सकता है, जिसके बाद क्रॉलर साइट के शेष पृष्ठों को क्रॉल करने के लिए आगे बढ़ेगा और इस प्रकार समग्र प्रगति में देरी नहीं करेगा।
- क्रॉल किए गए साइट पृष्ठों की संख्या
- स्कैन किए गए पृष्ठों की अधिकतम संख्या सीमित करें। यह उपयोगी हो सकता है, उदाहरण के लिए, आपको किसी साइट के पहले N पृष्ठों को क्रॉल करने की आवश्यकता है (यह छवियों, शैली फ़ाइलों, स्क्रिप्ट और अन्य प्रकार की फ़ाइलों को ध्यान में नहीं रखता है)।

सामग्री पर विचार करें
- इस खंड में, आप उन डेटा के प्रकारों का चयन कर सकते हैं जिन्हें पार्सर द्वारा पृष्ठों (छवियों, वीडियो, शैलियों, स्क्रिप्ट) को क्रॉल करते समय ध्यान में रखा जाएगा, या पार्स करते समय अनावश्यक जानकारी को बाहर कर सकते हैं।
स्कैन नियम
- "robots.txt" फ़ाइल का उपयोग करके, "nofollow" प्रकार के लिंक का उपयोग करके साइट को क्रॉल करते समय, साथ ही साथ साइट पृष्ठों के कोड में सीधे "मेटा नाम = रोबोट" निर्देशों का उपयोग करते समय ये सेटिंग्स अपवादों के लिए सेटिंग्स से संबंधित हैं।

इस खंड का उपयोग मुख्य विश्लेषण किए गए एसईओ मापदंडों को इंगित करने के लिए किया जाता है, जिसे बाद में पृष्ठों को पार्स करते समय शुद्धता के लिए जांचा जाएगा, जिसके बाद परिणामी आंकड़े मुख्य कार्यक्रम विंडो के दाहिने हिस्से में "एसईओ सांख्यिकी" टैब पर प्रदर्शित होंगे।
इन सेटिंग्स का उपयोग करके, आप एक ऐसी सेवा का चयन कर सकते हैं जिसके माध्यम से यांडेक्स सर्च इंजन में पेज इंडेक्सिंग की जाँच की जाएगी। अनुक्रमण की जाँच के लिए दो विकल्प हैं: «a href="https://xml.yandex.ru/settings/" target="_blank" rel="nofollow"»Yandex XML«/a» सेवा या «a href="http://www.majento.ru/index.php?page=account-tasks/xml_options_help" target="_blank" rel="nofollow"»Majento.ru«/a» सेवा का उपयोग करना।

"यांडेक्स एक्सएमएल" सेवा चुनते समय, आपको संभावित प्रतिबंधों (प्रति घंटा या दैनिक) को ध्यान में रखना होगा जो आपके यांडेक्स खाते पर मौजूदा सीमाओं के सापेक्ष पृष्ठों के अनुक्रमण की जांच करते समय लागू किया जा सकता है, जिसके परिणामस्वरूप स्थितियां हो सकती हैं अक्सर तब उत्पन्न होता है जब आपकी खाता सीमा एक बार में सभी पृष्ठों की जाँच करने के लिए पर्याप्त नहीं होगी और इसके लिए आपको अगले घंटे तक प्रतीक्षा करनी होगी।
Mazento.ru सेवा का उपयोग करते समय, व्यावहारिक रूप से कोई प्रति घंटा या दैनिक सीमा नहीं होती है, क्योंकि आपकी सीमा सचमुच सीमा के सामान्य पूल में बहती है, जो अपने आप में छोटा नहीं है, और किसी भी की तुलना में प्रति घंटा सीमा के लिए काफी बड़ी सीमा है। यैंडेक्स पर व्यक्तिगत उपयोगकर्ता खाते। एक्सएमएल"।

साइट पर होस्ट किए गए वास्तविक robots.txt के बजाय वर्चुअल robots.txt का उपयोग किया जा सकता है।
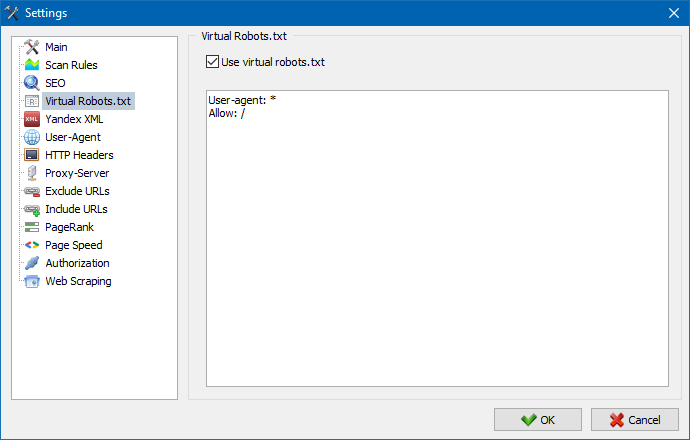
साइट का परीक्षण करते समय यह सुविधाजनक हो सकता है, जब, उदाहरण के लिए, आपको साइट के कुछ अनुभागों को क्रॉल करने की आवश्यकता होती है जो अनुक्रमण से बंद हैं (या इसके विपरीत - क्रॉल करते समय उन्हें ध्यान में न रखें), जबकि आपको भौतिक रूप से आवश्यकता नहीं है वास्तविक robots.txt में परिवर्तन करें और इस पर डेवलपर का समय बर्बाद करें।
वर्चुअल रोबोट्स.txt प्रोग्राम सेटिंग्स में संग्रहीत है और सभी परियोजनाओं के लिए सामान्य है।
उपयोगकर्ता-एजेंट अनुभाग में, आप निर्दिष्ट कर सकते हैं कि स्कैन के दौरान बाहरी साइटों तक पहुँचने पर प्रोग्राम किस उपयोगकर्ता एजेंट का प्रतिनिधित्व करेगा। डिफ़ॉल्ट रूप से, एक कस्टम उपयोगकर्ता एजेंट स्थापित होता है, लेकिन यदि आवश्यक हो, तो आप इंटरनेट पर सबसे अधिक पाए जाने वाले मानक एजेंटों में से एक का चयन कर सकते हैं। उनमें से इस प्रकार हैं: खोज इंजन के बॉट YandexBot, GoogleBot, MicrosoftEdge, ब्राउज़रों के bots क्रोम, फ़ायरफ़ॉक्स, IE8, साथ ही साथ मोबाइल डिवाइस iPhone, Android और कई अन्य।

इस विकल्प का उपयोग करके, आप विभिन्न अनुरोधों पर साइट और पृष्ठों की प्रतिक्रिया का विश्लेषण कर सकते हैं। उदाहरण के लिए, किसी को अनुरोध में एक रेफरर भेजने की आवश्यकता हो सकती है, बहुभाषी साइटों के मालिक एक्सेप्ट-लैंग्वेज|चारसेट|एन्कोडिंग भेजना चाहेंगे, और किसी को एक्सेप्ट-एन्कोडिंग, कैश-कंट्रोल, प्राग्मा हेडर में असामान्य डेटा भेजने की आवश्यकता हो सकती है। , आदि पी.
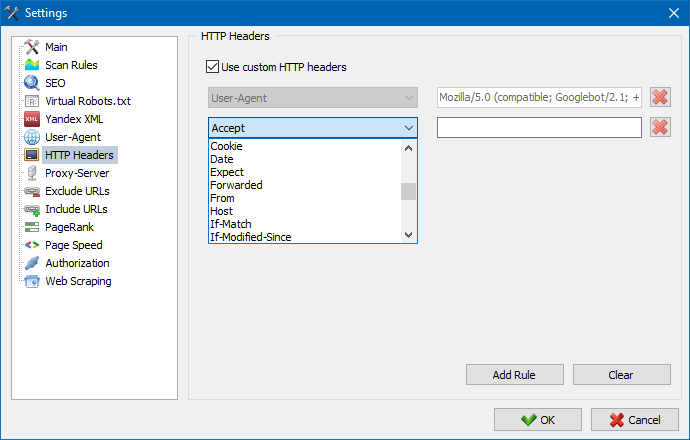
इस विकल्प का उपयोग करके, आप विभिन्न अनुरोधों पर साइट और पृष्ठों की प्रतिक्रिया का विश्लेषण कर सकते हैं। उदाहरण के लिए, किसी को अनुरोध में एक रेफरर भेजने की आवश्यकता हो सकती है, बहुभाषी साइटों के मालिक एक्सेप्ट-लैंग्वेज|चारसेट|एन्कोडिंग भेजना चाहेंगे, और किसी को एक्सेप्ट-एन्कोडिंग, कैश-कंट्रोल, प्राग्मा हेडर में असामान्य डेटा भेजने की आवश्यकता हो सकती है। , आदि पी.
यदि प्रॉक्सी के माध्यम से काम करने की आवश्यकता है, तो इस खंड में आप प्रॉक्सी सर्वर की एक सूची जोड़ सकते हैं जिसके माध्यम से प्रोग्राम बाहरी संसाधनों तक पहुंच प्राप्त करेगा। इसके अतिरिक्त, संचालन के लिए प्रॉक्सी की जांच करना संभव है, साथ ही निष्क्रिय प्रॉक्सी सर्वर को हटाने का कार्य भी संभव है।

इस अनुभाग को पार्स करते समय साइट के कुछ पृष्ठों और अनुभागों को बायपास करने से बचने के लिए डिज़ाइन किया गया है।
खोज पैटर्न * और ? का उपयोग करना आप निर्दिष्ट कर सकते हैं कि साइट के किन वर्गों को स्कैनर द्वारा क्रॉल नहीं किया जाना चाहिए और, तदनुसार, प्रोग्राम डेटाबेस में शामिल नहीं किया जाना चाहिए। यह सूची साइट स्कैनिंग के समय के लिए एक स्थानीय बहिष्करण सूची है (इसके सापेक्ष, "वैश्विक" सूची साइट रूट में "robots.txt" फ़ाइल है)।

इसी तरह, यह आपको ऐसे URL जोड़ने की अनुमति देता है जिन्हें क्रॉल किया जाना चाहिए। इस मामले में, स्कैनिंग के दौरान इन फ़ोल्डरों के बाहर के अन्य सभी URL को अनदेखा कर दिया जाएगा। यह विकल्प खोज पैटर्न * और ? के साथ भी काम करता है।

पेजरैंक पैरामीटर का उपयोग करके, आप अपनी साइटों की नेविगेशनल संरचना का विश्लेषण कर सकते हैं, साथ ही सबसे महत्वपूर्ण पृष्ठों पर लिंक जूस को स्थानांतरित करने के लिए वेब संसाधन के आंतरिक लिंकिंग सिस्टम को अनुकूलित कर सकते हैं।

पेजरैंक की गणना के लिए कार्यक्रम में दो विकल्प हैं: क्लासिक एल्गोरिथम और इसके अधिक आधुनिक समकक्ष। सामान्य तौर पर, किसी साइट के आंतरिक लिंकिंग के विश्लेषण के लिए, पहले या दूसरे एल्गोरिदम का उपयोग करते समय बहुत अंतर नहीं होता है, इसलिए आप दो प्रस्तावित एल्गोरिदम में से किसी का भी उपयोग कर सकते हैं।
पेजरैंक की गणना के लिए एल्गोरिदम और सिद्धांतों के विस्तृत विवरण के लिए, इस लेख को पढ़ें: >>

.htpasswd के माध्यम से बंद किए गए और बेसिक सर्वर प्राधिकरण द्वारा संरक्षित पृष्ठों पर स्वचालित प्राधिकरण के लिए लॉगिन और पासवर्ड दर्ज करना।
कार्यक्रम के साथ काम करना
स्कैनिंग पूरी होने के बाद, "बेसिक डेटा" ब्लॉक में रखी गई जानकारी उपयोगकर्ता के लिए उपलब्ध हो जाती है। प्रत्येक टैब में उनके शीर्षकों द्वारा समूहीकृत डेटा होता है (उदाहरण के लिए, "शीर्षक" टैब में पृष्ठ शीर्षकों की सामग्री होती है«title»«/title» , "छवियां" टैब में साइट की सभी छवियों की एक सूची होती है, और इसी तरह)। इस डेटा का उपयोग करके, आप साइट की सामग्री का विश्लेषण कर सकते हैं, "टूटे हुए" लिंक या गलत तरीके से भरे मेटा टैग ढूंढ सकते हैं।

यदि आवश्यक हो (उदाहरण के लिए, साइट पर परिवर्तन करने के बाद), संदर्भ मेनू का उपयोग करके, आप कार्यक्रम में परिवर्तन प्रदर्शित करने के लिए अलग-अलग URL को फिर से स्कैन कर सकते हैं।
उसी मेनू का उपयोग करके, आप प्रासंगिक मापदंडों (डुप्लिकेट शीर्षक, विवरण, कीवर्ड, h1, h2, पृष्ठ सामग्री) के अनुसार डुप्लिकेट पृष्ठ प्रदर्शित कर सकते हैं।

आइटम "कोड 0 के साथ URL को फिर से क्रॉल करें" को स्वचालित रूप से उन सभी पृष्ठों की फिर से जाँच करने के लिए डिज़ाइन किया गया है जो प्रतिक्रिया कोड 0 (रीड टाइमआउट) लौटाते हैं। यह प्रतिक्रिया कोड आमतौर पर तब दिया जाता है जब सर्वर के पास सामग्री वापस करने का समय नहीं होता है और कनेक्शन टाइमआउट तक बंद हो जाता है, क्रमशः, पृष्ठ लोड नहीं किया जा सकता है और इससे जानकारी नहीं निकाली जा सकती है।
अब आप चुन सकते हैं कि मुख्य डेटा इंटरफ़ेस में कौन से टैब प्रदर्शित होंगे (आखिरकार, अप्रचलित मेटा कीवर्ड टैब को अलविदा कहना संभव हो गया)। यह उपयोगी है यदि टैब स्क्रीन पर फिट नहीं होते हैं, या आप शायद ही कभी उनका उपयोग करते हैं।

स्तम्भों को भी छिपाया जा सकता है या खींचकर वांछित स्थान पर ले जाया जा सकता है।
मुख्य डेटा पैनल पर संदर्भ मेनू को कॉल करके टैब और कॉलम के प्रदर्शन को कॉन्फ़िगर किया जा सकता है। माउस का उपयोग करके कॉलम को स्थानांतरित किया जाता है।
साइट आँकड़ों के अधिक सुविधाजनक विश्लेषण के लिए, कार्यक्रम में डेटा फ़िल्टरिंग उपलब्ध है। निस्पंदन दो संस्करणों में उपलब्ध है:
- "त्वरित" फ़िल्टर का उपयोग करके किसी भी फ़ील्ड द्वारा
- कस्टम फ़िल्टर का उपयोग करना (उन्नत डेटा नमूनाकरण सेटिंग का उपयोग करना)
त्वरित फ़िल्टर
डेटा को त्वरित रूप से फ़िल्टर करने और वर्तमान टैब के सभी क्षेत्रों में एक साथ लागू करने के लिए उपयोग किया जाता है।

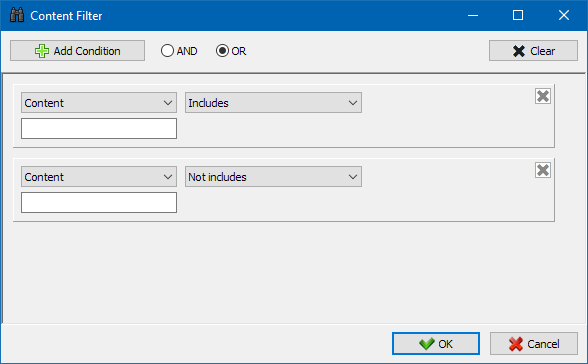
कस्टम फ़िल्टर
विस्तृत फ़िल्टरिंग के लिए डिज़ाइन किया गया है और इसमें एक ही समय में कई शर्तें हो सकती हैं। उदाहरण के लिए, मेटा टैग "शीर्षक" के लिए आप पृष्ठों को उनकी लंबाई से फ़िल्टर करना चाहते हैं ताकि यह 70 वर्णों से अधिक न हो और साथ ही साथ "समाचार" टेक्स्ट भी शामिल हो। फिर फिल्टर इस तरह दिखेगा:

इस प्रकार, किसी भी टैब पर कस्टम फ़िल्टर लागू करके, आप किसी भी जटिलता के डेटा नमूने प्राप्त कर सकते हैं।
साइट का तकनीकी सांख्यिकी टैब "अतिरिक्त डेटा" पैनल पर स्थित है और इसमें साइट के मुख्य तकनीकी मानकों का एक सेट शामिल है: लिंक, मेटा टैग, पृष्ठ प्रतिक्रिया कोड, पृष्ठ अनुक्रमण पैरामीटर, सामग्री प्रकार इत्यादि पर आंकड़े। पैरामीटर।
किसी एक पैरामीटर पर क्लिक करके, वे साइट के मुख्य डेटा के संबंधित टैब में स्वचालित रूप से फ़िल्टर हो जाते हैं, और आंकड़े भी एक साथ पृष्ठ के निचले भाग में आरेख पर प्रदर्शित होते हैं।

SEO आँकड़े टैब पूर्ण साइट ऑडिट के लिए डिज़ाइन किया गया है और इसमें 50+ बुनियादी SEO पैरामीटर शामिल हैं और 60 से अधिक प्रमुख आंतरिक अनुकूलन गलतियों की पहचान करता है! त्रुटियों का प्रदर्शन समूहों में बांटा गया है, जो बदले में, विश्लेषण किए गए पैरामीटर और फ़िल्टर के सेट होते हैं जो साइट पर त्रुटियों का पता लगाते हैं।
इस लेख में सभी जाँच किए गए मापदंडों का विस्तृत विवरण पाया जा सकता है: >>

सभी फ़िल्टरिंग परिणाम अतिरिक्त संवादों के बिना एक्सेल में जल्दी से निर्यात किए जा सकते हैं (रिपोर्ट प्रोग्राम के साथ फ़ोल्डर में सहेजी जाती है)।
इस टैब में प्रीसेट फ़िल्टर हैं जो आपको सभी बाहरी लिंक, 404 त्रुटियों, छवियों और अन्य पैरामीटर के लिए चयन करने की अनुमति देते हैं, जिन पर वे मौजूद हैं। इस प्रकार, अब आप आसानी से और जल्दी से बाहरी लिंक और उन पृष्ठों की सूची प्राप्त कर सकते हैं जिन पर वे स्थित हैं, या सभी टूटे हुए लिंक का चयन करें और तुरंत देखें कि वे किन पृष्ठों पर स्थित हैं।

कार्यक्रम में सभी रिपोर्ट ऑनलाइन उपलब्ध हैं और मुख्य डेटा पैनल के "कस्टम" टैब पर प्रदर्शित की जाती हैं। इसके अतिरिक्त, उन्हें मुख्य मेनू के माध्यम से एक्सेल में निर्यात करना संभव है।
साइट पर सामग्री खोज सुविधा आपको स्रोत कोड के माध्यम से खोज करने और उन वेब पृष्ठों को प्रदर्शित करने की अनुमति देती है जिनमें वह सामग्री है जिसे आप ढूंढ रहे हैं।
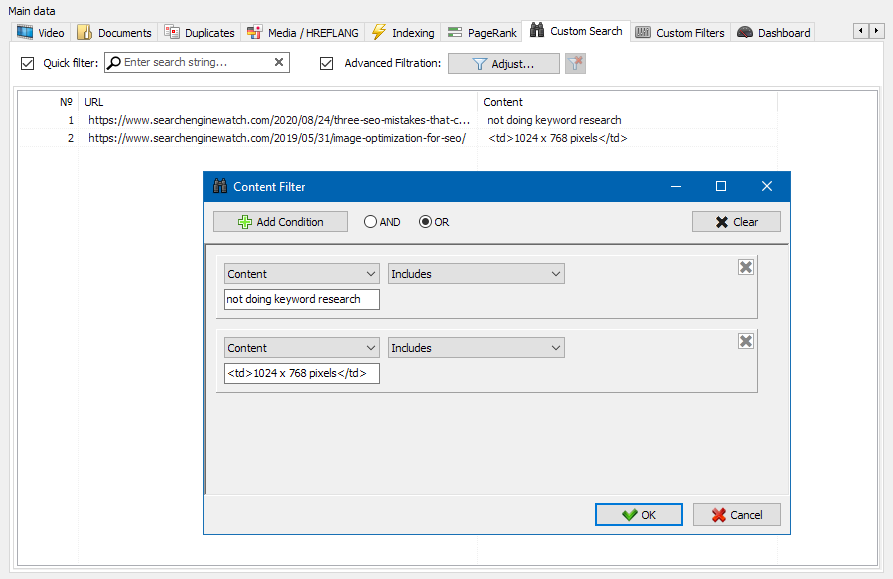
कस्टम फ़िल्टर मॉड्यूल आपको साइट पर माइक्रो-मार्कअप, मेटा टैग, एनालिटिक्स सिस्टम, मनमाने टेक्स्ट के टुकड़े या HTML कोड की उपस्थिति की जांच करने की अनुमति देता है।
फ़िल्टर कॉन्फ़िगरेशन विंडो में साइट पृष्ठों पर विशिष्ट टेक्स्ट अंशों की खोज करने के लिए कई विकल्प हैं, या, इसके विपरीत, खोज परिणामों से विशिष्ट टेक्स्ट या HTML कोड फ़्रैगमेंट वाले पृष्ठों को बाहर करने के लिए (यह फ़ंक्शन पृष्ठ स्रोत कोड में सामग्री की खोज के समान है Ctrl-एफ)।
स्क्रैपिंग आमतौर पर उन कार्यों को हल करता है जिन्हें मैन्युअल रूप से संभालना मुश्किल होता है। यह एक नया ऑनलाइन स्टोर बनाने के लिए उत्पाद विवरण निकालने, कीमतों की निगरानी के लिए विपणन अनुसंधान में स्क्रैपिंग या विज्ञापनों की निगरानी करने के लिए हो सकता है।

SiteAnalyzer में, "डेटा एक्सट्रैक्शन" टैब स्क्रैपिंग सेट करने के लिए ज़िम्मेदार है, जिसमें निष्कर्षण नियम कॉन्फ़िगर किए गए हैं। नियमों को सहेजा जा सकता है और, यदि आवश्यक हो, संपादित किया जा सकता है।
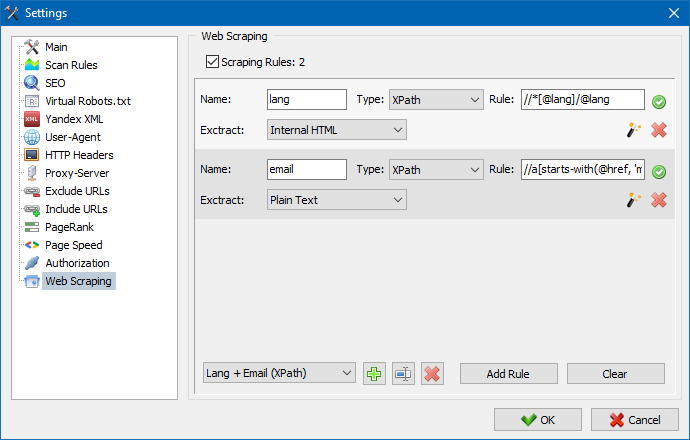
एक नियम परीक्षण मॉड्यूल भी है। अंतर्निहित नियम डीबगर का उपयोग करके, आप साइट पर किसी भी पृष्ठ की HTML सामग्री को जल्दी और आसानी से प्राप्त कर सकते हैं और अनुरोधों के संचालन का परीक्षण कर सकते हैं, और फिर साइट एनालाइज़र में डेटा पार्स करने के लिए डीबग किए गए नियमों का उपयोग कर सकते हैं।

डेटा निष्कर्षण पूरा होने के बाद, सभी एकत्रित जानकारी एक्सेल को निर्यात की जा सकती है।
आप मॉड्यूल के संचालन के बारे में अधिक जान सकते हैं और लेख में सबसे सामान्य नियमों और नियमित अभिव्यक्तियों की सूची से परिचित हो सकते हैं
सामग्री की विशिष्टता की जाँच करना
यह टूल आपको डुप्लीकेट पृष्ठों की खोज करने और साइट के भीतर टेक्स्ट की विशिष्टता की जांच करने की अनुमति देता है। दूसरे शब्दों में, यह आपस में विशिष्टता के लिए URL के समूह का बैच चेक है।
यह मामलों में उपयोगी हो सकता है:
- पूर्ण पृष्ठ डुप्लीकेट खोजने के लिए (उदाहरण के लिए, पैरामीटर वाला पृष्ठ और एक ही पृष्ठ, लेकिन सीएनसी के रूप में)।
- आंशिक सामग्री मिलान खोजने के लिए (उदाहरण के लिए, एक खाद्य ब्लॉग पर दो बोर्स्च व्यंजन जो एक दूसरे के समान 96% हैं, जो सुझाव देता है कि संभावित ट्रैफ़िक नरभक्षण से छुटकारा पाने के लिए लेखों में से एक को हटा दिया जाना चाहिए)।
- जब आपने किसी लेख साइट पर गलती से किसी ऐसे विषय पर लेख लिखा था जिसे आपने 10 साल पहले ही लिखा था। इस मामले में, हमारा टूल ऐसे लेख के डुप्लिकेट का भी पता लगाएगा।
सामग्री विशिष्टता जाँच उपकरण के संचालन का सिद्धांत सरल है: साइट URL की सूची के अनुसार, कार्यक्रम उनकी सामग्री को डाउनलोड करता है, पृष्ठ की पाठ्य सामग्री प्राप्त करता है (बिना HEAD ब्लॉक और HTML टैग के), और फिर उनकी तुलना करता है एक दूसरे को शिंगल एल्गोरिथम का उपयोग करते हुए।

इस प्रकार, दाद की मदद से, हम पृष्ठों की विशिष्टता का निर्धारण करते हैं और 0% विशिष्टता के साथ पूर्ण पृष्ठ डुप्लिकेट और टेक्स्ट सामग्री विशिष्टता की विभिन्न डिग्री के साथ आंशिक डुप्लिकेट दोनों की गणना कर सकते हैं। कार्यक्रम 5 की लंबाई के साथ काम करता है।
आप इस लेख में मॉड्यूल के संचालन के बारे में अधिक जान सकते हैं।: >>
सर्च दिग्गज Google का पेजस्पीड इनसाइट्स टूल आपको कुछ पेज तत्वों की लोडिंग गति की जांच करने की अनुमति देता है, और ब्राउज़र के डेस्कटॉप और मोबाइल संस्करणों के लिए रुचि के URL के समग्र लोड स्पीड स्कोर को भी दिखाता है।

Google टूल सभी के लिए अच्छा है, हालांकि, इसकी एक महत्वपूर्ण खामी है - यह आपको समूह URL चेक बनाने की अनुमति नहीं देता है, जो आपकी साइट के कई पृष्ठों की जाँच करते समय असुविधा पैदा करता है: आपको यह स्वीकार करना होगा कि मैन्युअल रूप से 100 के लिए डाउनलोड गति की जाँच करना या एक पृष्ठ पर अधिक URL एक घर का काम है और इसमें बहुत समय लग सकता है।
इसलिए, हमने एक मॉड्यूल बनाया है जो आपको Google पेजस्पीड इनसाइट्स टूल में एक विशेष एपीआई के माध्यम से पेज लोडिंग स्पीड की मुफ्त ग्रुप चेक बनाने की अनुमति देता है।

मुख्य विश्लेषण पैरामीटर:
- FCP (First Contentful Paint) – पहली सामग्री का प्रदर्शन समय।
- SI (Speed Index) – एक पृष्ठ पर सामग्री कितनी जल्दी प्रस्तुत की जाती है इसका एक उपाय।
- LCP (Largest Contentful Paint) – सबसे बड़े पृष्ठ तत्व का प्रदर्शन समय।
- TTI (Time to Interactive) – वह समय जिसके दौरान पृष्ठ उपयोगकर्ता सहभागिता के लिए पूरी तरह से तैयार हो जाता है।
- TBT (Total Blocking Time) – सामग्री के पहले प्रतिपादन से लेकर उपयोगकर्ता सहभागिता के लिए उसकी तैयारी तक का समय।
- CLS (Cumulative Layout Shift) – संचयी लेआउट शिफ्ट। एक पृष्ठ की दृश्य स्थिरता को मापने के लिए कार्य करता है।
उसी समय, URL विश्लेषण स्वयं कुछ ही क्लिक में होता है, जिसके बाद एक रिपोर्ट उपलब्ध होती है जिसमें एक्सेल में सुविधाजनक रूप में चेक की मुख्य विशेषताएं शामिल होती हैं।
आरंभ करने के लिए आपको केवल एक API कुंजी प्राप्त करने की आवश्यकता है।
यह कैसे करना है इस लेख में वर्णित है। >>
यह कार्यक्षमता प्राप्त डेटा के आधार पर साइट संरचना बनाने के लिए डिज़ाइन की गई है। साइट संरचना पृष्ठ URL के नेस्टिंग के आधार पर उत्पन्न होती है। संरचना उत्पन्न करने के बाद, सीएसवी प्रारूप (एक्सेल) में इसका निर्यात उपलब्ध है।

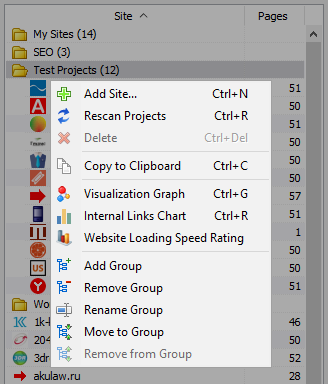
- आवश्यक साइटों का चयन करके और "Rescan" बटन पर क्लिक करके परियोजनाओं की सूची में बल्क स्कैनिंग उपलब्ध है। उसके बाद, सभी साइटों को मानक मोड में एक-एक करके कतारबद्ध और स्कैन किया जाता है।
- साथ ही, कार्यक्रम के साथ काम करने की सुविधा के लिए, "हटाएं" बटन पर क्लिक करके चयनित साइटों का सामूहिक विलोपन भी उपलब्ध है।
- एकल साइट स्कैनिंग के अलावा, एक विशेष फॉर्म का उपयोग करके परियोजनाओं की सूची में साइटों को बड़े पैमाने पर जोड़ने की संभावना है, जिसके बाद उपयोगकर्ता रुचि की संपूर्ण परियोजनाओं को स्कैन कर सकता है।
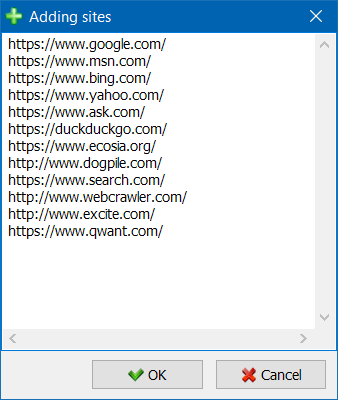
- परियोजनाओं की सूची के माध्यम से अधिक सुविधाजनक नेविगेशन के लिए, साइटों को फ़ोल्डरों में समूहित करने की क्षमता उपलब्ध है, साथ ही नाम से परियोजनाओं की सूची को फ़िल्टर करना भी उपलब्ध है।

ग्राफ़ पर लिंक विज़ुअलाइज़ेशन मोड एसईओ विशेषज्ञ को साइट के पृष्ठों पर आंतरिक पेजरैंक के वितरण का मूल्यांकन करने में मदद करेगा, साथ ही यह भी समझेगा कि किन पृष्ठों को एक बड़ा लिंक द्रव्यमान प्राप्त होता है (और, तदनुसार, खोज इंजन की नज़र में अधिक आंतरिक लिंक वजन) , और साइट के किन पृष्ठों और अनुभागों में आंतरिक लिंक की कमी नहीं है।

साइट संरचना विज़ुअलाइज़ेशन मोड का उपयोग करके, एक एसईओ विशेषज्ञ नेत्रहीन यह आकलन करने में सक्षम होगा कि साइट पर आंतरिक लिंकिंग कैसे व्यवस्थित की जाती है, और साथ ही, कुछ पृष्ठों को सौंपे गए पेजरैंक द्रव्यमान के दृश्य प्रतिनिधित्व के कारण, वर्तमान साइट लिंकिंग में जल्दी से समायोजन करते हैं। और इस प्रकार रुचि के पृष्ठों की प्रासंगिकता में वृद्धि होती है।
विज़ुअलाइज़ेशन विंडो के बाएं हिस्से में ग्राफ़ के साथ काम करने के लिए मुख्य उपकरण हैं:
- ग्राफ़ पर पैमाना बदलना
- एक मनमाना कोण द्वारा ग्राफ का घूर्णन
- ग्राफ़ विंडो को पूर्ण स्क्रीन मोड में बदलना (F11 कुंजी के साथ भी काम करता है)
- नोड लेबल दिखाएं/छुपाएं (Ctrl-T)
- लाइनों के पास तीर दिखाएँ/छिपाएँ
- बाहरी संसाधनों के लिंक दिखाएं/छुपाएं (Ctrl-E)
- रंग मोड स्विच करना दिन / रात (Ctrl-D)
- ग्राफ़ लेजेंड और आंकड़े दिखाएं/छुपाएं (Ctrl-L)
- ग्राफ़ को पीएनजी प्रारूप में सहेजना (Ctrl-S)
- विज़ुअलाइज़ेशन सेटिंग्स विंडो (Ctrl-O)
"व्यू" अनुभाग ग्राफ़ पर नोड्स के प्रदर्शन स्वरूप को बदलने के लिए अभिप्रेत है। "पेजरैंक" नोड ड्राइंग मोड में, नोड्स के आकार को उनके पहले परिकलित पेजरैंक के सापेक्ष सेट किया जाता है, जिसके परिणामस्वरूप एक ग्राफ दिखाता है कि किन पेजों को सबसे अधिक लिंक वजन मिलता है और कौन से कम लिंक प्राप्त करते हैं।
क्लासिक मोड में, विज़ुअलाइज़ेशन ग्राफ़ के चयनित पैमाने के सापेक्ष नोड आकार निर्धारित किए जाते हैं।
यह ग्राफ़ साइट के पृष्ठों पर आंतरिक लिंक द्रव्यमान के वितरण को दर्शाता है (हम कह सकते हैं कि यह विज़ुअलाइज़ेशन ग्राफ़ पर प्रस्तुत किए जाने के बजाय विज़ुअल रूप में लिंकिंग का एक विज़ुअलाइज़ेशन है)। अधिक पढ़ें >>
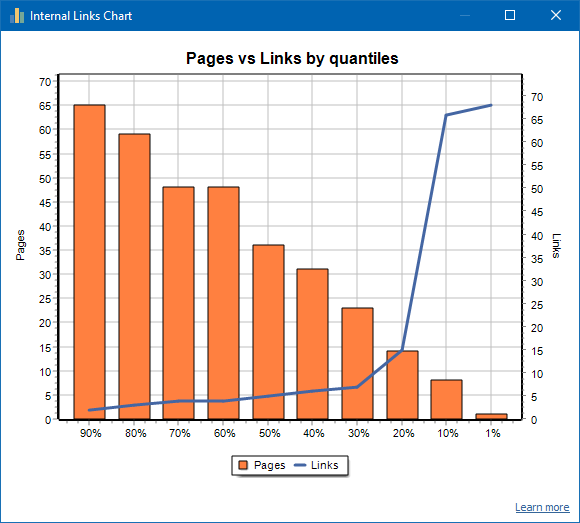
पृष्ठों की संख्या बाईं ओर प्रदर्शित होती है, लिंक की संख्या दाईं ओर प्रदर्शित होती है। पृष्ठ के अनुसार प्रतिशत मात्राएँ नीचे दी गई हैं। ग्राफ़ बनाते समय, डुप्लिकेट लिंक को छोड़ दिया जाता है (यदि पेज ए से पेज बी तक 3 लिंक हैं, तो हम उन्हें एक के रूप में गिनते हैं)।
उदाहरण के लिए, ऊपर दिए गए स्क्रीनशॉट के आधार पर, लगभग 70 पृष्ठों वाली साइट के लिए:
- 1% पन्ने है ~68 आने वाली कड़ियाँ.
- 10% पन्ने है ~66 आने वाली कड़ियाँ.
- 20% पन्ने है ~15 आने वाली कड़ियाँ.
- 30% पन्ने है ~8 आने वाली कड़ियाँ.
- 40% पन्ने है ~7 आने वाली कड़ियाँ.
- 50% पन्ने है ~6 आने वाली कड़ियाँ.
- 60% पन्ने है ~5 आने वाली कड़ियाँ.
- 70% पन्ने है ~5 आने वाली कड़ियाँ.
- 80% पन्ने है ~3 आने वाली कड़ियाँ.
- 90% पन्ने है ~2 आने वाली कड़ियाँ.
यही है, अगर हम देखते हैं कि हमारे पास ऐसे पृष्ठ हैं जिन पर 10 से कम आने वाले लिंक लीड करते हैं, तो हम ऐसे पृष्ठों को कमजोर रूप से लिंक कर सकते हैं, और हमारे पास 60% पृष्ठ हैं जो सामान्य रूप से जुड़े हुए हैं। इसके आधार पर, हम इन कमजोर रूप से लिंक किए गए पृष्ठों (यदि पृष्ठ प्रचार के लिए महत्वपूर्ण हैं) के लिए और अधिक आंतरिक लिंक डाल सकते हैं, या यदि ऐसे पृष्ठ कम महत्व और कम प्राथमिकता वाले हैं तो उन्हें वैसे ही छोड़ दें।
सामान्य तौर पर, 10 से कम आंतरिक लिंक वाले पृष्ठों को खोज रोबोट द्वारा क्रॉल किए जाने की संभावना कम होती है, विशेष रूप से, Google बॉट।
इसलिए, यदि आप ऐसी साइट देखते हैं जिसमें साइट पर कुल पृष्ठों की संख्या से सामान्य रूप से केवल 20-30% पृष्ठ जुड़े हुए हैं, तो लिंकिंग सेट अप करने या इन 80-70% से निपटने के तरीके के बारे में सोचने के लिए समझ में आता है। खराब लिंक किए गए पृष्ठों का (हटाएं, अनुक्रमण से छिपाएं, पुनर्निर्देशित करें)।
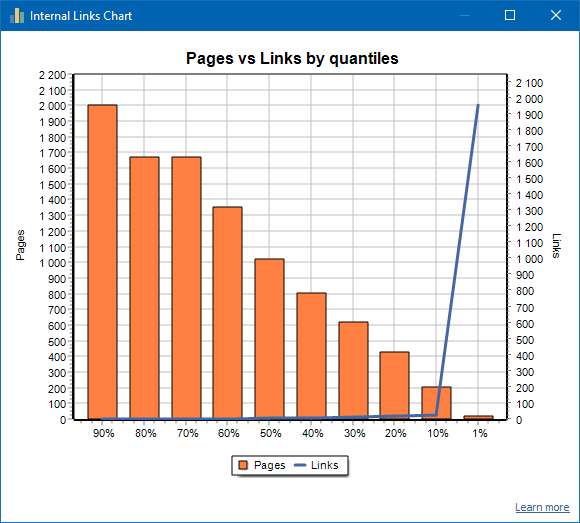
कमजोर रूप से लिंक की गई साइट का एक उदाहरण:
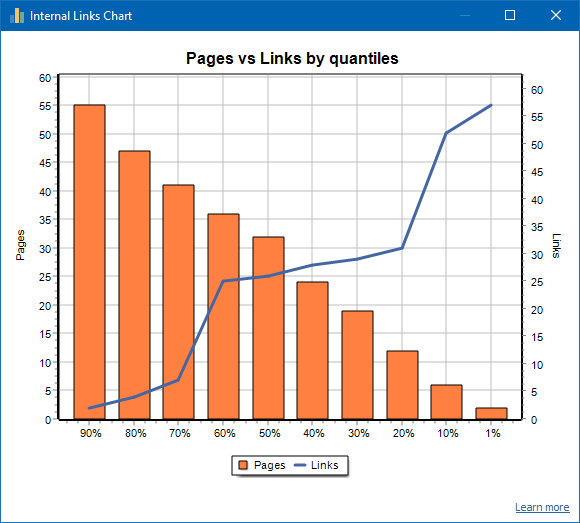
एक अच्छी तरह से लिंक की गई साइट का एक उदाहरण:
पृष्ठ लोडिंग गति ग्राफ आपको साइट के प्रदर्शन का मूल्यांकन करने की अनुमति देता है। स्पष्टता के लिए, पृष्ठों को 100 मिलीसेकंड के एक चरण के साथ समूहों और समय अंतरालों में विभाजित किया जाता है।
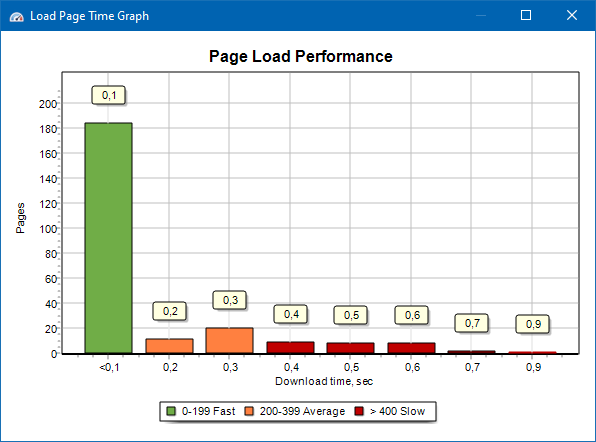
इस प्रकार, ग्राफ़ के आधार पर, यह निर्धारित करना संभव है कि साइट के पृष्ठों का कितना अनुपात जल्दी से लोड होता है (0-100 मिलीसेकंड के भीतर), कौन से पृष्ठ औसत गति (100-200 मिलीसेकंड) पर लोड होते हैं, और कौन से पृष्ठ अधिक समय लेते हैं लोड करने का समय (400 मिलीसेकंड या अधिक)।
नोट: दिखाया गया समय HTML स्रोत कोड लोड करने का समय है, न कि पूर्ण पृष्ठ लोड करने का समय (पृष्ठ प्रतिपादन, साथ ही पृष्ठ तत्व लोड हो रहा है, जैसे छवियों और शैलियों को ध्यान में नहीं रखा जाता है)।
साइटमैप.एक्सएमएल पीढ़ी
साइटमैप स्कैन किए गए पृष्ठों या साइट छवियों के आधार पर उत्पन्न होता है।
- पृष्ठों से युक्त साइटमैप बनाते समय, इसमें "टेक्स्ट/एचटीएमएल" प्रारूप के पृष्ठ जोड़े जाते हैं।
- छवियों से युक्त साइटमैप बनाते समय, इसमें JPG, PNG, GIF और इसी तरह के प्रारूपों की छवियां जोड़ी जाती हैं।
आप मुख्य मेनू के माध्यम से साइट को स्कैन करने के तुरंत बाद साइटमैप तैयार कर सकते हैं: आइटम "प्रोजेक्ट्स -> साइटमैप जेनरेट करें"।

बड़ी मात्रा में साइटों के लिए, 50,000 पृष्ठों से, "साइटमैप.एक्सएमएल" को कई फाइलों में स्वचालित रूप से विभाजित करने का एक कार्य है (इस मामले में, मुख्य फ़ाइल में साइट पृष्ठों के सीधे लिंक वाले अतिरिक्त लिंक होते हैं)। यह बड़ी साइटमैप फ़ाइलों को संसाधित करने के लिए खोज इंजनों की आवश्यकताओं के कारण है।

यदि आवश्यक हो, तो "sitemap.xml" फ़ाइल में पृष्ठों की मात्रा को 50,000 के मान (डिफ़ॉल्ट रूप से सेट) को मुख्य प्रोग्राम सेटिंग्स में वांछित मान में बदलकर भिन्न किया जा सकता है।
मनमाने ढंग से URL क्रॉल करना
"आयात यूआरएल" मेनू आइटम को यूआरएल की मनमानी सूचियों को स्कैन करने के लिए डिज़ाइन किया गया है, साथ ही साथ एक्सएमएल साइटमैप साइटमैप.एक्सएमएल (इंडेक्स वाले सहित) उनके बाद के विश्लेषण के लिए।
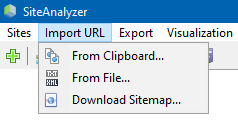
मनमाने ढंग से URL क्रॉल करना तीन तरीकों से संभव है:
- क्लिपबोर्ड से URL की सूची चिपकाकर
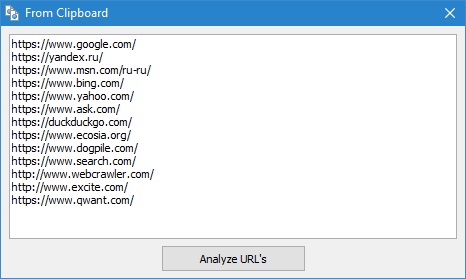
- हार्ड डिस्क से URL की सूची वाली *.txt और *.xml फ़ाइलें लोड करना
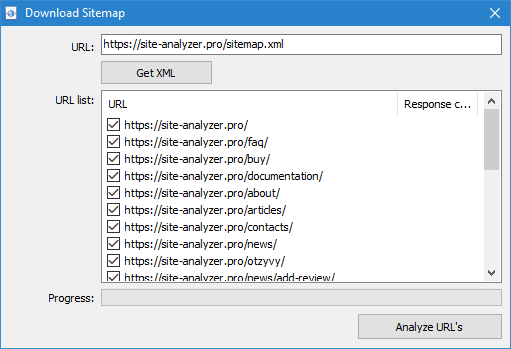
- साइट से सीधे साइटमैप.एक्सएमएल फ़ाइल डाउनलोड करके
इस मोड की एक विशेषता यह है कि मनमाने ढंग से URL स्कैन करते समय, "प्रोजेक्ट" स्वयं प्रोग्राम में सहेजा नहीं जाता है और उस पर डेटा डेटाबेस में नहीं जोड़ा जाता है। "साइट संरचना" और "डैशबोर्ड" अनुभाग भी उपलब्ध नहीं हैं।
आप इस लेख में "आयात URL" आइटम के संचालन के बारे में अधिक जान सकते हैं: नए संस्करण का अवलोकन SiteAnalyzer 1.9.
Dashboard
"डैशबोर्ड" टैब साइट अनुकूलन की वर्तमान गुणवत्ता पर एक विस्तृत रिपोर्ट प्रदर्शित करता है। रिपोर्ट "एसईओ सांख्यिकी" टैब के डेटा के आधार पर तैयार की जाती है। इन आंकड़ों के अलावा, रिपोर्ट में समग्र साइट अनुकूलन गुणवत्ता सूचकांक का एक संकेत होता है, जिसकी गणना इसके अनुकूलन की वर्तमान डिग्री के सापेक्ष 100-बिंदु पैमाने पर की जाती है। पीडीएफ प्रारूप में सुविधाजनक रिपोर्ट में "डैशबोर्ड" टैब से डेटा निर्यात करना संभव है।

डेटा निर्यात
प्राप्त डेटा के अधिक लचीले विश्लेषण के लिए, उन्हें CSV प्रारूप (वर्तमान सक्रिय टैब निर्यात किया जाता है) में अपलोड करना संभव है, साथ ही Microsoft Excel में एक फ़ाइल में सभी टैब के साथ एक पूर्ण रिपोर्ट तैयार करना संभव है।

एक्सेल में डेटा निर्यात करते समय, एक विशेष विंडो दिखाई देती है जिसमें उपयोगकर्ता रुचि के कॉलम का चयन कर सकता है और फिर आवश्यक डेटा के साथ एक रिपोर्ट तैयार कर सकता है।

बहुभाषी
कार्यक्रम में पसंदीदा भाषा का चयन करने की क्षमता है जिसमें काम किया जाएगा।
मुख्य समर्थित भाषाएं: रूसी, अंग्रेजी, जर्मन, इतालवी, स्पेनिश, फ्रेंच... फिलहाल, कार्यक्रम का पंद्रह (15) से अधिक सबसे लोकप्रिय भाषाओं में अनुवाद किया गया है।

यदि आप प्रोग्राम को अपनी मूल भाषा में अनुवाद करना चाहते हैं, तो किसी भी "*.lng" फ़ाइल को रुचि की भाषा में अनुवाद करने के लिए पर्याप्त है, जिसके बाद अनुवादित फ़ाइल को "support@site-analyzer.pro" पते पर भेजा जाना चाहिए। " (पत्र पर टिप्पणियाँ रूसी या अंग्रेजी में लिखी जानी चाहिए) और आपका अनुवाद कार्यक्रम की नई रिलीज़ में शामिल किया जाएगा।
कार्यक्रम को भाषाओं में अनुवाद करने के लिए अधिक विस्तृत निर्देश वितरण किट (फ़ाइल "lcids.txt") में पाए जा सकते हैं।
PS यदि अनुवाद की गुणवत्ता पर आपकी कोई टिप्पणी है, तो कृपया "support@site-analyzer.ru" पर टिप्पणियाँ और सुधार भेजें।
डेटाबेस संपीड़न
मुख्य मेनू आइटम "कम्प्रेस डेटाबेस" को डेटाबेस को पैक करने के संचालन के लिए डिज़ाइन किया गया है (पहले हटाए गए प्रोजेक्ट से डेटाबेस की सफाई, साथ ही डेटा को व्यवस्थित करना (व्यक्तिगत कंप्यूटर पर डेटा को डीफ़्रैग्मेन्ट करना))।
यह प्रक्रिया तब प्रभावी होती है, जब, उदाहरण के लिए, बड़ी संख्या में रिकॉर्ड वाली एक बड़ी परियोजना को कार्यक्रम से हटा दिया गया हो। सामान्य तौर पर, अनावश्यक डेटा से छुटकारा पाने और डेटाबेस के आकार को कम करने के लिए समय-समय पर डेटा को संपीड़ित करने की अनुशंसा की जाती है।
अन्य प्रश्नों के उत्तर अक्सर पूछे जाने वाले प्रश्न अनुभाग में पाए जा सकते हैं। >>



















