






















 1,924
1,924Yinelenen sayfaların ve site içindeki metinlerin özgünlüğünün belirlenmesi konusu, teknik denetim çalışmaları listesindeki en önemli konulardan biridir. Yinelenen sayfaların varlığı, hem sitenin genel refahını hem de boşa gidebilecek arama motoru tarama bütçesinin dağılımını belirler ve genel olarak, büyük miktarda yinelenen içerik nedeniyle sitenin sıralamasında zorluklar yaşanabilir.

İnternetteki tek tek metinlerin benzersizliğini kontrol etmek için çok sayıda hizmet ve programı kolayca bulabilirseniz, sorunun kendisi önemli ve alakalı olmasına rağmen, kendi aralarında bir grup belirli URL'nin benzersizliğini kontrol etmek için pek çok benzer hizmet yoktur.
Sitede benzersiz olmayan içerikle ilgili sorunlar için hangi seçenekler olabilir?
1. Farklı URL'ler için aynı içerik.
Genellikle bu, parametrelere ve aynı sayfaya sahip bir sayfadır, ancak bir SEF (insan tarafından okunabilir URL) biçimindedir.
- Misal:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Bu, SEF'yi kurduktan sonra, programcı parametrelere sahip sayfalardan SEF'li sayfalara 301 yönlendirmesi ayarlamayı unuttuğunda oldukça yaygın bir sorundur.
Bu sorun, sitenin tüm sayfalarını karşılaştırdıktan sonra, ikisinin aynı karma kodlara (MD5) sahip olduğunu bulan ve optimize ediciye, görevi ayarlaması gereken aynı programcıya 301 yönlendirmelerini yüklemek için bilgi veren herhangi bir web tarayıcısı tarafından kolayca çözülebilir. SEF sayfalarına.
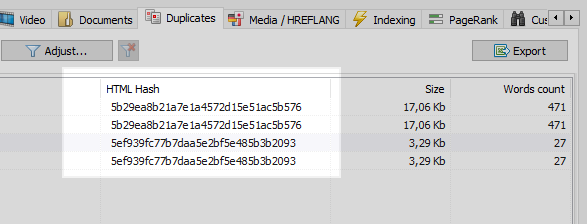
Ancak, her şey o kadar basit değil.
2. Örtüşen İçerik.
Benzer içerik, farklı sayfalarımız olduğunda, ancak aslında aynı veya benzer içerikle oluşturulur.
Misal 1
Plastik pencere satışı için web sitesinde, bir yıl önce haber bölümünde, bir metin yazarı 8 Mart'ta 500 karakter için bir tebrik yazdı ve plastik pencere montajında% 15 indirim yaptı.
Ve bu yıl, içerik yöneticisi "hile" yapmaya karar verdi ve daha fazla uzatmadan, önceden yayınlanan haberleri indirimlerle buldu, kopyaladı ve indirim boyutunu% 15'ten% 12'ye değiştirdi + ek tebriklerle kendisinden 50 işaret ekledi.
Bu nedenle, sonunda, neredeyse aynı olan,% 90 oranında benzer olan ve kendi içlerinde bulanık kopyalar olan iki metne sahibiz ve bunlardan biri, iyi bir nedenden ötürü acil bir yeniden yazım gerektirir.
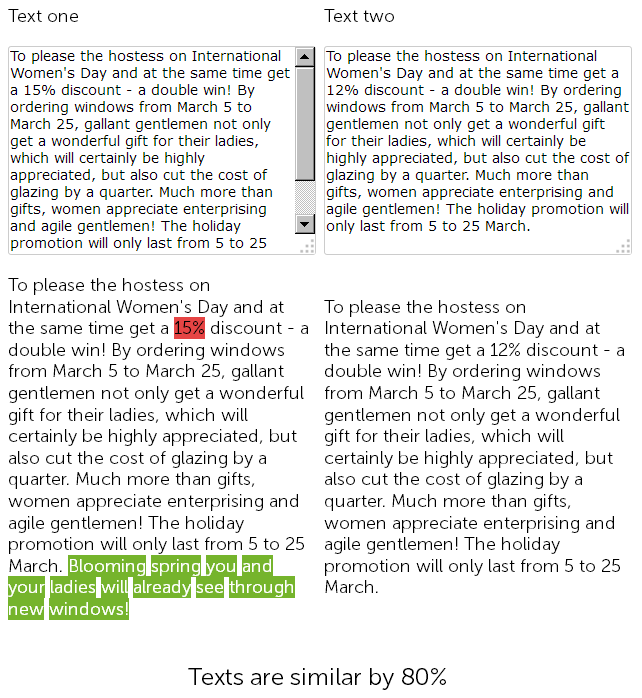
Aynı zamanda, teknik denetim hizmetleri için bu iki haber farklı olacaktır, çünkü sitedeki SEF zaten yapılandırılmıştır ve ne derse desin sayfaların sağlama toplamları eşleşmeyecektir.
Sonuçta hangi sayfanın daha iyi sıralanacağı büyük bir soru ...
Ama bunlar çok haber - hızlı bir şekilde modası geçme eğilimindeler, bu yüzden daha ilginç bir örnek ele alalım.
Misal 2
Sitenizde bir makale bölümünüz var veya hobiniz / hobiniz için kişisel bir sayfanız var, örneğin bu bir "mutfak blogu".
Ve örneğin, blogunuz tüm zaman boyunca, 100'den fazla, hatta birkaç yüzden fazla bir makale sırası biriktirdi. Ve böylece bir konu seçtiniz ve yeni bir makale yazdınız, yayınladınız ve daha sonra bir şekilde benzer bir makalenin 3 yıl önce yazılmış olduğunu keşfettiniz. Görünüşe göre, içeriği yazmadan önce, tüm başlıkları incelediniz, yayınlanan konuların bir listesiyle Excel'i açtınız, ancak "Evde sıcak çikolata nasıl yapılır" makalesinin geçmiş içeriğinin, henüz yazılan materyalle büyük ölçüde çakıştığını hesaba katmadınız. Ve çevrimiçi hizmetlerden birinde bu iki makaleyi kontrol ederken, kendi aralarında% 78 benzersiz oldukları ortaya çıkıyor; bu, elbette, iyi değil, çünkü kısmi çoğaltma nedeniyle, bu sayfalar ve arama motoru arasında arama sorgularının yamyamlığı var. bu tür kopyaları sıralarken sorular ve zorluklar ortaya çıkar.
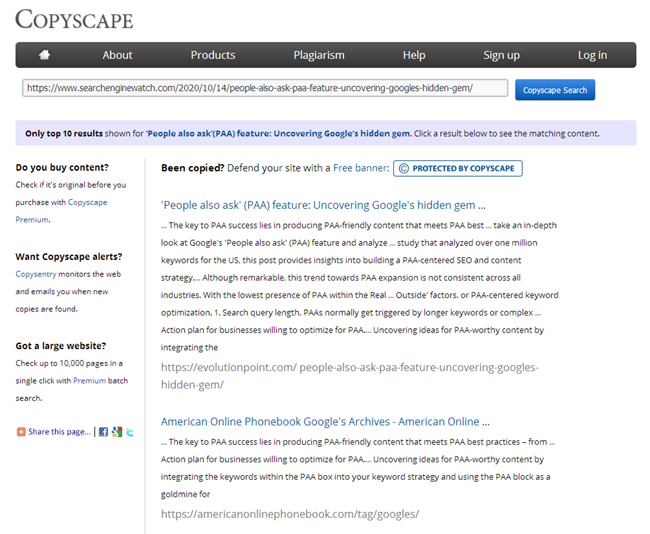
Tabii ki, bir makale yazdıktan sonra, her metin yazarının iyi bilinen hizmetlerden birinde benzersiz olup olmadığını kontrol etmesi gerekir ve her SEO, aynı hizmetlerde sitede yayınlandığında yeni içeriği kontrol etmekle yükümlüdür.
Ancak, bir web sitesi tanıtım için size yeni geldiyse ve tüm sayfalarını kopyalar için hızlıca kontrol etmeniz gerekiyorsa ne yapmalısınız? Veya blogunuzu açarken, aynı türden bir sürü makale yazdınız ve şimdi, büyük olasılıkla, onlar yüzünden site batmaya başladı. Çevrimiçi hizmetlerde 100.500 sayfayı el ile kontrol etmeyin, her makaleyi elle kontrol etmek için ekleyin ve üzerinde çok zaman harcayın.
BatchUniqueChecker
Bu nedenle, bir grup URL'nin kendi aralarında benzersiz olup olmadıklarını toplu olarak kontrol etmek için tasarlanmış BatchUniqueChecker programını oluşturduk.
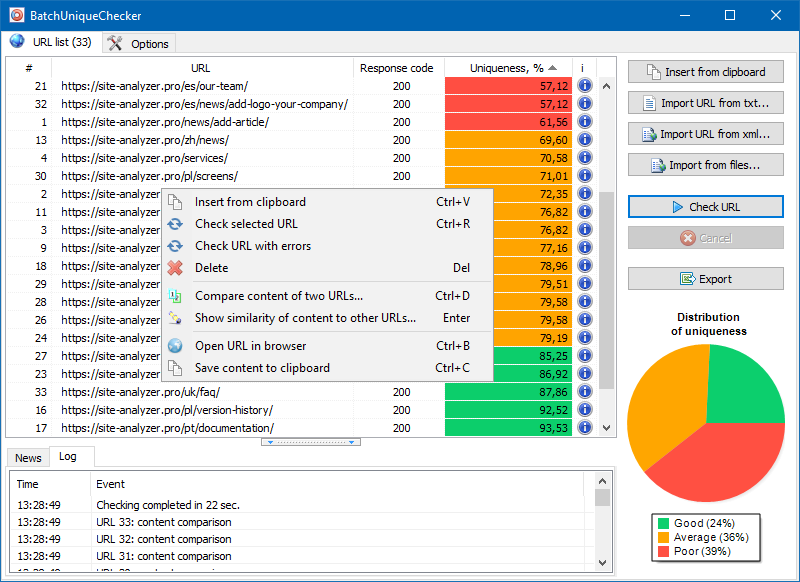
BatchUniqueChecker'ın çalışma prensibi basittir: program, içeriklerini önceden hazırlanmış bir URL listesi kullanarak indirir, PlainText'i alır (sayfanın HEAD bloğu ve HTML etiketleri olmadan metin içeriği) ve ardından bunları shingle algoritmasını kullanarak birbirleriyle karşılaştırır.
Bu nedenle, zona kullanarak sayfaların benzersizliğini belirleriz ve hem% 0 benzersizlikte sayfaların tam kopyalarını hem de metin içeriğinin farklı derecelerde benzersizliğine sahip kısmi kopyalarını hesaplayabiliriz.
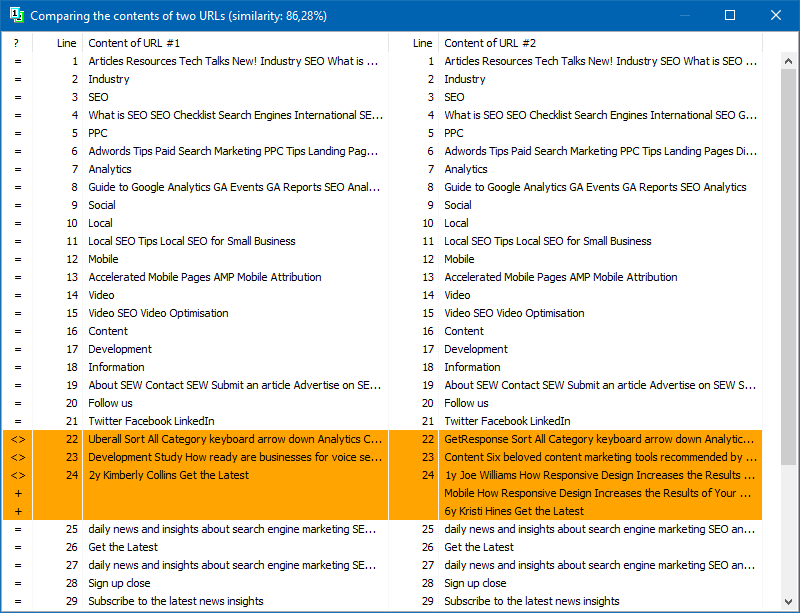
Program ayarlarında, shingle boyutunu manuel olarak ayarlayabilirsiniz (shingle, sağlama toplamı sonraki gruplarla dönüşümlü olarak karşılaştırılan metindeki kelime sayısıdır). Değeri = 4 olarak ayarlamanızı öneririz. 5 ve üzeri büyük miktarda metin için. Nispeten küçük hacimler için - 3-4.
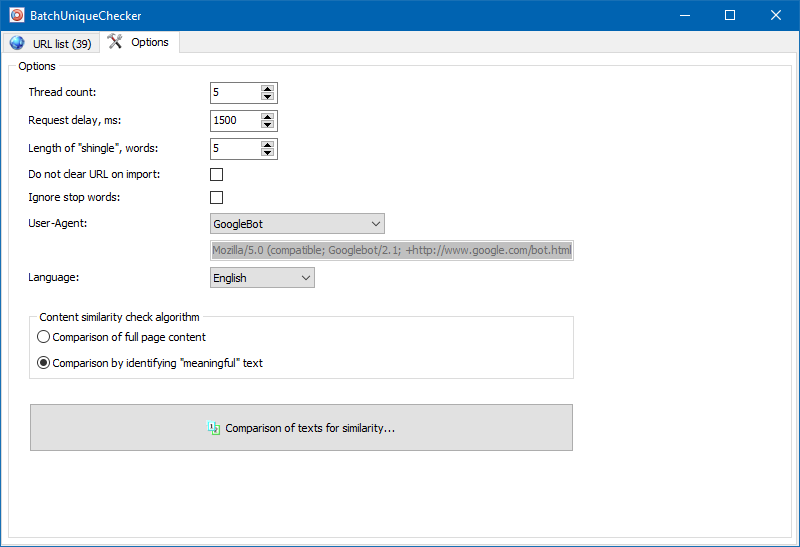
Anlamlı metinler
Program, içeriğin tam metin karşılaştırmasına ek olarak, sözde "önemli" metinlerin "akıllı" izolasyonu için bir algoritma içerir.
Yani sayfanın HTML kodundan yalnızca H1-H6, P, PRE ve LI etiketlerinde bulunan içeriği alıyoruz. Bu nedenle, örneğin site gezinme menüsündeki içerik, altbilgi veya yan menüdeki metin gibi "önemli olmayan" her şeyi bir sırayla atıyoruz.
Bu tür manipülasyonların bir sonucu olarak, yalnızca "anlamlı" sayfa içeriği elde ederiz ve bu içerik, karşılaştırıldığında, diğer sayfalarla daha doğru benzersiz sonuçlar gösterir.
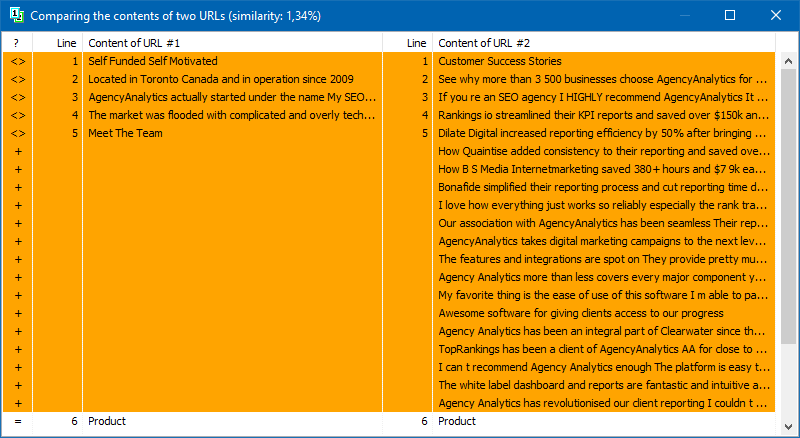
Sonraki analizleri için sayfaların listesi birkaç yolla eklenebilir: panodan yapıştırın, bir metin dosyasından yükleyin veya Sitemap.xml'den bilgisayarınızın diskinden içe aktarın.
Programın çok iş parçacıklı çalışması nedeniyle, yüzlerce veya daha fazla URL'nin kontrol edilmesi yalnızca birkaç dakika sürebilir; bu, çevrimiçi hizmetler aracılığıyla manuel modda bir gün veya daha uzun sürebilir.
Böylece, çıkarılabilir medyadan bile çalıştırılabilen bir grup URL için içeriğin benzersizliğini hızlı bir şekilde kontrol etmek için basit bir araç elde edersiniz.
BatchUniqueChecker ücretsizdir, arşivde yalnızca 4 MB yer kaplar ve kurulum gerektirmez.
Başlamanız gereken tek şey, dağıtım kitini indirmek ve ücretsiz bir teknik denetim programı aracılığıyla edinilebilecek, doğrulama için ilgilenilen URL'lerin bir listesini eklemektir. SiteAnalyzer.

Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Diğer makaleler



















