






















 3,520
3,520Kwestia określenia zduplikowanych stron i unikalności tekstów w serwisie jest jedną z najważniejszych na liście prac audytów technicznych. Obecność zduplikowanych stron decyduje zarówno o ogólnym dobrym samopoczuciu witryny, jak i o rozkładzie budżetu na indeksowanie w wyszukiwarce, który może zostać zmarnowany, a ogólnie rzecz biorąc, ranking witryny może napotkać trudności z powodu dużej ilości zduplikowanych treści.

A jeśli z łatwością można znaleźć dużą liczbę usług i programów do sprawdzania unikalności poszczególnych tekstów w Internecie, to nie ma wielu podobnych usług sprawdzających między sobą unikalność grupy konkretnych adresów URL, chociaż sam problem jest ważny i istotny.
Jakie opcje problemów z nieunikalną treścią mogą znajdować się w witrynie?
1. Ta sama treść dla różnych adresów URL.
Zwykle jest to strona z parametrami i ta sama strona, ale w formie SEF (adres URL czytelny dla człowieka).
- Przykład:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Jest to dość powszechny problem, gdy po skonfigurowaniu SEF programista zapomina ustawić przekierowanie 301 ze stron z parametrami do stron z SEF.
Ten problem może łatwo rozwiązać każdy robot sieciowy, który po porównaniu wszystkich stron witryny stwierdzi, że dwie z nich mają te same kody skrótu (MD5) i poinformuje optymalizatora, który będzie musiał ustawić zadanie, ten sam programista, aby zainstalować przekierowania 301 do stron SEF.
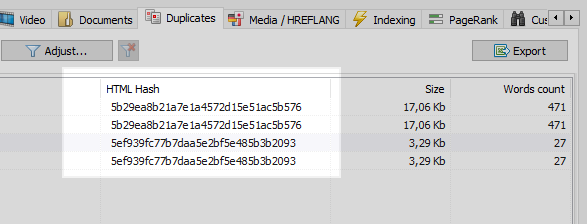
Jednak nie wszystko jest takie proste.
2. Nakładające się treści.
Podobna treść jest generowana, gdy mamy różne strony, ale w rzeczywistości z taką samą lub podobną zawartością.
Przykład 1
Na stronie sprzedaży okien plastikowych, w dziale aktualności, copywriter rok temu napisał 8 marca gratulacje za 500 znaków i udzielił 15% rabatu na montaż okien plastikowych.
I w tym roku menedżer treści postanowił "oszukiwać" i bez zbędnych ceregieli odnalazł opublikowane wcześniej newsy z rabatami, skopiował je i zmienił rabat z 15 na 12% + dodał 50 znaków od siebie z dodatkowymi gratulacjami.
Tak więc w końcu mamy dwa prawie identyczne teksty, w 90% podobne, które same w sobie są rozmytymi duplikatami, z których jeden nie bez powodu wymaga pilnego przepisania.
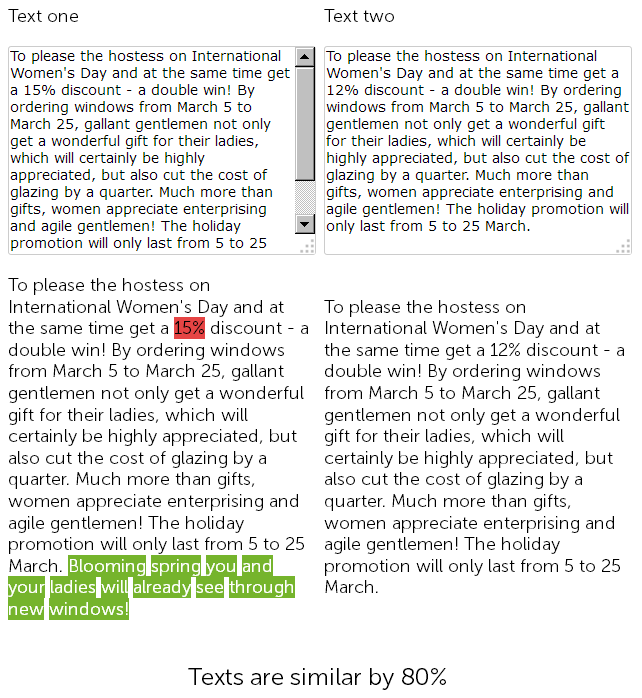
Jednocześnie w przypadku usług audytu technicznego te dwie wiadomości będą różne, ponieważ SEF na stronie zostało już skonfigurowane, a sumy kontrolne stron nie będą zgodne, cokolwiek można powiedzieć.
Ostatecznie, która strona będzie lepsza w rankingu, to duże pytanie ...
Ale to takie nowości - szybko się dezaktualizują, więc weźmy ciekawszy przykład.
Przykład 2
Masz sekcję artykułów w swojej witrynie lub prowadzisz osobistą stronę dotyczącą swojego hobby, na przykład jest to "blog kulinarny".
I na przykład Twój blog zgromadził już przez cały czas kolejność artykułów, ponad 100, a nawet kilkaset. Więc podjąłeś temat i napisałeś nowy artykuł, opublikowałeś, a później w jakiś sposób odkryłeś, że podobny artykuł został już napisany 3 lata temu. Choć wydawałoby się, że przed napisaniem treści przejrzałeś wszystkie tytuły, otworzyłeś Excel z listą opublikowanych tematów, ale nie wziąłeś pod uwagę, że dotychczasowa treść artykułu "Jak zrobić gorącą czekoladę w domu" mocno pokrywa się z właśnie napisanym materiałem. A sprawdzając te dwa artykuły w jednym z serwisów online, okazuje się, że są one w 78% unikalne między sobą, co oczywiście nie jest dobre, ponieważ z powodu częściowego powielania dochodzi do kanibalizacji zapytań wyszukiwania między tymi stronami, a wyszukiwarką pytania i trudności pojawiają się podczas oceniania takich duplikatów.
Oczywiście po napisaniu artykułu każdy copywriter musi sprawdzić go pod kątem unikalności w jednej ze znanych usług, a każdy SEO zobowiązany jest do sprawdzenia nowych treści umieszczanych na stronie w tych samych serwisach.
Ale co zrobić, jeśli witryna właśnie przyszła do Ciebie w celu promocji i musisz szybko sprawdzić wszystkie jej strony pod kątem duplikatów? Lub u zarania otwierania swojego bloga napisałeś kilka artykułów tego samego typu, a teraz, najprawdopodobniej z ich powodu, witryna zaczęła tonąć. Nie sprawdzaj ręcznie 100,500 stron w usługach online, dodając, aby sprawdzić każdy artykuł ręcznie i spędzając na nim dużo czasu.
BatchUniqueChecker
Dlatego stworzyliśmy program BatchUniqueChecker, przeznaczony do zbiorczego sprawdzania grupy adresów URL pod kątem unikalności między sobą.
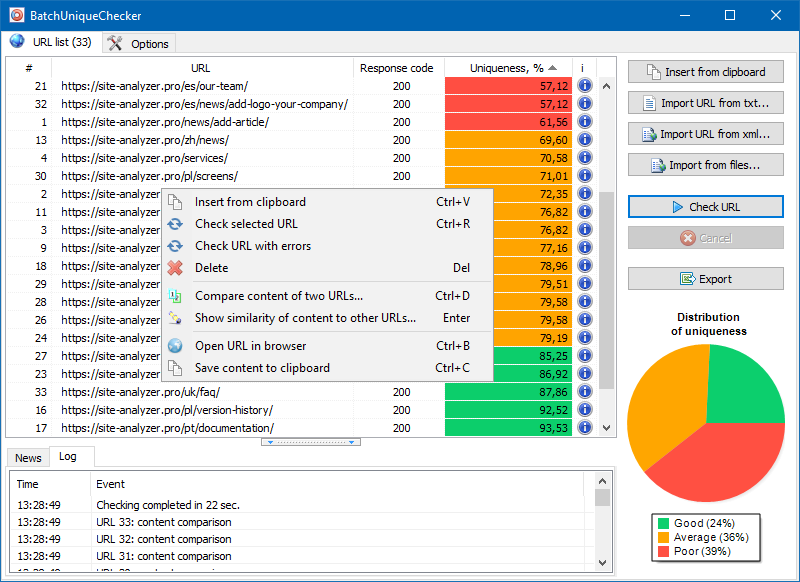
Zasada działania BatchUniqueChecker jest prosta: program pobiera ich zawartość za pomocą przygotowanej wcześniej listy adresów URL, otrzymuje PlainText (tekstową zawartość strony bez bloku HEAD i bez tagów HTML), a następnie porównuje je ze sobą za pomocą algorytmu shingle.
W ten sposób za pomocą gontów określamy niepowtarzalność stron i możemy obliczyć zarówno pełne duplikaty stron z niepowtarzalnością 0%, jak i częściowe duplikaty o różnym stopniu niepowtarzalności treści tekstowej.
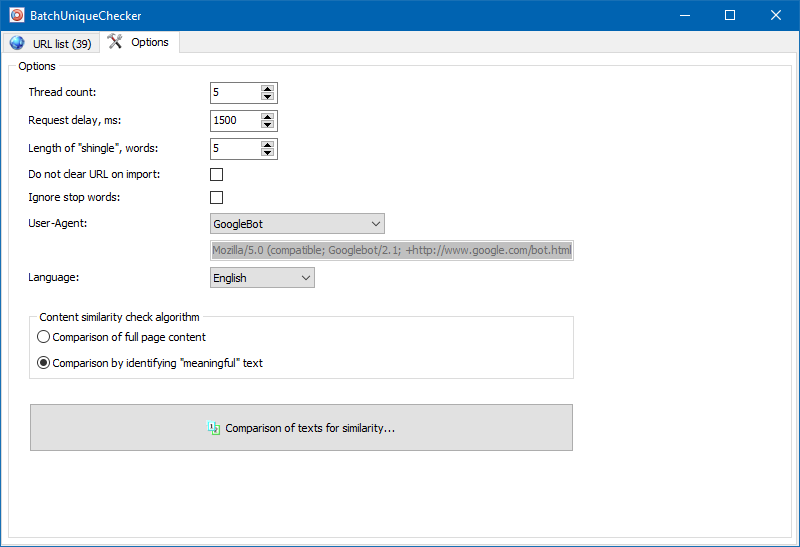
W ustawieniach programu można ręcznie ustawić wielkość gontu (gont to ilość słów w tekście, których suma kontrolna jest na przemian porównywana z kolejnymi grupami). Zalecamy ustawienie wartości = 4. W przypadku dużej ilości tekstu od 5 i więcej. Dla stosunkowo małych objętości - 3-4.
Znaczące teksty
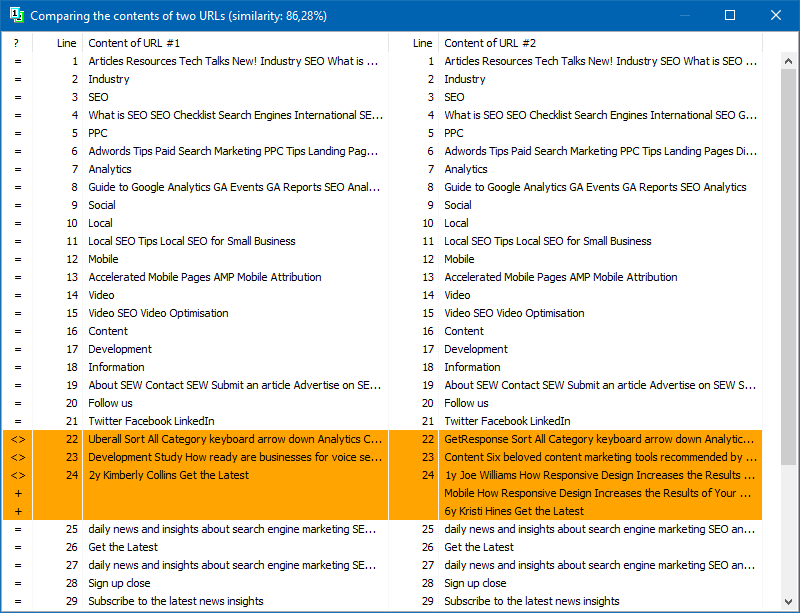
Oprócz pełnotekstowego porównywania treści program zawiera algorytm "inteligentnego" wyodrębniania tzw. "Znaczących" tekstów.
Oznacza to, że z kodu HTML strony otrzymujemy tylko treść zawartą w tagach H1-H6, P, PRE i LI. W związku z tym w pewnym sensie odrzucamy wszystko, co "nieistotne", na przykład treść z menu nawigacji witryny, tekst ze stopki lub menu bocznego.
W wyniku takich manipulacji otrzymujemy tylko "sensowną" zawartość strony, która w porównaniu z innymi stronami pokaże dokładniejsze wyniki o niepowtarzalności.
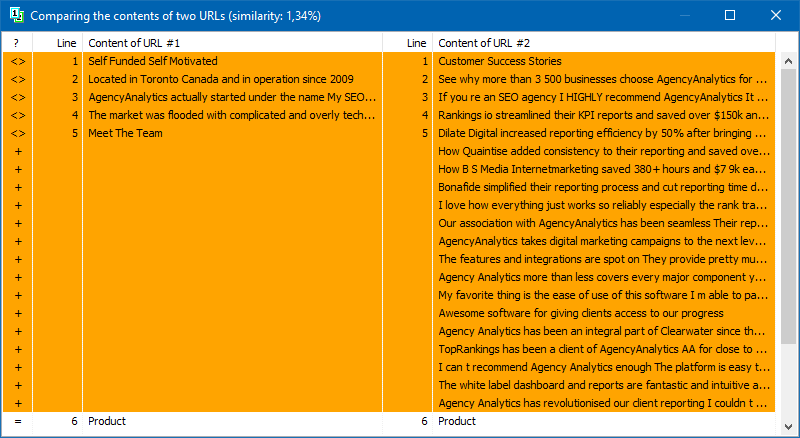
Listę stron do ich dalszej analizy można dodać na kilka sposobów: wkleić ze schowka, załadować z pliku tekstowego lub zaimportować z Sitemap.xml z dysku komputera.
Ze względu na wielowątkowość działania programu, sprawdzenie setek lub więcej adresów URL może zająć tylko kilka minut, co w trybie ręcznym za pośrednictwem usług online może zająć dzień lub dłużej.
W ten sposób otrzymujesz proste narzędzie do szybkiego sprawdzania niepowtarzalności treści dla grupy adresów URL, które można uruchomić nawet z nośników wymiennych.
BatchUniqueChecker jest darmowy, zajmuje tylko 4 MB w archiwum i nie wymaga instalacji.
Aby rozpocząć, wystarczy pobrać pakiet dystrybucyjny i dodać listę adresów URL do weryfikacji, które można uzyskać za pośrednictwem bezpłatnego programu audytu technicznego SiteAnalyzer.
Inne artykuły



















