






















 3,590
3,590重複ページの特定とサイト内のテキストの一意性の問題は、技術監査に関する作業のリストで最も重要なものの1つです。重複ページの存在は、サイトの全体的な状態と検索エンジンのクロール予算の配分の両方を決定します。これは無駄になる可能性があり、一般に、重複コンテンツが大量にあるため、サイトのランク付けが難しい場合があります。

また、インターネット上の個々のテキストの一意性をチェックするための多数のサービスやプログラムを簡単に見つけることができる場合、問題自体は重要で関連性がありますが、特定のURLのグループの一意性をチェックするための同様のサービスは多くありません。
一意でないコンテンツに関する問題のどのようなオプションがサイトにありますか?
1.異なるURLの同じコンテンツ。
通常、これはパラメータと同じページを含むページですが、SEF(人間が読み取れるURL)の形式です。
- 例:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
これは、SEFを設定した後、プログラマーがパラメーターのあるページからSEFのあるページへの301リダイレクトを設定するのを忘れた場合によくある問題です。
この問題は、サイトのすべてのページを比較したところ、2つが同じハッシュコード(MD5)を持っていることがわかり、タスクを設定する必要があるオプティマイザー、同じプログラマーに301リダイレクトをインストールするように通知するWebクローラーで簡単に解決できます。 SEFページへ。
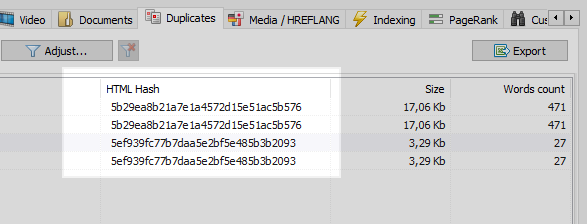
ただし、すべてがそれほど単純なわけではありません。
2.重複するコンテンツ。
異なるページがある場合でも同様のコンテンツが生成されますが、実際には、同じまたは類似のコンテンツが含まれています。
例 1
プラスチック製の窓を販売するウェブサイトのニュースセクションで、1年前のコピーライターが3月8日に500文字でお祝いの言葉を書き、プラスチック製の窓の設置を15%割引しました。
そして今年、コンテンツマネージャーは「ごまかす」ことを決定し、さらに苦労することなく、以前に投稿されたニュースを割引付きで見つけてコピーし、割引のサイズを15%から12%に変更し、さらにおめでとうございます。
したがって、最終的には2つのほぼ同一のテキストがあり、90%が類似しており、それ自体があいまいな複製であり、そのうちの1つは正当な理由で緊急の書き換えが必要です。
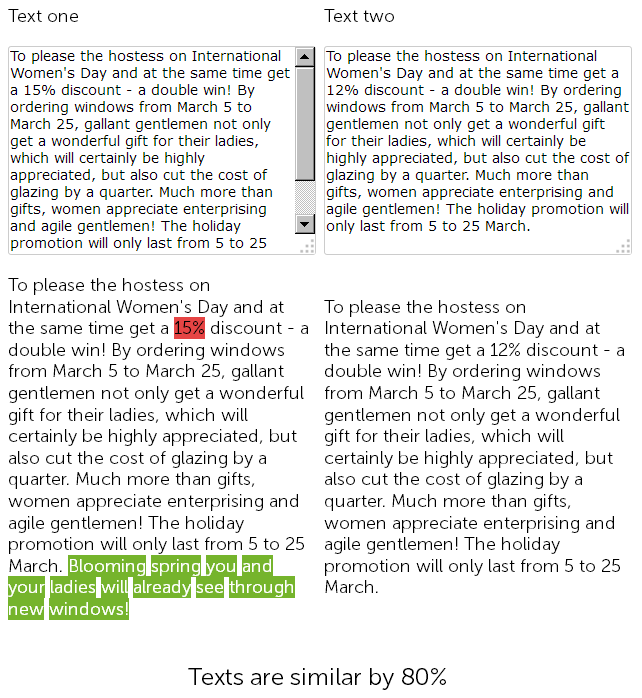
同時に、技術監査サービスの場合、SEFがサイトですでに構成されており、ページのチェックサムが一致しないため、これら2つのニュースは異なります。
結局、どのページがより良くランク付けされるかは大きな問題です...
しかし、それらはそのようなニュースです-それらはすぐに時代遅れになる傾向があるので、もっと興味深い例を見てみましょう。
例 2
あなたのサイトに記事セクションがあるか、あなたの趣味/趣味のための個人的なページを維持しています、例えば、それは「料理ブログ」です。
そして、例えば、あなたのブログはすでに100以上、あるいは数百もの記事の注文をずっと蓄積しています。それで、あなたはトピックを取り上げて新しい記事を書き、それを投稿しました、そして後でどういうわけか同じような記事がすでに3年前に書かれていることを発見しました。コンテンツを書く前に、すべてのタイトルに目を通し、投稿されたトピックのリストでExcelを開いたように見えますが、「自宅でホットチョコレートを作る方法」という記事の過去のコンテンツが今書いたものと強く一致していることを考慮していませんでした。そして、オンラインサービスの1つでこれらの2つの記事をチェックすると、それらは78%一意であることがわかります。これは、部分的な重複のために、これらのページと検索エンジンの間で検索クエリが共食いするため、もちろん良くありません。このような重複をランク付けすると、疑問や困難が生じます。
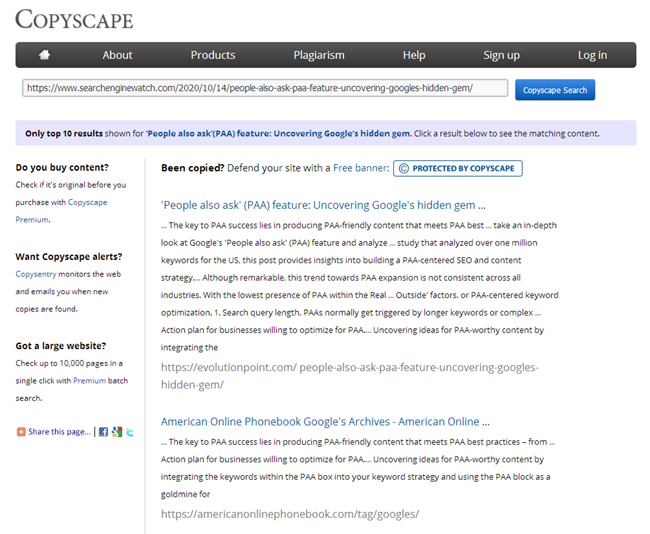
もちろん、記事を書いた後、すべてのコピーライターは有名なサービスの1つでその一意性をチェックする必要があり、すべてのSEOは、同じサービスのサイトに投稿されたときに新しいコンテンツをチェックする義務があります。
しかし、ウェブサイトが宣伝のためにあなたのところに来たばかりで、そのすべてのページに重複がないかすぐにチェックする必要がある場合はどうすればよいですか?または、ブログを開いた夜明けに、同じ種類の記事をたくさん書いたのですが、おそらくそれらのせいで、サイトが沈み始めました。オンラインサービスで100,500ページを手作業でチェックしないでください。各記事を手作業でチェックするために追加し、それに多くの時間を費やします。
BatchUniqueChecker
そのため、URLのグループの一意性をバッチチェックするように設計されたBatchUniqueCheckerプログラムを作成しました。
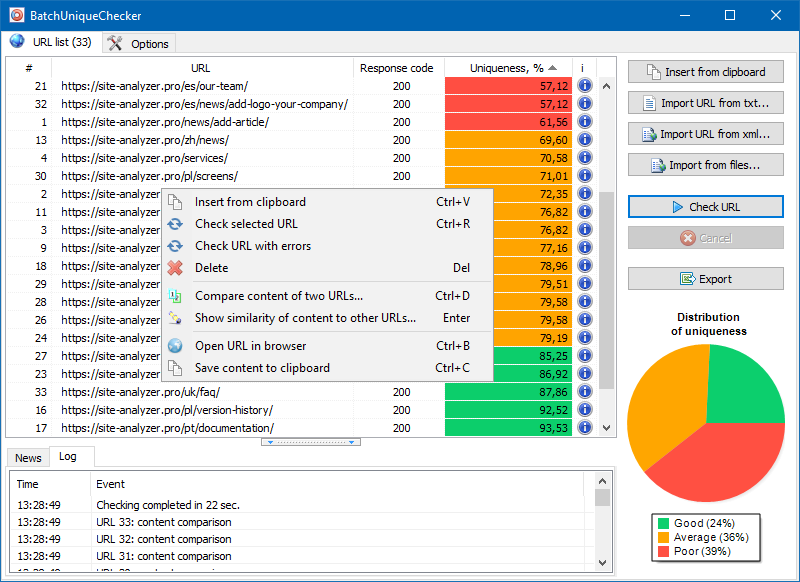
BatchUniqueCheckerの操作の原則は単純です。プログラムは、事前に準備されたURLのリストを使用してコンテンツをダウンロードし、PlainText(HEADブロックおよびHTMLタグのないページのテキストコンテンツ)を受信し、シングルアルゴリズムを使用してそれらを相互に比較します。
したがって、シングルを使用して、ページの一意性を判断し、一意性が0%のページの完全な複製と、テキストコンテンツの一意性の程度が異なる部分的な複製の両方を計算できます。
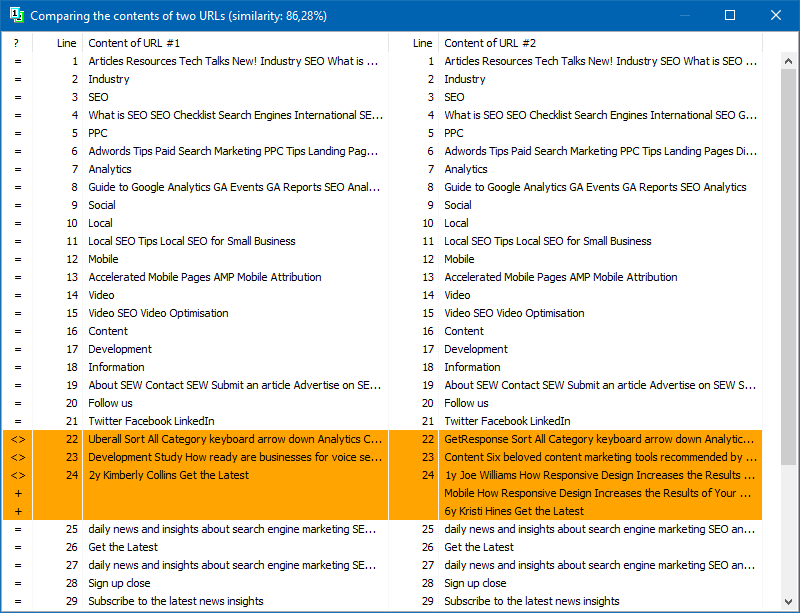
プログラム設定では、シングルのサイズを手動で設定できます(シングルはテキスト内の単語数であり、そのチェックサムは後続のグループと交互に比較されます)。値を4に設定することをお勧めします。5以上の大量のテキストの場合。比較的少量の場合-3-4。
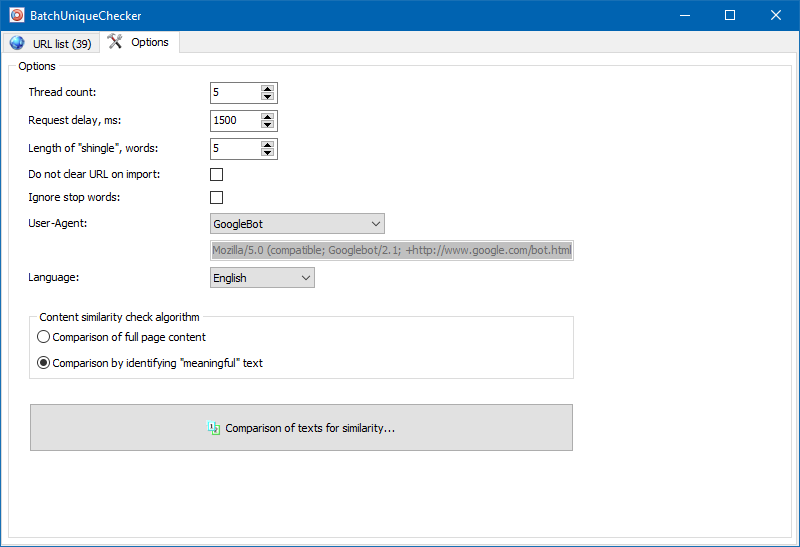
意味のあるテキスト
コンテンツの全文比較に加えて、プログラムには、いわゆる「重要な」テキストを「スマート」に分離するためのアルゴリズムが含まれています。
つまり、ページのHTMLコードから、タグH1-H6、P、PRE、およびLIに含まれるコンテンツのみを取得します。このため、サイトナビゲーションメニューのコンテンツ、フッターまたはサイドメニューのテキストなど、「重要ではない」すべてのものを破棄します。
このような操作の結果、「意味のある」ページコンテンツのみが取得され、比較すると、他のページとのより正確な一意性の結果が表示されます。
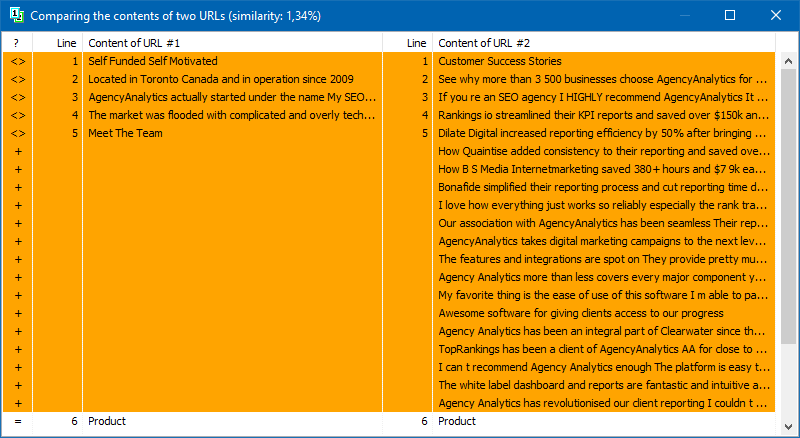
後続の分析用のページのリストは、クリップボードから貼り付ける、テキストファイルからロードする、またはコンピューターディスクからSitemap.xmlからインポートするなど、いくつかの方法で追加できます。
プログラムのマルチスレッド操作により、数百以上のURLのチェックにかかる時間はわずか数分で、手動モードではオンラインサービスを介して1日以上かかる場合があります。
したがって、URLのグループのコンテンツの一意性をすばやく確認するためのシンプルなツールを入手できます。これは、リムーバブルメディアからでも実行できます。
BatchUniqueChecker は無料で、アーカイブに4 MBしかかからず、インストールする必要はありません。
開始するために必要なのは、配布キットをダウンロードし、検証のために関心のあるURLのリストを追加することです。これは、無料の技術監査プログラムを通じて取得できます。 SiteAnalyzer.

Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →



















