





















 3,402
3,402大家好!我们恢复营业了!
时隔许久,我们终于准备了新版SiteAnalyzer,希望能满足大家的期待,成为SEO推广中不可或缺的助手。
在新版本的 SiteAnalyzer 中,我们实现了几个用户最需要的功能,例如:数据抓取(从站点中提取数据)、检查内容的唯一性以及通过 Google PageSpeed 检查页面加载速度。同时,修复了许多错误并重新设计了徽标。让我们更详细地讨论所有内容。

主要的变化
1. 使用 XPath、CSS、XQuery、RegEx 抓取数据。
网页抓取是根据某些规则从网站上感兴趣的页面中提取数据的自动化过程。
主要的网页抓取方法是使用 XPath、CSS 选择器、XQuery、RegExp 和 HTML 模板的解析方法。
- XPath 是一种用于 XML/XHTML 文档元素的特殊查询语言。为了访问元素,XPath 通过描述页面上所需元素的路径来使用 DOM 导航。在它的帮助下,您可以通过元素在文档中的序号获取其值,提取其文本内容或内部代码,检查页面上是否存在特定元素。
- CSS 选择器用于查找元素的一部分(属性)。 CSS 在语法上与 XPath 相似,但在某些情况下,CSS 定位器更快,更具描述性和简洁性。 CSS 的缺点是它只能在一个方向上起作用——深入到文档中。另一方面,XPath 可以双向工作(例如,您可以通过子元素搜索父元素)。
- XQuery 基于 XPath。 XQuery 模仿 XML,它允许您以 XSLT 中不可能的方式创建嵌套表达式。
- RegExp 是一种正式的搜索语言,用于从一组符合所需条件(正则表达式)的文本字符串中提取值。
- HTML 模板是一种用于从 HTML 文档中提取数据的语言,它是描述所需片段的搜索模板的 HTML 标记以及用于提取和转换数据的函数和操作的组合。
通常,抓取用于解决难以手动处理的任务。这可以是提取产品描述以创建新的在线商店,抓取营销研究以监控价格或监控广告。

在 SiteAnalyzer 中,抓取是在数据提取选项卡上配置的,其中配置了提取规则。可以保存规则,并在必要时进行编辑。
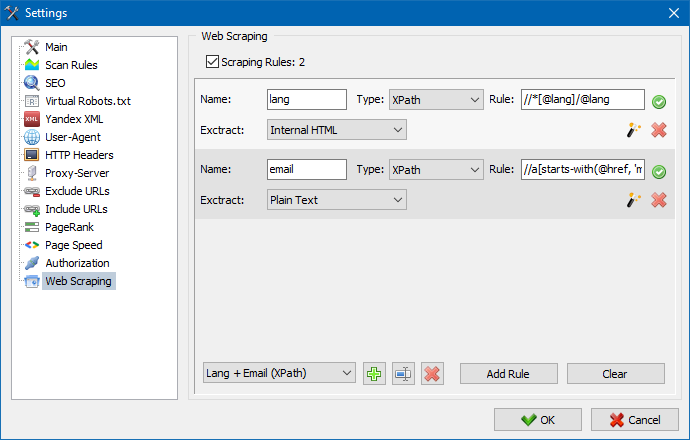
还有一个规则测试模块。使用内置的规则调试器,您可以快速轻松地获取站点上任何页面的HTML内容并测试查询的工作,然后使用调试后的规则在SiteAnalyzer中解析数据。

完成数据提取后,所有收集的信息都可以导出到Excel。
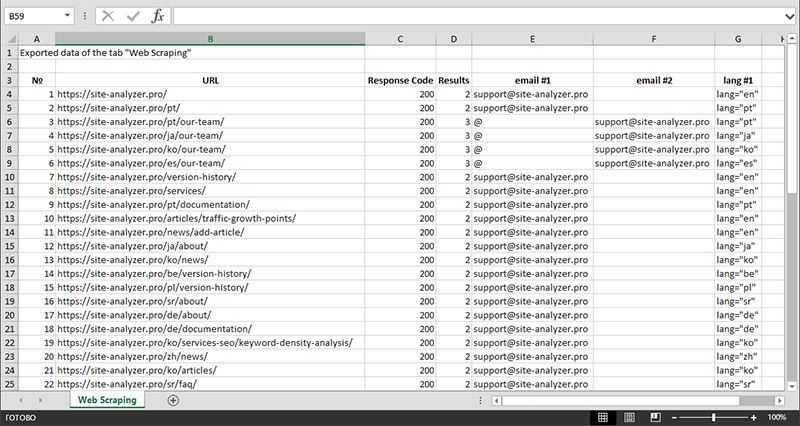
有关模块操作的更详细研究以及最常见规则和正则表达式的列表,请参阅文章
2. 检查站点内内容的唯一性。
此工具允许您搜索重复页面并检查站点内文本的唯一性。换句话说,这是对一组 URL 之间的唯一性的批量检查。
这在以下情况下很有用:
- 搜索完整的重复页面(例如,具有参数的页面和相同的页面,但在 CNC 视图中)。
- 搜索部分内容匹配(例如,烹饪博客中的两个罗宋汤食谱,彼此相似度为 96%,这表明应删除其中一篇文章以摆脱可能的流量蚕食)。
- 在文章网站上,您不小心写了一篇关于您 10 年前已经写过的主题的文章。在这种情况下,我们的工具还将检测此类文章的副本。
检查内容唯一性的工具的原理很简单:程序从网站 URL 列表中下载它们的内容,接收页面的文本内容(没有 HEAD 块和 HTML 标签),然后将它们与每个其他使用shingle算法。

因此,使用带状疱疹,我们可以确定页面的唯一性,并且可以计算具有 0% 唯一性的页面的完全重复,以及具有不同程度的文本内容唯一性的部分重复。该程序使用长度为 5 的木瓦。
您可以在本文中了解有关该模块如何工作的更多信息。: >>
3. 通过 Google PageSpeed 检查加载页面的速度。
谷歌搜索巨头的 PageSpeed Insights 工具可以让你检查某些页面元素的加载速度,还可以显示桌面和移动版本浏览器感兴趣的 URL 的整体加载速度分数。

Google 的工具对每个人都有好处,但是,它有一个明显的缺点 - 它不允许您创建组 URL 检查,这在检查您网站的许多页面时会造成不便:同意手动检查 100 个或更多 URL 的下载速度一页是一件苦差事,可能需要很多时间。
因此,我们创建了一个模块,允许您通过 Google PageSpeed Insights 工具中的特殊 API 免费创建页面加载速度的组检查。

主要分析参数:
- FCP (First Contentful Paint) – 显示第一个内容的时间。
- SI (Speed Index) – 内容在页面上显示的速度的指示器。
- LCP (Largest Contentful Paint) – 页面上最大元素的显示时间。
- TTI (Time to Interactive) – 页面完全准备好进行用户交互的时间。
- TBT (Total Blocking Time) – 从第一次呈现内容到准备好进行用户交互的时间。
- CLS (Cumulative Layout Shift) – 累积布局偏移。用于衡量页面的视觉稳定性。
由于 SiteAnalyzer 的多线程工作,检查数百个或更多 URL 只需几分钟,而在手动模式下通过浏览器可能需要一天或更长时间。
同时,只需单击几下即可对 URL 本身进行分析,然后可以下载报告,包括在 Excel 中以方便的形式检查的主要特征。
您需要开始的只是获取 API 密钥。
本文介绍了如何执行此操作。 >>
4. 添加了按文件夹对项目进行分组的功能。
为了更方便地浏览项目列表,添加了按文件夹对站点进行分组的功能。

此外,可以按名称过滤项目列表。
5. 程序设置界面已更新。
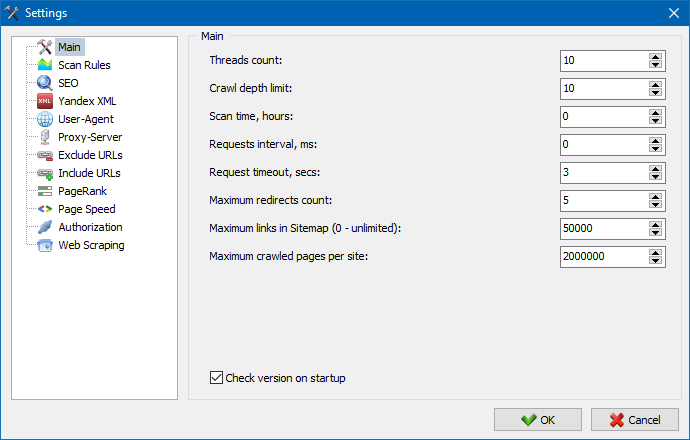
随着程序功能的扩展,我们使用选项卡变得"紧张",因此我们将设置窗口重新格式化为更易于理解和功能性的界面。
注:
- 修复了 URL 异常的错误统计
- 修复了对站点爬行深度的错误核算
- 恢复显示从文件导入的 URL 的重定向
- 恢复了重新排列和记住选项卡中列顺序的能力
- 恢复非规范页面的统计,解决了空元标记的问题
- 在"信息"选项卡上恢复链接锚的显示
- 加速从剪贴板导入大量 URL
- 修复了标题和描述的解析并不总是正确的问题
- 恢复图像中 alt 和标题的显示
- 修复了在扫描项目时切换到"外部链接"选项卡时的冻结问题
- 修复了在项目之间切换和更新"站点爬取统计"选项卡的节点时发生的错误
- 修复了带有参数的 URL 嵌套级别的错误定义
- 通过主表中的 HTML-hash 字段固定数据排序
- 使用 Cyrillic 域优化程序的工作
- 更新程序设置界面
- 更新的标志设计


Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
先前版本概述:


















