






















 3,066
3,066Masalah penentuan halaman duplikat dan keunikan teks dalam situs adalah salah satu yang paling penting dalam daftar pekerjaan audit teknis. Baik kesejahteraan situs secara keseluruhan dan distribusi anggaran perayapan mesin pencari, yang mungkin sia-sia, bergantung pada keberadaan halaman duplikat, dan secara umum, peringkat situs mungkin mengalami kesulitan karena banyaknya duplikat. isi.

Dan jika Anda dapat dengan mudah menemukan sejumlah besar layanan dan program di Internet untuk memeriksa keunikan masing-masing teks, maka tidak banyak layanan serupa untuk memeriksa keunikan sekelompok URL tertentu di antara mereka sendiri, meskipun masalahnya sendiri penting. dan relevan.
Opsi apa untuk masalah dengan konten non-unik yang ada di situs?
1. Konten yang sama di URL yang berbeda.
Biasanya ini adalah halaman dengan parameter dan halaman yang sama, tetapi dalam bentuk CNC (URL yang dapat dibaca manusia).
- Contoh:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Ini adalah masalah yang cukup umum ketika, setelah mengatur CNC, programmer lupa mengatur 301 redirect dari halaman dengan parameter ke halaman CNC.
Masalah ini diselesaikan dengan mudah oleh perayap web mana pun, yang, setelah membandingkan semua halaman situs, akan menemukan bahwa dua di antaranya memiliki kode hash (MD5) yang sama, dan memberi tahu pengoptimal tentang ini, siapa yang harus mengatur tugas , semua programmer yang sama, untuk menginstal 301 redirect ke halaman CNC.
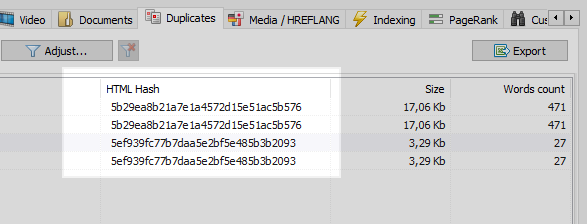
Namun, tidak semuanya begitu jelas.
2. Konten yang cocok sebagian.
Konten serupa terbentuk ketika kita memiliki halaman yang berbeda, tetapi sebenarnya dengan konten yang sama atau serupa.
Contoh 1
Di situs yang menjual jendela plastik, di bagian berita, seorang copywriter menulis ucapan selamat pada 8 Maret untuk 500 karakter setahun yang lalu dan memberikan diskon 15% untuk pemasangan jendela plastik.
Dan tahun ini, manajer konten memutuskan untuk menipu, dan tanpa basa-basi lagi, dia menemukan berita yang diposting sebelumnya dengan diskon, menyalinnya, dan mengubah diskon dari 15 menjadi 12% + menambahkan 50 tanda sendiri dengan ucapan selamat tambahan.
Jadi, sebagai hasilnya, kami memiliki dua teks yang hampir identik, serupa 90%, yang dengan sendirinya merupakan duplikat kabur, salah satunya, untuk selamanya, perlu segera ditulis ulang.
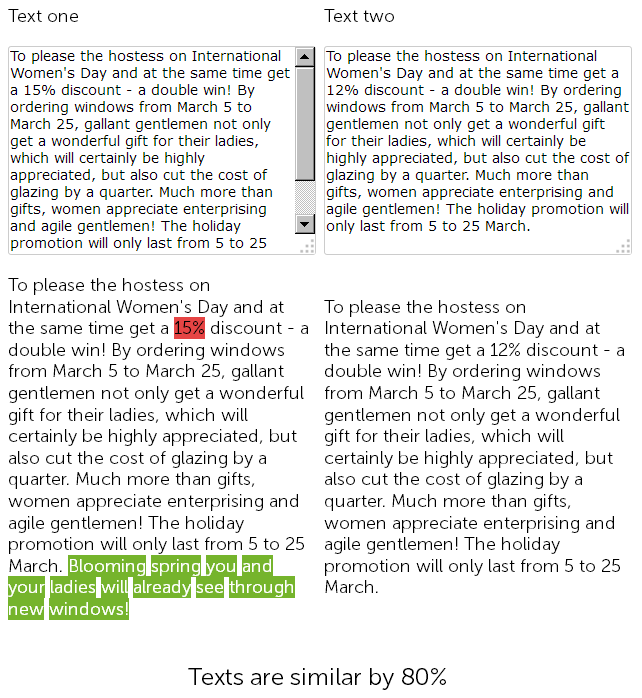
Pada saat yang sama, untuk layanan audit teknis, kedua berita ini akan berbeda, karena CNC di situs sudah dikonfigurasi, dan checksum halaman tidak akan cocok, apa pun yang dikatakan orang.
Akibatnya, halaman mana yang akan berperingkat lebih baik adalah pertanyaan besar...
Tapi itu berita seperti itu - mereka cenderung cepat menjadi usang, jadi mari kita ambil contoh yang lebih menarik.
Contoh 2
Anda memiliki bagian artikel di situs Anda, atau Anda mengelola halaman pribadi untuk hobi / hasrat Anda, misalnya, ini adalah "blog kuliner".
Dan, misalnya, blog Anda telah mengumpulkan sejumlah artikel sepanjang waktu, lebih dari 100, atau bahkan beberapa ratus. Jadi Anda mengambil topik dan menulis artikel baru, mempostingnya, dan entah bagaimana ternyata artikel serupa telah ditulis 3 tahun yang lalu. Meskipun, tampaknya, sebelum menulis konten, Anda membaca semua judul, membuka Excel dengan daftar topik yang diposting, tetapi tidak memperhitungkan bahwa konten masa lalu dari artikel "Cara membuat cokelat panas di rumah" dengan kuat sesuai dengan materi yang baru saja ditulis. Dan ketika memeriksa kedua artikel ini di salah satu layanan online, ternyata 78% unik di antara mereka sendiri, yang tentu saja tidak baik, karena karena duplikasi sebagian, permintaan pencarian mengkanibal di antara halaman-halaman ini, dan pencarian pertanyaan mesin dan kesulitan muncul ketika peringkat duplikat tersebut.
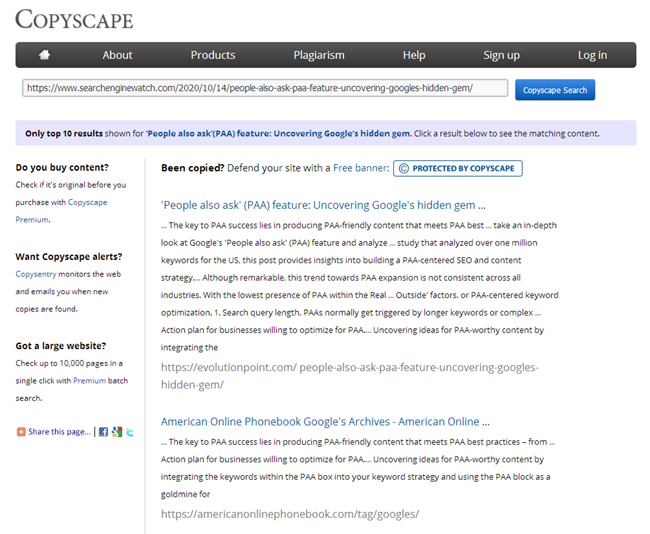
Tentu saja, setelah menulis artikel, setiap copywriter harus memeriksa keunikannya di salah satu layanan terkenal, dan setiap spesialis SEO harus memeriksa konten baru ketika diposting di situs di layanan yang sama.
Tetapi apa yang harus dilakukan jika Anda baru saja menerima situs web untuk promosi dan Anda perlu memeriksa duplikat dengan cepat di semua halamannya? Atau, pada awal pembukaan blog Anda, Anda menulis banyak jenis artikel yang sama, dan sekarang, kemungkinan besar karena mereka, situs mulai melorot. Jangan memeriksa 100.500 halaman secara manual di layanan online, menambahkan setiap artikel untuk diperiksa dengan tangan dan menghabiskan banyak waktu untuk itu.
BatchUniqueChecker
Itulah sebabnya kami membuat program BatchUniqueChecker, yang dirancang untuk memeriksa sekelompok URL untuk keunikan di antara mereka sendiri.
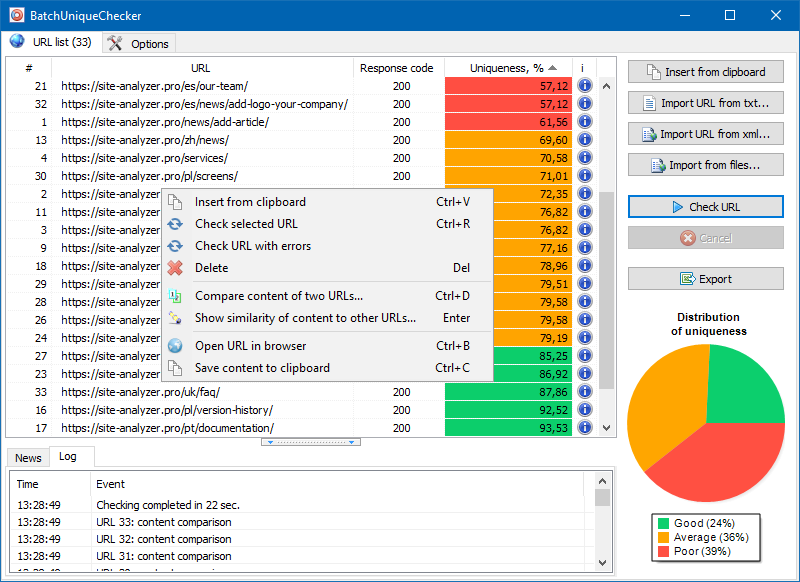
Prinsip pengoperasian BatchUniqueChecker sederhana: menurut daftar URL yang telah disiapkan sebelumnya, program mengunduh kontennya, menerima PlainText (isi teks halaman tanpa blok HEAD dan tanpa tag HTML), dan kemudian membandingkannya dengan masing-masing lainnya menggunakan algoritma shingle.
Jadi, dengan bantuan shingles, kami menentukan keunikan halaman dan dapat menghitung duplikat penuh halaman dengan keunikan 0%, dan duplikat parsial dengan tingkat keunikan konten teks yang berbeda.
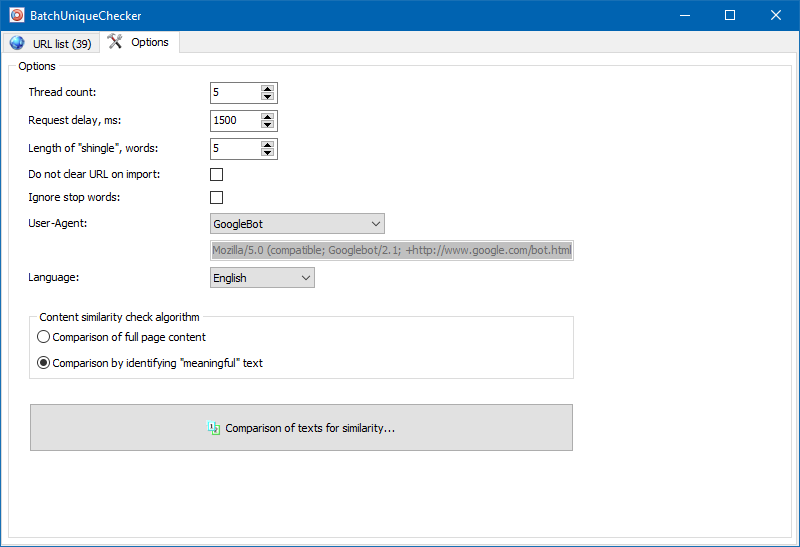
Dalam pengaturan program, dimungkinkan untuk mengatur ukuran sirap secara manual (sirap adalah jumlah kata dalam teks, checksum yang secara bergantian dibandingkan dengan grup berikutnya). Kami merekomendasikan pengaturan nilai = 4. Untuk teks dalam jumlah besar, 5 atau lebih. Untuk volume yang relatif kecil - 3-4.
Teks penting
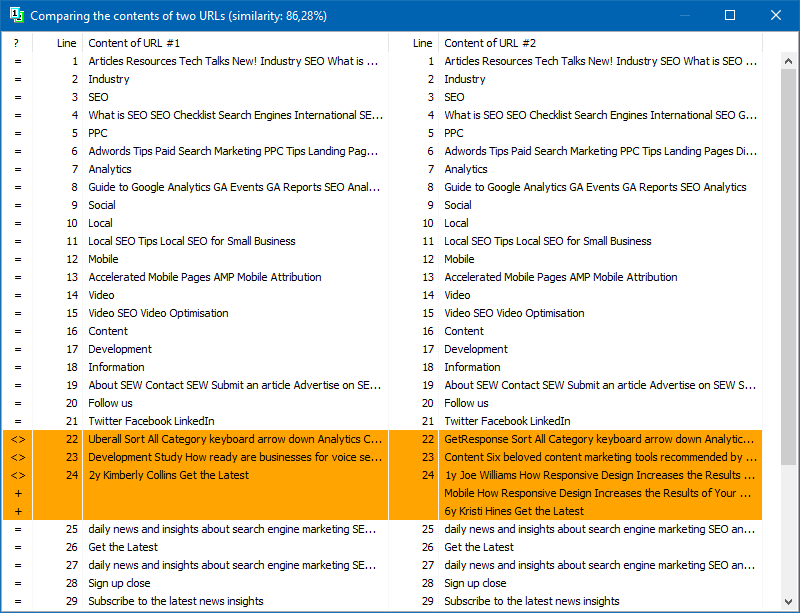
Selain perbandingan konten teks lengkap, program ini berisi algoritme untuk pemilihan "pintar" dari apa yang disebut teks "signifikan".
Artinya, dari kode HTML halaman tersebut, kita hanya mendapatkan konten yang terdapat dalam tag H1-H6, P, PRE dan LI. Karena itu, kami membuang semua yang "tidak penting", misalnya konten dari menu navigasi situs, teks dari footer, atau menu samping.
Sebagai hasil dari manipulasi seperti itu, kami hanya mendapatkan konten halaman yang "bermakna", yang jika dibandingkan, akan menunjukkan hasil keunikan yang lebih akurat dengan halaman lain.
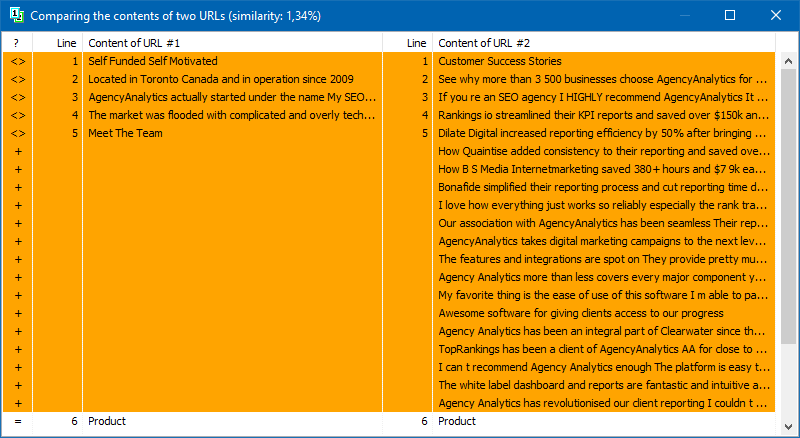
Daftar halaman untuk analisis selanjutnya dapat ditambahkan dengan beberapa cara: menempelkan dari clipboard, memuat dari file teks, atau mengimpor dari Sitemap.xml dari disk komputer Anda.
Berkat kerja program yang multi-utas, memeriksa ratusan atau lebih URL hanya dapat memakan waktu beberapa menit, yang, secara manual, melalui layanan online, dapat memakan waktu satu hari atau lebih.
Dengan demikian, Anda mendapatkan alat sederhana untuk dengan cepat memeriksa keunikan konten untuk sekelompok URL, yang dapat dijalankan bahkan dari media yang dapat dipindahkan.
BatchUniqueChecker gratis, hanya membutuhkan 4 MB dalam arsip dan tidak memerlukan instalasi.
Yang Anda butuhkan untuk memulai adalah mengunduh distribusi dan menambahkan daftar URL menarik untuk verifikasi, yang dapat diperoleh melalui program audit teknis gratis SiteAnalyzer.
Artikel lainnya



















