






















 2,540
2,540La question de la détermination des pages en double et de l'unicité des textes au sein du site est l'une des plus importantes de la liste des travaux sur l'audit technique. La présence de pages en double détermine à la fois le bien-être général du site et la répartition du budget d'exploration des moteurs de recherche, qui peut être gaspillé, et en général, le classement du site peut être difficile en raison de la grande quantité de contenu dupliqué.

Et si vous pouvez facilement trouver un grand nombre de services et de programmes pour vérifier l'unicité de textes individuels sur Internet, il n'y a pas beaucoup de services similaires pour vérifier l'unicité d'un groupe d'URL spécifiques entre eux, bien que le problème lui-même soit important et pertinent.
Quelles options pour les problèmes de contenu non unique peuvent être sur le site?
1. Même contenu pour différentes URL.
Il s'agit généralement d'une page avec des paramètres et la même page, mais sous la forme d'une SEF (URL lisible par l'homme).
- Exemple:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
C'est un problème assez courant lorsque, après avoir configuré la SEF, le programmeur oublie de configurer une redirection 301 des pages avec paramètres vers les pages avec SEF.
Ce problème peut être facilement résolu par n'importe quel robot d'exploration, qui, après avoir comparé toutes les pages du site, constatera que deux d'entre elles ont les mêmes codes de hachage (MD5), et informera l'optimiseur, qui devra définir la tâche, le même programmeur, pour installer 301 redirections aux pages SEF.
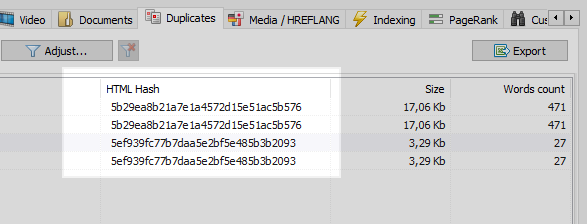
Cependant, tout n'est pas si simple.
2. Contenu superposé.
Un contenu similaire est généré lorsque nous avons des pages différentes, mais, en fait, avec un contenu identique ou similaire.
Exemple 1
Sur le site de vente de fenêtres en plastique, dans la section actualités, il y a un an, un rédacteur a écrit une félicitation le 8 mars pour 500 caractères et a accordé une remise de 15% sur l'installation de fenêtres en plastique.
Et cette année, le gestionnaire de contenu a décidé de «tricher», et sans plus tarder, a trouvé les nouvelles publiées précédemment avec des réductions, les a copiées et a changé la taille de la réduction de 15 à 12% + a ajouté 50 signes de lui-même avec des félicitations supplémentaires.
Ainsi, au final, nous avons deux textes presque identiques, similaires à 90%, qui sont en eux-mêmes des doublons flous, dont l'un, pour cause, nécessite une réécriture urgente.
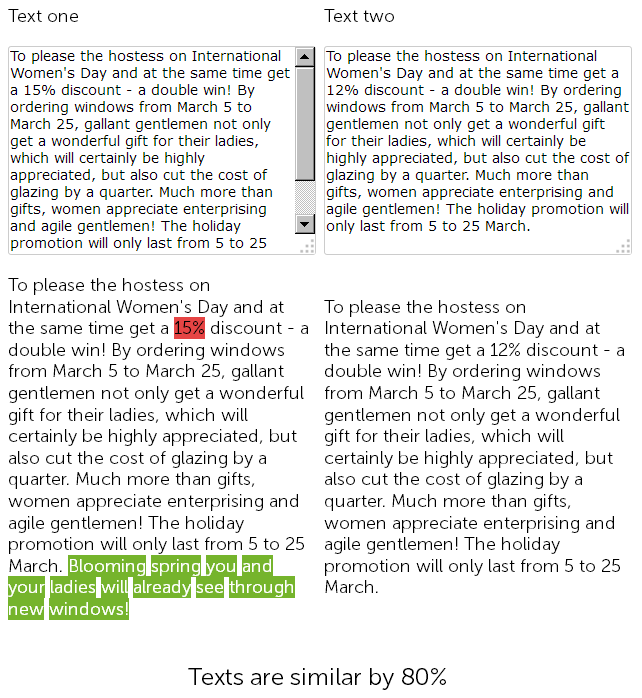
En même temps, pour les services d'audit technique, ces deux nouveautés seront différentes, puisque la SEF sur le site a déjà été configurée, et les sommes de contrôle des pages ne correspondront pas, quoi qu'on en dise.
En fin de compte, quelle page sera mieux classée est une grande question ...
Mais ce sont de telles nouvelles - elles ont tendance à devenir rapidement obsolètes, alors prenons un exemple plus intéressant.
Exemple 2
Vous avez une section d'articles sur votre site, ou vous maintenez une page personnelle pour votre passe-temps / passe-temps, par exemple, c'est un "blog culinaire".
Et, par exemple, votre blog a déjà accumulé une commande d'articles pendant tout le temps, plus de 100, voire plusieurs centaines. Et ainsi vous avez choisi un sujet et écrit un nouvel article, l'avez posté, et plus tard découvert d'une manière ou d'une autre qu'un article similaire avait déjà été écrit il y a 3 ans. Bien qu'il semble qu'avant d'écrire le contenu, vous ayez parcouru tous les titres, ouvert Excel avec une liste de sujets publiés, mais vous n'avez pas tenu compte du fait que le contenu précédent de l'article "Comment faire du chocolat chaud à la maison" coïncide fortement avec le matériel qui vient d'être écrit. Et lors de la vérification de ces deux articles dans l'un des services en ligne, il s'avère qu'ils sont uniques à 78% entre eux, ce qui, bien sûr, n'est pas bon, car en raison d'une duplication partielle, il y a une cannibalisation des requêtes de recherche entre ces pages et le moteur de recherche. des questions et des difficultés surgissent lors du classement de ces doublons.
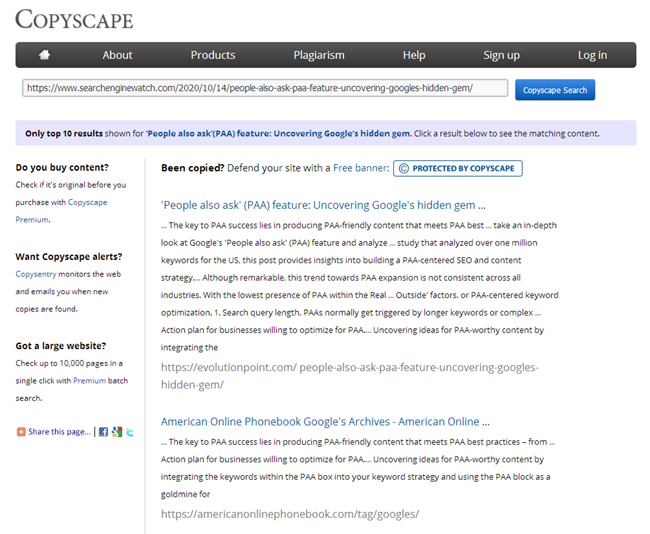
Bien sûr, après avoir écrit un article, chaque rédacteur doit vérifier son unicité dans l'un des services bien connus, et chaque SEO est obligé de vérifier le nouveau contenu lorsqu'il est publié sur le site dans les mêmes services.
Mais que faire si un site Web vient de venir à vous pour une promotion et que vous devez vérifier rapidement toutes ses pages pour les doublons? Ou, à l'aube de l'ouverture de votre blog, vous avez écrit un tas d'articles du même type, et maintenant, très probablement, à cause d'eux, le site a commencé à s'affaisser. Ne vérifiez pas à la main 100 500 pages dans les services en ligne, en ajoutant pour vérifier chaque article à la main et en y passant beaucoup de temps.
BatchUniqueChecker
C'est pourquoi nous avons créé le programme BatchUniqueChecker, conçu pour vérifier par lots un groupe d'URL pour l'unicité entre elles.
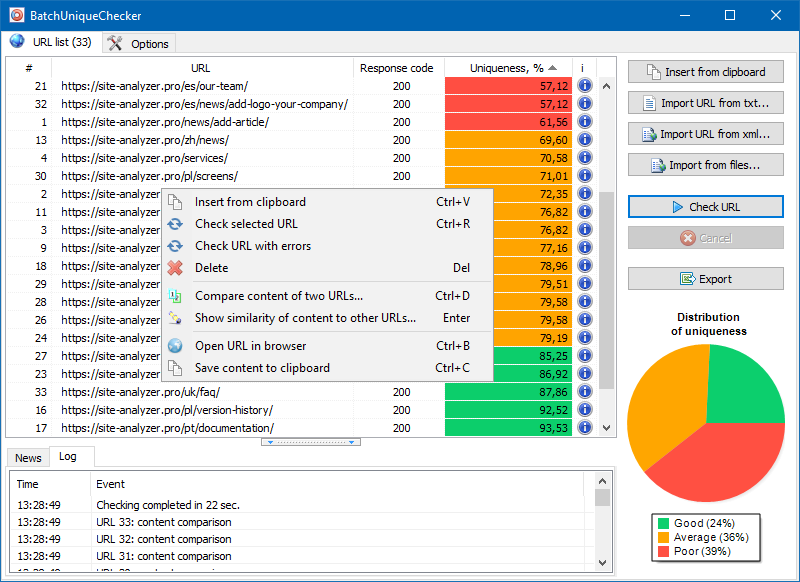
Le principe de fonctionnement de BatchUniqueChecker est simple: le programme télécharge leur contenu à l'aide d'une liste d'URL préalablement préparée, reçoit PlainText (le contenu texte de la page sans bloc HEAD et sans balises HTML), puis les compare les uns aux autres à l'aide de l'algorithme de bardeau.
Ainsi, en utilisant des bardeaux, nous déterminons l'unicité des pages et pouvons calculer à la fois des doublons complets de pages avec un unicité de 0% et des doublons partiels avec divers degrés d'unicité du contenu du texte.
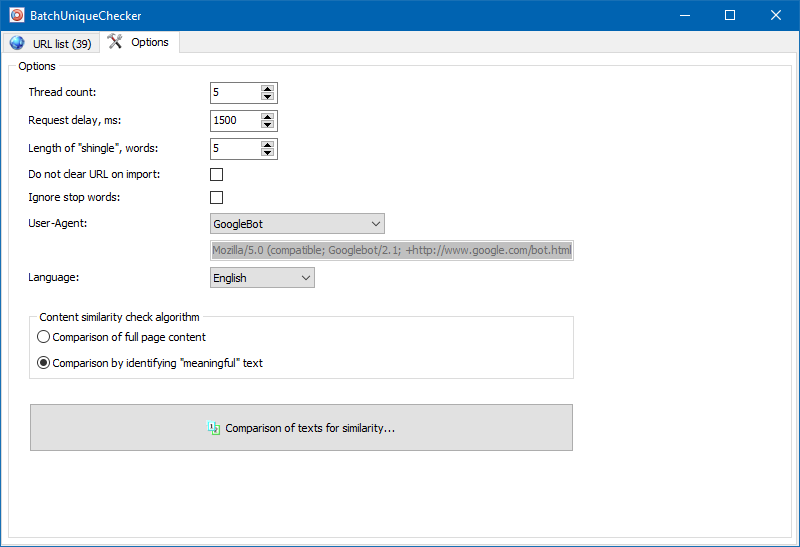
Dans les paramètres du programme, vous pouvez définir manuellement la taille du bardeau (le bardeau est le nombre de mots dans le texte, dont la somme de contrôle est alternativement comparée aux groupes suivants). Nous vous recommandons de définir la valeur = 4. Pour de grandes quantités de texte de 5 et plus. Pour des volumes relativement petits - 3-4.
Textes significatifs
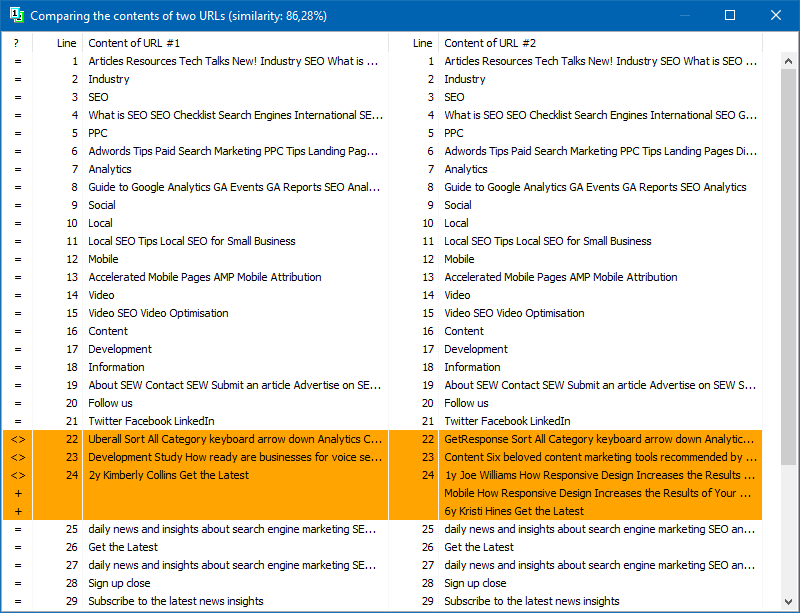
En plus de la comparaison de contenu en texte intégral, le programme comprend un algorithme pour l'isolation «intelligente» des textes dits «significatifs».
Autrement dit, à partir du code HTML de la page, nous obtenons uniquement le contenu contenu dans les balises H1-H6, P, PRE et LI. Pour cette raison, nous supprimons en quelque sorte tout ce qui est "non significatif", par exemple le contenu du menu de navigation du site, le texte du pied de page ou du menu latéral.
À la suite de telles manipulations, nous n'obtenons que du contenu de page «significatif», qui, une fois comparé, affichera des résultats d'unicité plus précis avec d'autres pages.
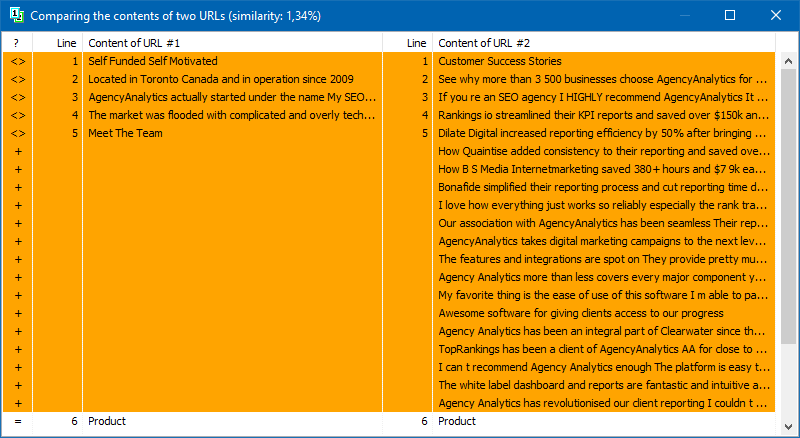
La liste des pages pour leur analyse ultérieure peut être ajoutée de plusieurs manières: coller à partir du presse-papiers, charger à partir d'un fichier texte ou importer depuis Sitemap.xml depuis le disque de votre ordinateur.
En raison du fonctionnement multithread du programme, la vérification de centaines d'URL ou plus ne peut prendre que quelques minutes, ce qui en mode manuel, via des services en ligne, peut prendre un jour ou plus.
Ainsi, vous obtenez un outil simple pour vérifier rapidement l'unicité du contenu d'un groupe d'URL, qui peuvent être exécutées même à partir d'un support amovible.
BatchUniqueChecker est gratuit, ne prend que 4 Mo dans l'archive et ne nécessite pas d'installation.
Tout ce dont vous avez besoin pour commencer est de télécharger le kit de distribution et d'ajouter une liste d'URL d'intérêt pour la vérification, qui peut être obtenue via un programme d'audit technique gratuit SiteAnalyzer.

Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Autres articles



















