





















 3,180
3,180Hallo zusammen! Wir sind wieder im Geschäft!
Nach sehr langer Zeit haben wir endlich eine neue Version von SiteAnalyzer vorbereitet, die hoffentlich Ihre Erwartungen erfüllt und zu einem unverzichtbaren Assistenten in der SEO-Promotion wird.
In der neuen Version von SiteAnalyzer haben wir einige der von Benutzern am häufigsten nachgefragten Funktionen implementiert, wie zum Beispiel: Data Scraping (Daten aus der Site extrahieren), die Einzigartigkeit des Inhalts überprüfen und die Seitenladegeschwindigkeit durch Google PageSpeed überprüfen. Gleichzeitig wurden viele Fehler behoben und das Logo neu gestaltet. Lassen Sie uns über alles ausführlicher sprechen.

Die wichtigsten änderungen
1. Scraping von Daten mit XPath, CSS, XQuery, RegEx.
Web-Scraping ist ein automatisierter Prozess zum Extrahieren von Daten aus den interessanten Seiten der Website nach bestimmten Regeln.
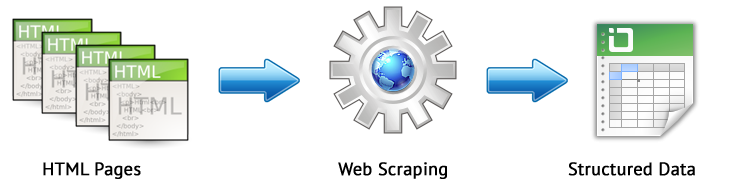
Die wichtigsten Web-Scraping-Methoden sind Parsing-Methoden, die XPath, CSS-Selektoren, XQuery, RegExp und HTML-Vorlagen verwenden.
- XPath ist eine spezielle Abfragesprache für XML / XHTML-Dokumentelemente. Um auf Elemente zuzugreifen, verwendet XPath die DOM-Navigation, indem der Pfad zum gewünschten Element auf der Seite beschrieben wird. Mit seiner Hilfe können Sie den Wert eines Elements anhand seiner Ordnungszahl im Dokument ermitteln, seinen Textinhalt oder internen Code extrahieren, das Vorhandensein eines bestimmten Elements auf der Seite überprüfen.
- CSS-Selektoren werden verwendet, um ein Element seines Teils (Attributs) zu finden. CSS ist XPath syntaktisch ähnlich, aber in einigen Fällen sind CSS-Locators schneller und beschreibender und prägnanter. Der Nachteil von CSS ist, dass es nur in eine Richtung funktioniert – tiefer in das Dokument hinein. XPath hingegen funktioniert in beide Richtungen (Sie können beispielsweise nach einem übergeordneten Element durch ein untergeordnetes Element suchen).
- XQuery basiert auf XPath. XQuery ahmt XML nach, wodurch Sie verschachtelte Ausdrücke auf eine Weise erstellen können, die in XSLT nicht möglich ist.
- RegExp ist eine formale Suchsprache zum Extrahieren von Werten aus einem Satz von Textzeichenfolgen, die den erforderlichen Bedingungen entsprechen (regulärer Ausdruck).
- HTML-Vorlagen ist eine Sprache zum Extrahieren von Daten aus HTML-Dokumenten, die eine Kombination aus HTML-Markup zur Beschreibung der Suchvorlage für das gewünschte Fragment sowie Funktionen und Operationen zum Extrahieren und Transformieren von Daten ist.
Typischerweise wird Scraping verwendet, um Aufgaben zu lösen, die manuell schwierig zu handhaben sind. Dies kann das Extrahieren von Produktbeschreibungen sein, um einen neuen Online-Shop zu erstellen, das Scraping in der Marktforschung, um Preise zu überwachen, oder um Anzeigen zu überwachen.

In SiteAnalyzer wird das Scraping auf der Registerkarte Datenextraktion konfiguriert, auf der Extraktionsregeln konfiguriert werden. Regeln können gespeichert und bei Bedarf bearbeitet werden.
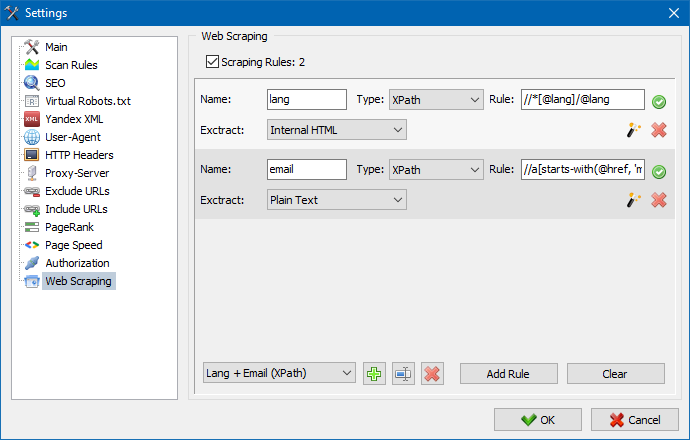
Es gibt auch ein Regeltestmodul. Mit dem integrierten Regel-Debugger können Sie schnell und einfach den HTML-Inhalt jeder Seite der Site abrufen und die Arbeit von Abfragen testen und dann die debuggten Regeln zum Analysieren von Daten in SiteAnalyzer verwenden.

Nach Abschluss der Datenextraktion können alle gesammelten Informationen nach Excel exportiert werden.
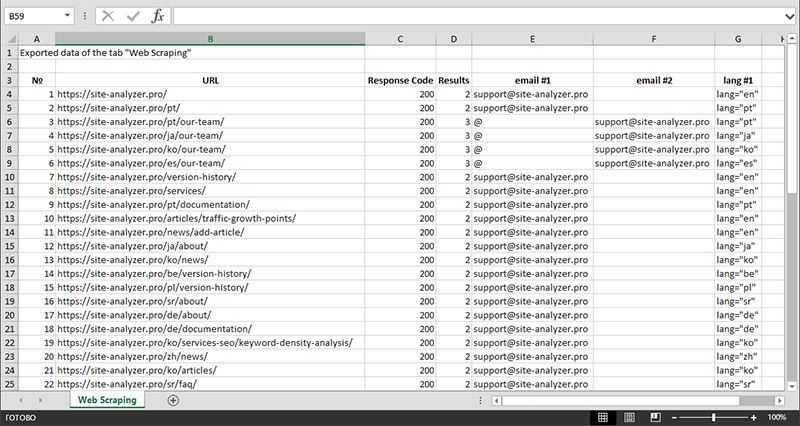
Eine detailliertere Untersuchung der Funktionsweise des Moduls und eine Liste der gebräuchlichsten Regeln und regulären Ausdrücke finden Sie im Artikel
2. Überprüfung der Einzigartigkeit des Inhalts innerhalb der Website.
Mit diesem Tool können Sie nach doppelten Seiten suchen und die Einzigartigkeit von Texten innerhalb der Site überprüfen. Mit anderen Worten, dies ist eine Batch-Prüfung einer Gruppe von URLs auf Eindeutigkeit untereinander.
Dies kann in folgenden Fällen nützlich sein:
- Um nach vollständigen doppelten Seiten zu suchen (z. B. eine Seite mit Parametern und derselben Seite, jedoch in der CNC-Ansicht).
- Um nach teilweisen Inhaltsübereinstimmungen zu suchen (z. B. zwei Borschtsch-Rezepte in einem kulinarischen Blog, die sich zu 96% ähneln, was darauf hindeutet, dass einer der Artikel gelöscht werden sollte, um eine mögliche Traffic-Kannibalisierung zu beseitigen).
- Wenn Sie auf einer Artikelseite versehentlich einen Artikel zu einem Thema geschrieben haben, das Sie bereits vor 10 Jahren geschrieben haben. In diesem Fall erkennt unser Tool auch ein Duplikat eines solchen Artikels.
Das Prinzip des Tools zur Überprüfung der Eindeutigkeit von Inhalten ist einfach: Das Programm lädt deren Inhalt aus der Liste der Website-URLs herunter, empfängt den Textinhalt der Seite (ohne HEAD-Block und ohne HTML-Tags) und vergleicht sie dann mit jedem. andere mit dem Schindel-Algorithmus.

So ermitteln wir mit Hilfe von Schindeln die Eindeutigkeit von Seiten und können sowohl Vollduplikate von Seiten mit 0% Eindeutigkeit als auch Teildubletten mit unterschiedlichen Eindeutigkeitsgraden des Textinhalts berechnen. Das Programm arbeitet mit einer Schindellänge von 5.
In diesem Artikel erfahren Sie mehr über die Funktionsweise des Moduls.: >>
3. Überprüfung der Ladegeschwindigkeit von Seiten durch Google PageSpeed.
Das PageSpeed Insights-Tool des Google-Suchgiganten ermöglicht es Ihnen, die Ladegeschwindigkeit bestimmter Seitenelemente zu überprüfen und zeigt auch den Gesamtwert der Ladegeschwindigkeit der interessierenden URLs für die Desktop- und mobilen Versionen des Browsers an.

Das Tool von Google ist für alle gut, es hat jedoch einen wesentlichen Nachteil - es erlaubt Ihnen keine Gruppen-URL-Überprüfungen zu erstellen, was beim Überprüfen vieler Seiten Ihrer Website zu Unannehmlichkeiten führt: Stimmen Sie zu, dass die Download-Geschwindigkeit für 100 oder mehr URLs manuell überprüft wird Eine Seite ist mühsam und kann viel Zeit in Anspruch nehmen.
Aus diesem Grund haben wir ein Modul erstellt, mit dem Sie über eine spezielle API im Google PageSpeed Insights-Tool kostenlos Gruppenprüfungen der Seitenladegeschwindigkeit erstellen können.

Die wichtigsten analysierten Parameter:
- FCP (First Contentful Paint) – Zeit, um den ersten Inhalt anzuzeigen.
- SI (Speed Index) – ein Indikator dafür, wie schnell Inhalte auf einer Seite angezeigt werden.
- LCP (Largest Contentful Paint) – Anzeigezeit für das größte Element auf der Seite.
- TTI (Time to Interactive) – die Zeit, in der die Seite vollständig für die Benutzerinteraktion bereit ist.
- TBT (Total Blocking Time) – Zeit vom ersten Rendern des Inhalts bis zu seiner Bereitschaft für die Benutzerinteraktion.
- CLS (Cumulative Layout Shift) – kumulative Layoutverschiebung. Dient zur Messung der visuellen Stabilität der Seite.
Aufgrund der Multithread-Arbeit von SiteAnalyzer kann die Überprüfung von Hunderten oder mehr URLs nur wenige Minuten dauern, was im manuellen Modus über einen Browser einen Tag oder länger dauern kann.
Gleichzeitig erfolgt die Analyse der URL selbst mit wenigen Klicks, wonach ein Bericht heruntergeladen werden kann, der die wichtigsten Merkmale der Prüfungen in bequemer Form in Excel enthält.
Alles, was Sie für den Anfang benötigen, ist einen API-Schlüssel zu erhalten.
Wie das geht, wird in diesem Artikel beschrieben. >>
4. Es wurde die Möglichkeit hinzugefügt, Projekte nach Ordnern zu gruppieren.
Für eine bequemere Navigation durch die Projektliste wurde die Möglichkeit hinzugefügt, Sites nach Ordnern zu gruppieren.

Außerdem wurde es möglich, die Liste der Projekte nach Namen zu filtern.
5. Die Oberfläche der Programmeinstellungen wurde aktualisiert.
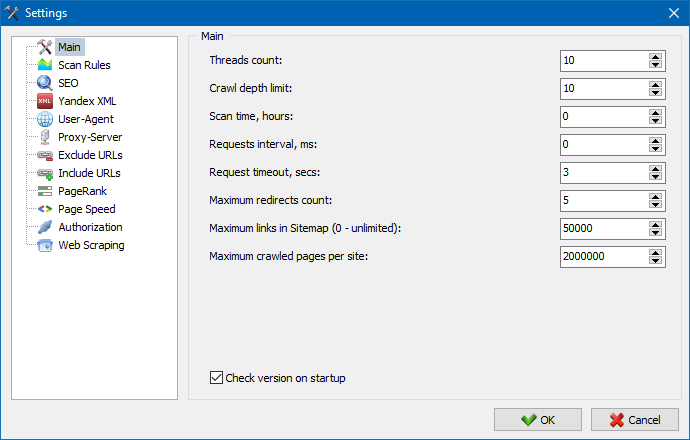
Mit der Erweiterung der Programmfunktionalität wurde es für uns "eng" für uns, Registerkarten zu verwenden, daher haben wir das Einstellungsfenster in eine verständlichere und funktionellere Oberfläche umformatiert.
Anmerkungen:
- Fehlerhafte Abrechnung von URL-Ausnahmen behoben
- Falsche Berechnung der Crawling-Tiefe der Site behoben
- Anzeige von Weiterleitungen für aus einer Datei importierte URLs wiederhergestellt
- Die Fähigkeit zum Neuanordnen und Merken der Spaltenreihenfolge in Tabs wiederhergestellt
- Accounting von nicht-kanonischen Seiten wiederhergestellt, Problem mit leeren Meta-Tags gelöst
- Wiederhergestellte Anzeige von Link-Ankern auf dem Info-Tab
- Beschleunigter Import einer großen Anzahl von URLs aus der Zwischenablage
- Nicht immer korrektes Parsen von Titel und Beschreibung behoben
- Anzeige von Alt und Titel in Bildern wiederhergestellt
- Einfrieren beim Wechseln zum Tab "Externe Links" beim Scannen eines Projekts behoben fixed
- Fehler behoben, der beim Wechseln zwischen Projekten und beim Aktualisieren der Knoten der Registerkarte "Site-Crawling-Statistiken" auftrat
- Falsche Definition der Verschachtelungsebene für URL mit Parametern behoben fixed
- Feste Datensortierung nach HTML-Hash-Feld in der Haupttabelle
- Optimierte Arbeit des Programms mit kyrillischen Domänen
- Aktualisierte Programmeinstellungsoberfläche
- Aktualisiertes Logo-Design

Übersicht über frühere Versionen:
- Überblick über die neue Version SiteAnalyzer 2.2
- Überblick über die neue Version SiteAnalyzer 2.1
- Überblick über die neue Version SiteAnalyzer 2.0


















