






















 2,078
2,078Otázka stanovení duplicitních stránek a jedinečnosti textů na webu je jednou z nejdůležitějších v seznamu prací o technickém auditu. Přítomnost duplicitních stránek určuje jak celkovou pohodu webu, tak distribuci rozpočtu procházení vyhledávače, což může být zbytečné. Obecně může hodnocení webu narazit na potíže kvůli velkému množství duplicitního obsahu.

A pokud na internetu snadno najdete velké množství služeb a programů pro kontrolu jedinečnosti jednotlivých textů, není mnoho podobných služeb, které by mezi sebou zkontrolovaly jedinečnost skupiny konkrétních adres URL, i když samotný problém je důležitý a relevantní.
Jaké možnosti řešení problémů s nejedinečným obsahem mohou být na webu?
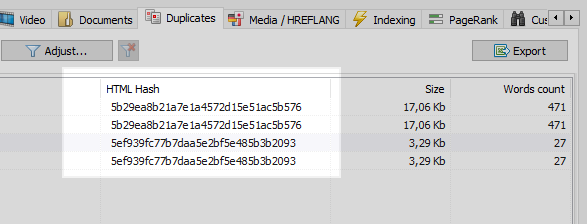
1. Stejný obsah pro různé adresy URL.
Obvykle se jedná o stránku s parametry a stejnou stránkou, ale ve formě SEF (člověkem čitelná URL).
- Příklad:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
To je docela běžný problém, když po nastavení SEF programátor zapomene nastavit přesměrování 301 ze stránek s parametry na stránky s SEF.
Tento problém lze snadno vyřešit pomocí libovolného webového prohledávače, který po porovnání všech stránek webu zjistí, že dva z nich mají stejné hash kódy (MD5), a informuje optimalizátor, který bude muset nastavit úkol, stejného programátora, aby nainstaloval přesměrování 301 na SEF stránky.
Ne všechno je však tak jednoduché.
2. Překrývající se obsah.
Podobný obsah se generuje, když máme různé stránky, ale ve skutečnosti se stejným nebo podobným obsahem.
Příklad 1
Na webu pro prodej plastových oken v sekci novinky napsal copywriter před rokem gratulaci 8. března za 500 znaků a poskytl slevu 15% na instalaci plastových oken.
A letos se správce obsahu rozhodl "podvádět" a bez dalších okolků našel dříve zveřejněné novinky se slevami, zkopíroval je a změnil velikost slevy z 15 na 12% + přidal 50 znamení od sebe s dalšími gratulacemi.
Nakonec tedy máme dva téměř identické texty, z 90% podobné, které samy o sobě jsou fuzzy duplikáty, z nichž jeden z dobrých důvodů vyžaduje naléhavé přepsání.
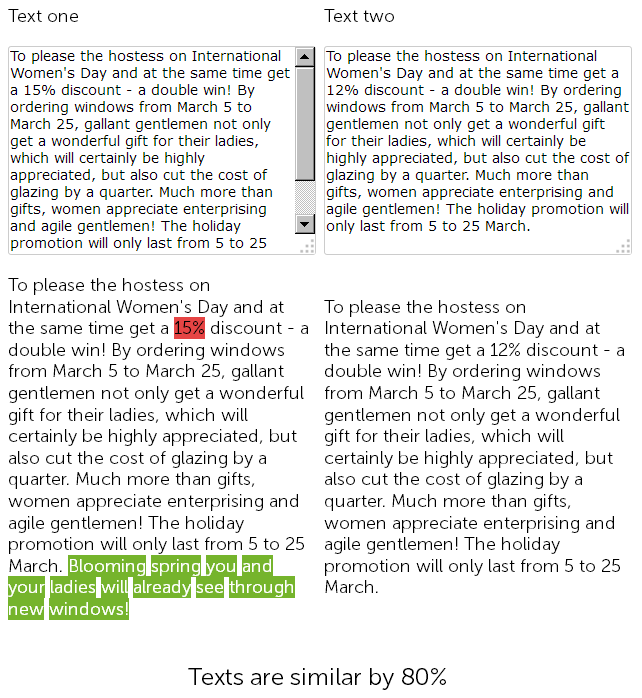
Ve stejné době se pro služby technického auditu budou tyto dvě novinky lišit, protože SEF na webu již bylo nakonfigurováno a kontrolní součty stránek se nebudou shodovat, ať už řeknete cokoli.
Na konci, která stránka bude mít lepší hodnocení, je velká otázka ...
Ale jsou to takové zprávy - mají tendenci rychle zastarávat, vezměme si tedy zajímavější příklad.
Příklad 2
Máte na svém webu sekci s články nebo si udržujete osobní stránku pro své hobby / hobby, například je to "kulinářský blog".
A například váš blog již nashromáždil pořadí článků za celou dobu, více než 100 nebo dokonce několik stovek. A tak jste sebrali téma a napsali nový článek, zveřejnili ho a později nějak zjistili, že podobný článek již byl napsán před 3 lety. I když by se zdálo, že jste před napsáním obsahu prošli všemi tituly, otevřeli Excel se seznamem zveřejněných témat, ale nevzali jste v úvahu, že minulý obsah článku "Jak si vyrobit horkou čokoládu doma" se silně shoduje s právě napsaným materiálem. A při kontrole těchto dvou článků v jedné z online služeb se ukázalo, že jsou mezi sebou 78% jedinečné, což samozřejmě není dobré, protože kvůli částečné duplikaci existuje kanibalizace vyhledávacích dotazů mezi těmito stránkami a vyhledávačem při hodnocení takových duplikátů vznikají otázky a potíže.
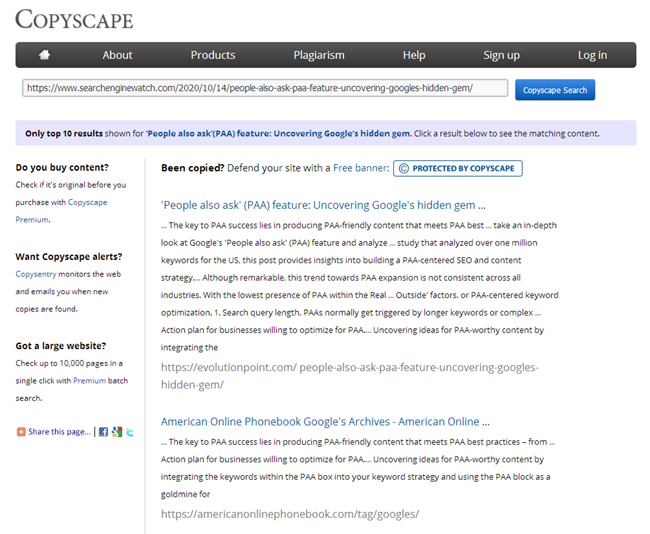
Samozřejmě, po napsání článku musí každý copywriter zkontrolovat jeho jedinečnost v jedné ze známých služeb a každý SEO je povinen zkontrolovat nový obsah, když je na webu zveřejněn ve stejných službách.
Co však dělat, když k vám web právě přišel za účelem propagace a potřebujete rychle zkontrolovat všechny jeho stránky, zda neobsahuje duplikáty? Nebo jste na úsvitu otevření svého blogu napsali spoustu článků stejného typu a nyní se s největší pravděpodobností kvůli nim začal web potápět. Nekontrolujte ručně 100 500 stránek v online službách, přidávejte ke kontrole každý článek ručně a věnujte mu spoustu času.
BatchUniqueChecker
Proto jsme vytvořili program BatchUniqueChecker, který je určen k hromadné kontrole jedinečnosti mezi skupinami adres URL.
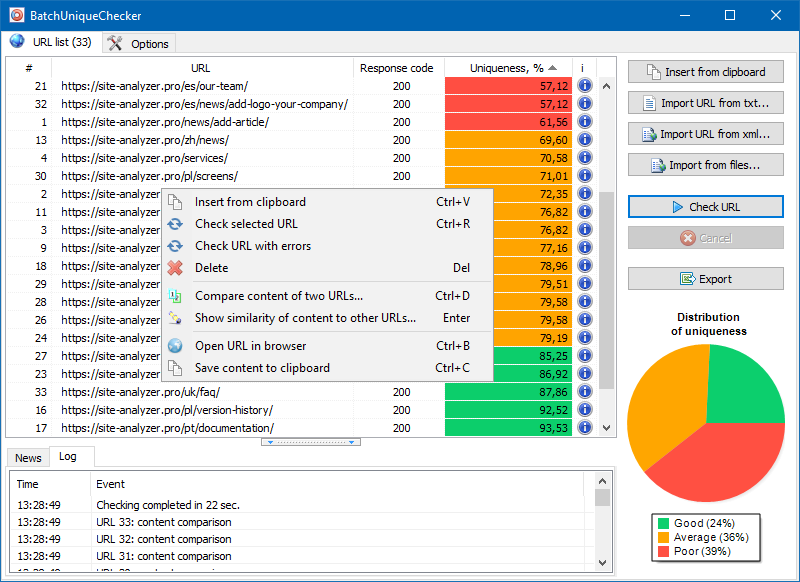
Princip fungování BatchUniqueChecker je jednoduchý: program stahuje jejich obsah pomocí předem připraveného seznamu adres URL, přijímá PlainText (textový obsah stránky bez bloku HEAD a bez značek HTML) a poté je navzájem porovnává pomocí šindlového algoritmu.
Pomocí šindelů tedy určujeme jedinečnost stránek a můžeme vypočítat jak úplné duplikáty stránek s 0% jedinečností, tak i částečné duplikáty s různým stupněm jedinečnosti textového obsahu.
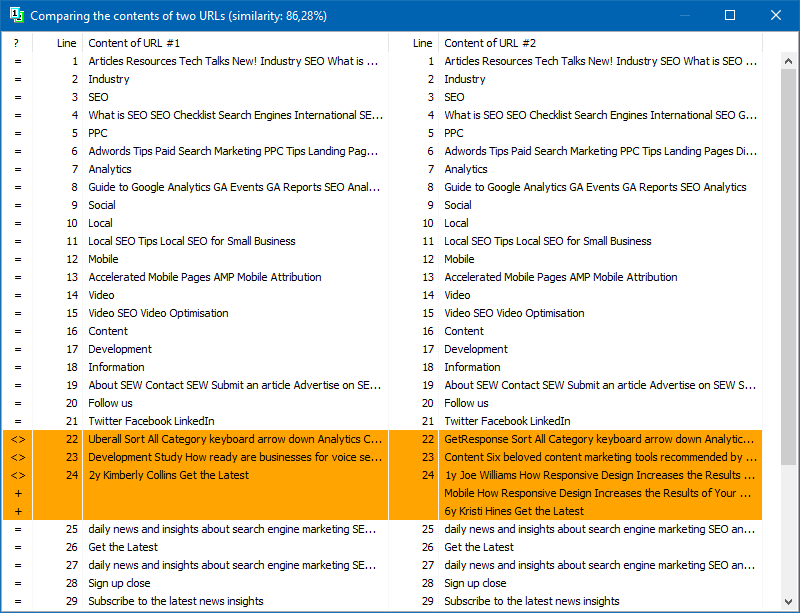
V nastavení programu můžete ručně nastavit velikost šindele (šindel je počet slov v textu, jehož kontrolní součet je střídavě porovnáván s následujícími skupinami). Doporučujeme nastavit hodnotu = 4. Pro velké množství textu od 5 a výše. Pro relativně malé objemy - 3-4.
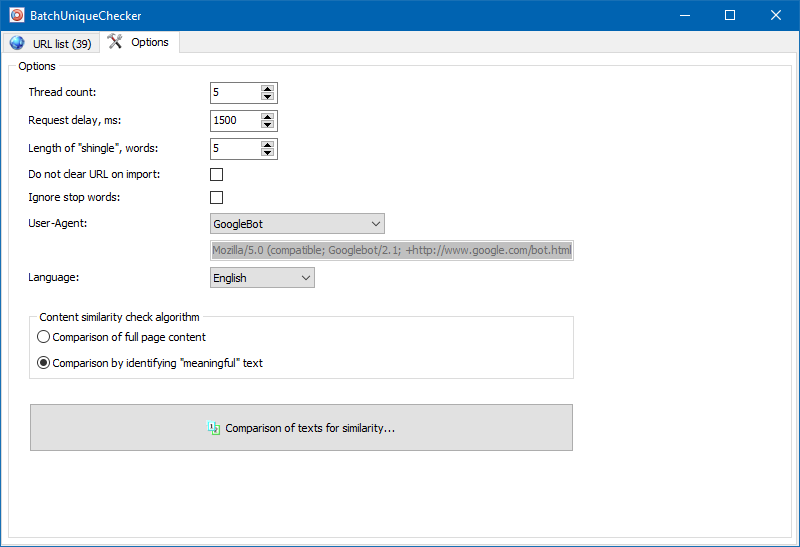
Smysluplné texty
Kromě fulltextového srovnání obsahu program obsahuje algoritmus pro "inteligentní" izolaci tzv. "Významných" textů.
To znamená, že z HTML kódu stránky získáme pouze obsah obsažený ve značkách H1-H6, P, PRE a LI. Z tohoto důvodu tak nějak zahodíme vše "nevýznamné", například obsah z navigační nabídky webu, text ze zápatí nebo postranní nabídky.
V důsledku takových manipulací získáme pouze "smysluplný" obsah stránky, který ve srovnání s jinými stránkami zobrazí přesnější výsledky jedinečnosti.
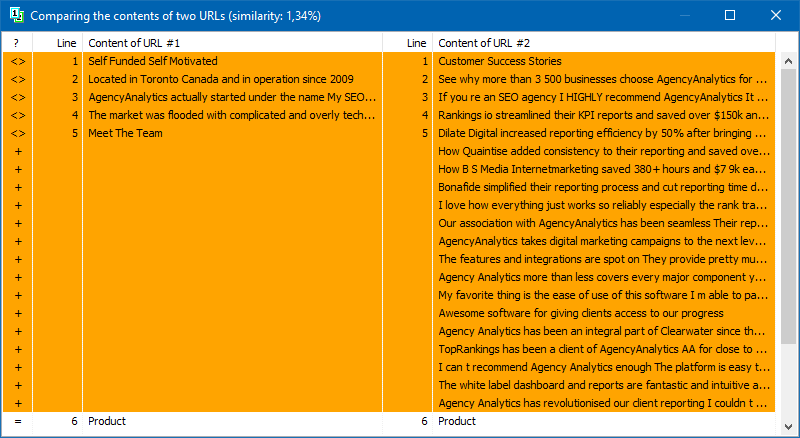
Seznam stránek pro jejich následnou analýzu lze přidat několika způsoby: vložením ze schránky, načtením z textového souboru nebo importem ze souboru Sitemap.xml z disku počítače.
Kvůli vícevláknovému provozu programu může kontrola stovek a více adres URL trvat jen několik minut, což v manuálním režimu, prostřednictvím online služeb, může trvat den i více.
Získáte tak jednoduchý nástroj pro rychlou kontrolu jedinečnosti obsahu pro skupinu adres URL, který lze spustit i z vyměnitelného média.
BatchUniqueChecker je zdarma, zabírá v archivu pouze 4 MB a nevyžaduje instalaci.
Vše, co potřebujete, je stáhnout si distribuční sadu a přidat seznam požadovaných adres URL k ověření, které lze získat prostřednictvím bezplatného programu technického auditu SiteAnalyzer.

Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Ostatní články



















