






















 1,715
1,715Пытанне вызначэння дублікатаў старонак і ўнікальнасці тэкстаў у самой сайта з'яўляецца адным з важнейшых у спісе работ па тэхнічным аўдыту. Ад наяўнасці дубляў старонак залежыць як агульнае самаадчуванне сайта, так і размеркаванне краулингового бюджэту пошукавых сістэм, магчыма выдаткоўванага марна, ды і ў цэлым ранжыраванне сайта можа адчуваць цяжкасці з-за вялікай колькасці дубляваць кантэнту.

І калі для праверкі ўнікальнасці асобных тэкстаў у інтэрнэце можна лёгка знайсці вялікую колькасць сэрвісаў і праграм, то для праверкі ўнікальнасці групы пэўных URL паміж сабой падобных сэрвісаў існуе не шмат, хоць сама па сабе праблема з'яўляецца важнай і актуальнай.
Якія варыянты праблем з не унікальным кантэнтам могуць быць на сайце?
1. Аднолькавы кантэнт па розных URL.
Звычайна гэта старонка з параметрамі і тая ж самая старонка, але ў выглядзе ЧПУ (чалавека-зразумелы урл).
- прыклад:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Гэта досыць распаўсюджаная праблема, калі пасля налады ЧПУ, праграміст забывае наладзіць 301 рэдырэкт са старонак з параметрамі на старонкі з ЧПУ.
Дадзеная праблема лёгка вырашаецца любым вэб-краулером, якой параўнаўшы усе старонкі сайта, выявіць, што ў дзвюх з іх аднолькавыя хэш-коды (MD5), і паведаміць пра гэта аптымізатар, якому застанецца паставіць задачу, усё таго ж праграмісту, на ўстаноўку 301 рэдырэкт на старонкі з ЧПУ.
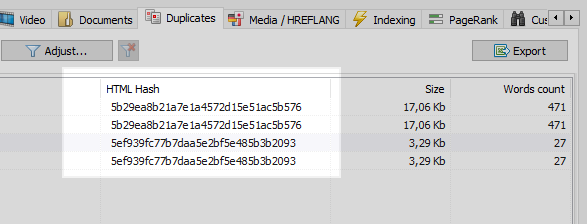
Аднак не ўсе бывае так адназначна.
2. Часткова супадае кантэнт.
Падобны кантэнт утворыцца, калі мы маем розныя старонкі, але, па сутнасці, з аднолькавым або падобным зместам.
прыклад 1
На сайце па продажы пластыкавых вокнаў, у навінавым раздзеле, копірайтэр год таму напісаў віншаванне з 8 сакавіка на 500 знакаў і даў зніжку на ўстаноўку пластыкавых вокнаў у 15%.
А ў гэтым годзе кантэнт-менеджэр вырашыў "схалтурыў", і не мудруючы, знайшоў раней размешчаную навіна са зніжкамі, скапіяваў яе, і замяніў памер скідкі з 15 на 12% + дапісаў ад сябе 50 знакаў з дадатковымі віншаваннямі.
Такім чынам, у выніку мы маем два практычна ідэнтычных тэксту, падобных на 90%, якія самі па сабе з'яўляюцца невыразнымі дублікатамі, аднаму з якіх па добрым патрабуе тэрміновага рерайт.
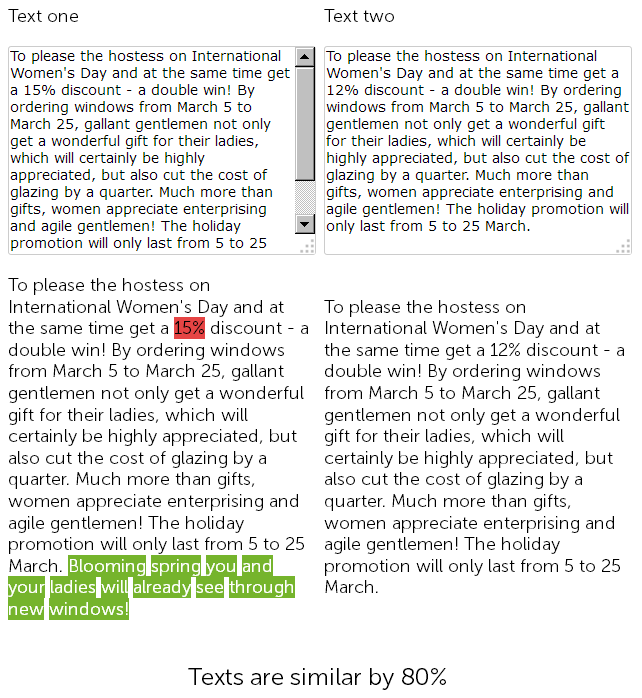
Пры гэтым, для сэрвісаў тэхнічнага аўдыту дадзеныя дзве навіны будуць рознымі, так як ЧПУ на сайце ўжо настроены, і кантрольныя сумы ў старонак не супадуць, як ні круці.
У выніку, якая з старонак будзе ранжыраваць лепш - вялікае пытанне ...
Але навіны яны такія - маюць ўласцівасць хутка састараваць, таму возьмем прыклад цікавей.
прыклад 2
У вас на сайце ёсць артыкульнага раздзел, альбо вы вядзеце асабістую старонку па сваім хобі / захапленню, напрыклад гэта "кулінарны блог".
І, да прыкладу, у вашым блогу набралася ўжо парадкам артыкулаў за ўвесь час, больш за 100, а то і зусім некалькі сотняў. І вось вы падабралі тэму і напісалі новую артыкул, размясцілі, а пасля нейкім чынам выявілася, што аналагічны артыкул ужо была напісана 3 гады таму. Хоць, здавалася б, перад напісаннем кантэнту вы прабеглі па ўсім назвах, адкрылі Excel са спісам размешчаных тым, але не ўлічылі, што мінулае змесціва артыкула "Як прыгатаваць гарачы шакалад у хатніх умовах" моцна супадае з толькі што напісаным матэрыялам. А пры праверцы гэтых двух артыкулаў у адным з онлайн-сэрвісаў атрымліваецца, што яны ўнікальныя паміж сабой на 78%, што, вядома ж, не добра, бо з-за частковага дублявання ўзнікае канибализация пошукавых запытаў паміж гэтымі старонкамі, а ў пошукавай сістэмы ўзнікаюць пытанні і складанасці пры ранжыраванні падобных дубляў.
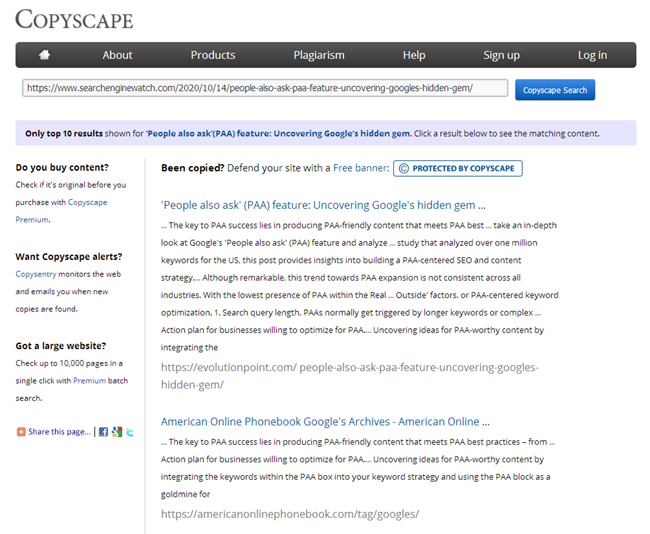
Само сабой, кожны копірайтэр пасля напісання артыкула павінен правяраць яе на унікальнасць ў адным з вядомых сэрвісаў, а кожны сошнікі абавязаны правяраць новы кантэнт пры размяшчэнні на сайце ў тых жа сэрвісах.
Але, што рабіць, калі да вас толькі-толькі прыйшоў сайт на прасоўванне і вам трэба аператыўна праверыць усе яго старонкі на дублі? Альбо, на світанку адкрыцця свайго блога вы напісалі кучу аднатыпных артыкулаў, а цяпер, хутчэй за ўсё з-за іх сайт пачаў асядаць. Не правяраць ж рукамі 100500 старонак у онлайн сэрвісах, дадаючы на праверку кожны артыкул рукамі і затрачваючы на гэта процьму часу.
BatchUniqueChecker
Менавіта для гэтага мы і стварылі праграму BatchUniqueChecker, прызначаную для пакетнай праверкі групы URL на унікальнасць паміж сабой.
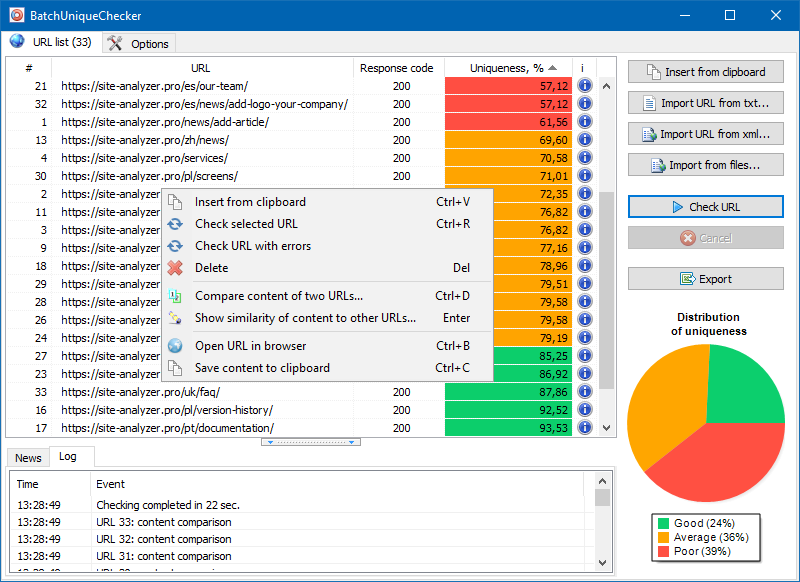
Прынцып працы BatchUniqueChecker просты: па загадзя падрыхтаваным спісе URL праграма запампоўвае іх змесціва, атрымлівае PlainText (тэкставае змесціва старонкі без блока HEAD і без HTML-тэгаў), а затым пры дапамозе алгарытму шинглов параўноўвае іх адзін з адным.
Такім чынам, пры дапамозе шинглов мы вызначаем унікальнасць старонак і можам вылічыць як поўныя дублі старонак з 0% унікальнасцю, так і частковыя дублі з рознымі ступенямі унікальнасці тэкставага змесціва.
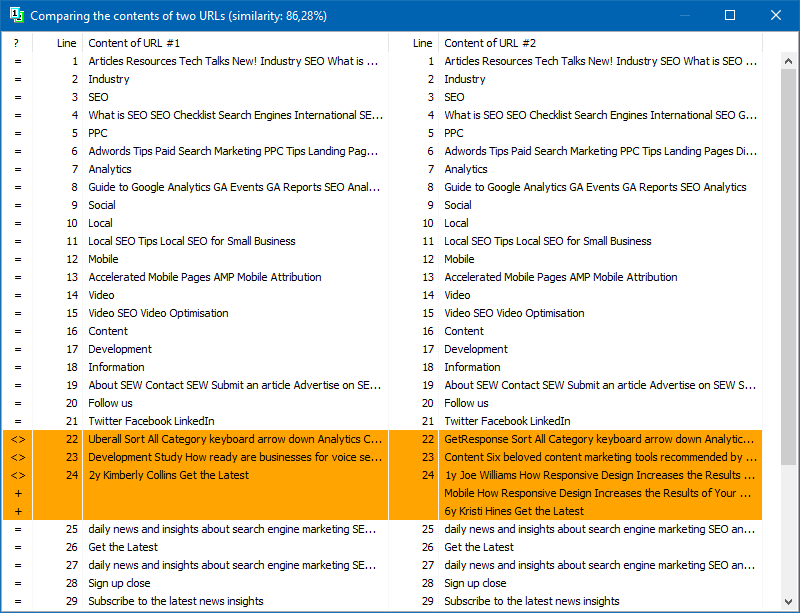
У наладах праграмы ёсць магчымасць ручной ўстаноўкі памеру шингла (шингл - гэта колькасць слоў у тэксце, кантрольная сума якіх напераменку параўноўваецца з наступнымі групамі). Мы рэкамендуем ўсталяваць значэнне = 4. Для вялікіх аб'ёмаў тэксту ад 5 і вышэй. Для адносна невялікіх аб'ёмаў - 3-4.
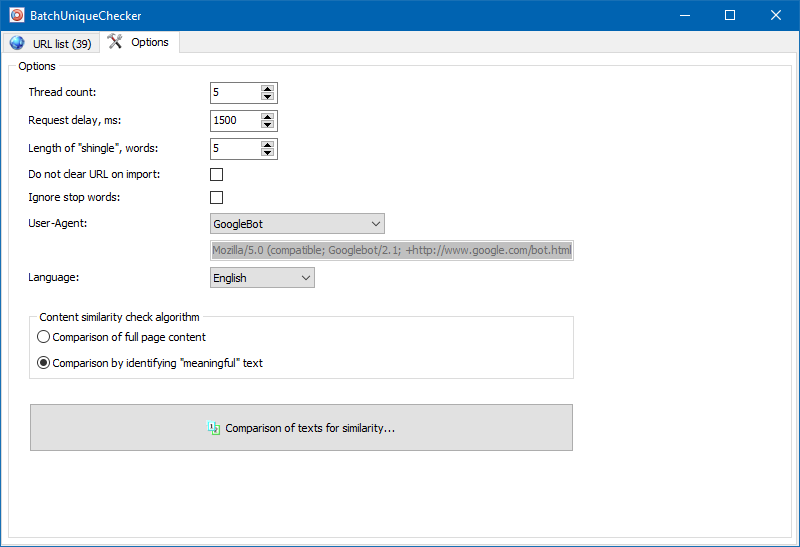
значныя тэксты
Акрамя паўнатэкставага параўнання кантэнту, у праграму закладзены алгарытм "разумнага" вылучэння так званых "значных" тэкстаў.
Гэта значыць, з HTML-кода старонкі мы атрымліваем толькі толькі кантэнт, які змяшчаецца ў тэгах H1-H6, P, PRE і LI. За кошт гэтага мы як бы адкідаем ўсё "не значнае", напрыклад, кантэнт з меню навігацыі сайтаў, тэкст з футера альбо бакавога меню.
У выніку падобных маніпуляцый мы атрымліваем толькі "значны" кантэнт старонак, які пры параўнанні пакажа больш дакладныя вынікі унікальнасці з іншымі старонкамі.
Спіс старонак для іх наступнага аналізу можна дадаць некалькімі спосабамі: ўставіць з буфера абмену, загрузіць з тэкставага файла, альбо імпартаваць з Sitemap.xml з дыска вашага кампутара.
Дзякуючы шматструменнай працы праграмы, праверка сотні і больш URL можа заняць усяго некалькі хвілін, на што ў ручным рэжыме, праз анлайн-сэрвісы, мог бы сысці дзень або больш.
Такім чынам, вы атрымліваеце просты інструмент для аператыўнай праверкі ўнікальнасці кантэнту для групы URL, які можна запускаць нават са зменнага носьбіта.
BatchUniqueChecker бясплатная, займае ўсяго 4 Мб ў архіве і не патрабуе ўсталёўкі.
Усё што неабходна для пачатку працы - спампаваць дыстрыбутыў і дадаць на праверку спіс цікавяць URL, якія можна атрымаць праз бясплатную праграму тэхнічнага аўдыту SiteAnalyzer.
Iншыя артыкулы



















