





















 1,366
1,366Поздрав свима! Вратили смо се у посао!
После веома дугог периода, коначно смо припремили ново издање SiteAnalyzer, које ће, надамо се, испунити ваша очекивања и постаће незаменљив асистент у SEO промоцији.
У новој верзији SiteAnalyzer имплементирали смо неколико најтраженијих функција корисника, као што су: стругање података (издвајање података са веб локације), провера јединствености садржаја и провера брзине учитавања странице помоћу Google PageSpeed. Истовремено, многе грешке су отклоњене и логотип је преуређен. Хајде да разговарамо о свему детаљније.

Главне промене
1. Стругање података помоћу XPath, CSS, XQuery, RegEx.
Веб стругање је аутоматизовани поступак издвајања података са страница које вас занимају на веб локацији у складу са одређеним правилима.
Главне методе стругања на мрежи су методе рашчлањивања користећи XPath, CSS селекторе, XQuery, RegEx и HTML предлошке.
- XPath је посебан језик упита за XML / XHTML елементе документа. Да би приступио елементима, КСПатх користи ДОМ навигацију описујући путању до жељеног елемента на страници. Уз његову помоћ можете добити вредност елемента према његовом редном броју у документу, извући његов текст или интерни код, проверити присуство одређеног елемента на страници.
- CSS селектори се користе за проналажење елемента његовог дела (атрибута). ЦСС је синтаксички сличан КСПатх-у, али у неким случајевима ЦСС локатори су бржи и описнији су и концизнији. Лоша страна CSS-а је та што делује само у једном смеру - дубље у документ. XPath, с друге стране, функционише у оба смера (на пример, дете може да тражи родитељски елемент).
- XQuery је заснован на КСПатх-у. КСКуери опонаша XML, који вам омогућава да креирате угнежђене изразе на начин који у XSLT није могућ.
- RegEx је формални језик за претрагу за издвајање вредности из скупа текстуалних низова који одговарају траженим условима (регуларни израз).
- HTML предлошци је језик за издвајање података из HTML докумената, који је комбинација HTML означавања за описивање предлошка претраживања за жељени фрагмент, плус функције и операције за издвајање и трансформисање података.
Типично, стругање се користи за решавање задатака са којима је тешко ручно руковати. То може бити издвајање описа производа за стварање нове Интернет продавнице, стругање у маркетиншким истраживањима ради праћења цена или надгледања огласа.

У SiteAnalyzer-у је стругање конфигурисано на картици Извлачење података, где су конфигурисана правила извлачења. Правила се могу сачувати и, ако је потребно, уредити.
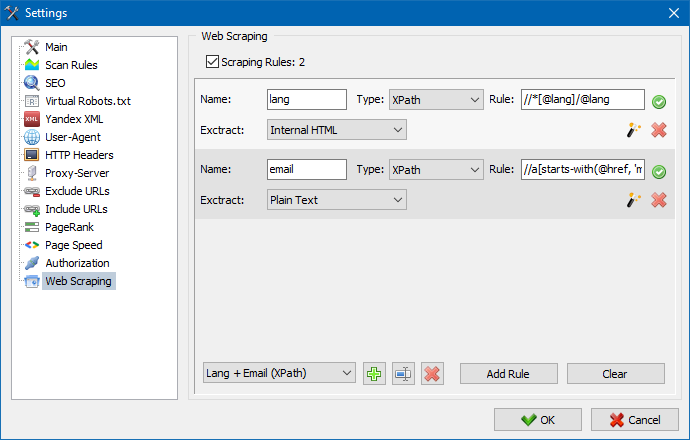
Постоји и модул за испитивање правила. Коришћењем уграђеног програма за отклањање погрешака са правила можете брзо и лако добити ХТМЛ садржај било које странице на веб локацији и тестирати рад упита, а затим користити исправљена погрешка за рашчлањивање података у SiteAnalyzerу.

Након завршетка издвајања података, све прикупљене информације могу се извести у Excel.
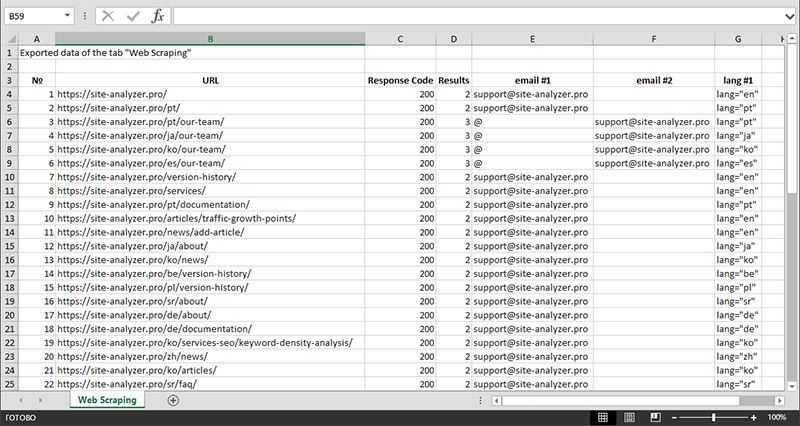
За детаљнију студију рада модула и листу најчешћих правила и регуларних израза, погледајте чланак
2. Провера јединствености садржаја на веб локацији.
Овај алат вам омогућава да претражите дупликате страница и проверите јединственост текстова на веб локацији. Другим речима, ово је групна провера међусобне јединствености групе URL-ова.
Ово може бити корисно у случајевима:
- Да бисте тражили пуне дупликате страница (на пример, страницу са параметрима и исту страницу, али у ЦНЦ приказу).
- За тражење делимичних подударања садржаја (на пример, два рецепта за боршч у кулинарском блогу, који су међусобно слични за 96%, што сугерише да један од чланака треба избрисати како би се решили могуће канибализације саобраћаја).
- Када сте на веб локацији са чланком случајно написали чланак на тему коју сте већ писали пре 10 година. У овом случају, наш алат ће такође открити дупликат таквог чланка.
Принцип алата за проверу јединствености садржаја је једноставан: програм преузима њихов садржај са листе URL-ова веб локација, прима текстуални садржај странице (без блока ХЕАД и без ХТМЛ тагова), а затим их упоређује са сваким други користећи алгоритам шиндре.

Дакле, помоћу шиндре утврђујемо јединственост страница и можемо израчунати како пуне дупликате страница са 0% јединствености, тако и делимичне дупликате са различитим степеном јединствености садржаја текста. Програм ради са шиндром дужине 5.
У овом чланку можете сазнати више о томе како модул функционише.: >>
3. Провера брзине учитавања страница помоћу Google PageSpeed.
Алат Google PageSpeed гиганта омогућава вам да проверите брзину учитавања одређених елемената странице, а такође приказује и укупну оцену брзине учитавања УРЛ адреса од интереса за верзије прегледача за рачунаре и мобилне уређаје.

Гоогле-ова алатка је добра за све, међутим, она има један значајан недостатак - не дозвољава вам да креирате групне провере URL адреса, што ствара непријатности приликом провере многих страница ваше веб локације: сложите се да ручно проверавате брзину преузимања за 100 или више URL адреса на једна страница је досадан посао и може потрајати много времена.
Због тога смо креирали модул који вам омогућава да бесплатно креирате групне провере брзине учитавања странице путем посебног API у алатки Google PageSpeed Insights.

Главни анализирани параметри:
- FCP (First Contentful Paint) – време за приказ првог садржаја.
- SI (Speed Index) – показатељ колико се брзо садржај приказује на страници.
- LCP (Largest Contentful Paint) – приказ времена за највећи елемент на страници.
- TTI (Time to Interactive) – време током ког страница постаје потпуно спремна за интеракцију са корисником.
- TBT (Total Blocking Time) – време од првог приказивања садржаја до његове спремности за корисничку интеракцију.
- CLS (Cumulative Layout Shift) – кумулативни помак распореда. Служи за мерење визуелне стабилности странице.
Због рада SiteAnalyzer са више нити, провера стотина или више УРЛ-ова може потрајати само неколико минута, што може трајати један дан или више у ручном режиму путем прегледача.
Истовремено, анализа самог УРЛ-а одвија се у само неколико кликова, након чега се може преузети извештај, укључујући главне карактеристике провера у прикладном облику у програму Екцел.
Све што вам је потребно је да набавите API кључ.
Како се то ради описано је у овом чланку. >>
4. Додата могућност груписања пројеката по директоријумима.
За практичнију навигацију кроз листу пројеката додата је могућност груписања веб локација по директоријумима.

Поред тога, постало је могуће филтрирати листу пројеката по имену.
5. Ажуриран је интерфејс подешавања програма.
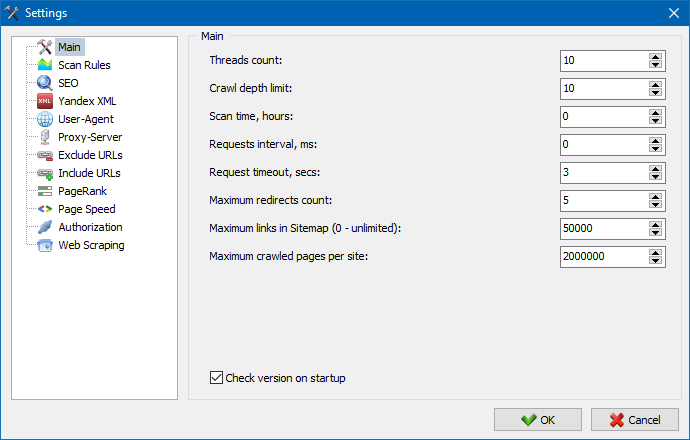
Ширењем функционалности програма постало нам је "тесно" да користимо картице, па смо прозор поставки преформатирали у разумљивији и функционалнији интерфејс.
Напомене:
- поправљено нетачно рачуноводство изузетака URL
- поправљено нетачно рачуноводство дубине пузања локације
- враћен приказ преусмеравања за URL адресе увезене из датотеке
- вратио могућност преуређивања и памћења редоследа колона у картицама
- вратио рачуноводство неканонских страница, решио проблем са празним метатаговима
- враћен приказ сидра везе на картици Инфо
- убрзани увоз великог броја URL адреса из привремене меморије
- фиксирано не увек тачно рашчлањивање наслова и описа
- враћен приказ алт-а и наслова на сликама
- фиксно замрзавање приликом преласка на картицу "Спољне везе" током скенирања пројекта
- исправила грешку која се догодила приликом пребацивања између пројеката и ажурирања чворова на картици "Статистика пописивања веб локација"
- исправљена нетачна дефиниција нивоа гнежђења за URL са параметрима
- фиксно сортирање података по HTML-хеш пољу у главној табели
- оптимизован рад програма са ћириличним доменима
- ажурирани интерфејс за подешавања програма
- ажурирани дизајн логотипа

Преглед претходних верзија:
- Преглед нове верзије SiteAnalyzer 2.2
- Преглед нове верзије SiteAnalyzer 2.1
- Преглед нове верзије SiteAnalyzer 2.0



















