






















 1,926
1,926A questão de apurar páginas duplicadas e a unicidade dos textos dentro do site é uma das mais importantes na lista de trabalhos de auditoria técnica. A presença de páginas duplicadas determina o bem-estar geral do site e a distribuição do orçamento de rastreamento do mecanismo de pesquisa, que pode ser desperdiçado e, em geral, a classificação do site pode ser difícil devido à grande quantidade de conteúdo duplicado.

E se você pode encontrar facilmente um grande número de serviços e programas para verificar a exclusividade de textos individuais na Internet, então não existem muitos serviços semelhantes para verificar a exclusividade de um grupo de URLs específicos entre si, embora o problema em si seja importante e relevante.
Quais opções para problemas com conteúdo não exclusivo podem estar no site?
1. Mesmo conteúdo para URLs diferentes.
Normalmente esta é uma página com parâmetros e a mesma página, mas na forma de um SEF (URL legível).
- Exemplo:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Este é um problema bastante comum quando, após configurar o SEF, o programador se esquece de configurar um redirecionamento 301 de páginas com parâmetros para páginas com SEF.
Este problema pode ser facilmente resolvido por qualquer web crawler, que, tendo comparado todas as páginas do site, vai descobrir que duas delas possuem os mesmos hash codes (MD5), e informar ao otimizador, que terá que configurar a tarefa, o mesmo programador, para instalar 301 redirecionamentos para páginas SEF.
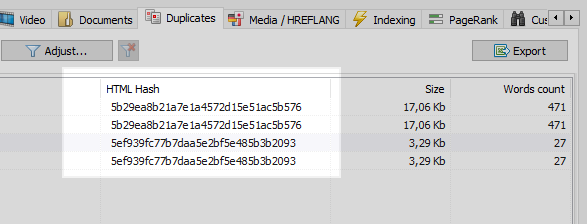
No entanto, nem tudo é tão simples.
2. Conteúdo sobreposto.
Conteúdo semelhante é gerado quando temos páginas diferentes, mas, na verdade, com conteúdo igual ou semelhante.
Exemplo 1
No site de venda de janelas de plástico, na seção de notícias, há um ano, um redator escreveu um parabéns no dia 8 de março por 500 caracteres e deu um desconto de 15% na instalação de janelas de plástico.
E este ano, o gestor de conteúdos decidiu "trapacear" e, sem mais delongas, encontrou a notícia anteriormente publicada com descontos, copiou-a e alterou o tamanho do desconto de 15 para 12% + acrescentou 50 sinais dele próprio com parabéns adicionais.
Assim, no final, temos dois textos quase idênticos, 90% semelhantes, que em si são duplicatas difusas, uma das quais, por um bom motivo, requer uma reescrita urgente.
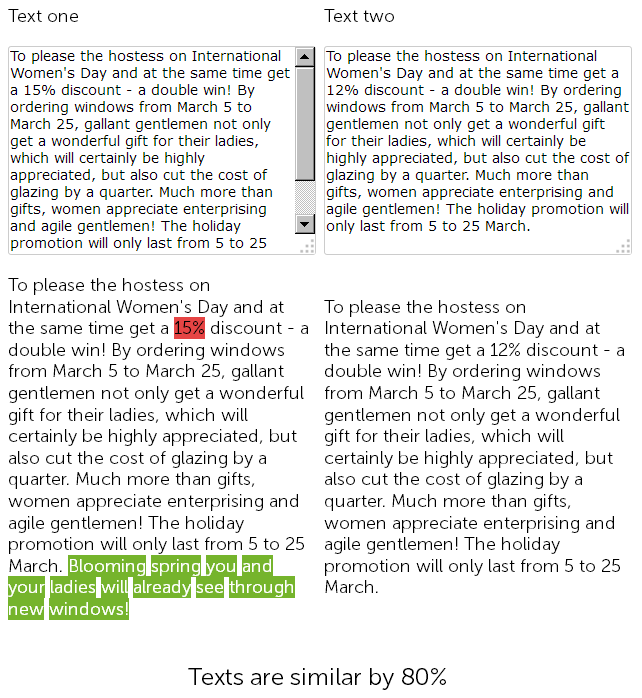
Ao mesmo tempo, para os serviços de auditoria técnica, estas duas notícias serão diferentes, visto que o SEF do site já está configurado e os checksums das páginas não coincidem, digamos assim.
No final das contas, qual página terá melhor classificação é uma grande questão ...
Mas eles são uma notícia - eles tendem a ficar desatualizados rapidamente, então vamos dar um exemplo mais interessante.
Exemplo 2
Você tem uma seção de artigos no seu site, ou mantém uma página pessoal para o seu hobby / hobby, por exemplo, é um "blog de culinária".
E, por exemplo, seu blog já acumulou uma ordem de artigos para o tempo todo, mais de 100, ou mesmo várias centenas. E então você pegou um tópico e escreveu um novo artigo, postou e, mais tarde, de alguma forma descobriu que um artigo semelhante já havia sido escrito há 3 anos. Embora pareça que antes de escrever o conteúdo, você percorreu todos os títulos, abriu o Excel com uma lista de tópicos postados, mas não levou em consideração que o conteúdo anterior do artigo "Como fazer chocolate quente em casa" coincide fortemente com o material que acabou de escrever. E ao verificar estes dois artigos num dos serviços online, verifica-se que são 78% únicos entre si, o que, claro, não é bom, pois devido à duplicação parcial ocorre uma canibalização das consultas de pesquisa entre estas páginas e o motor de pesquisa questões e dificuldades surgem ao classificar essas duplicatas.
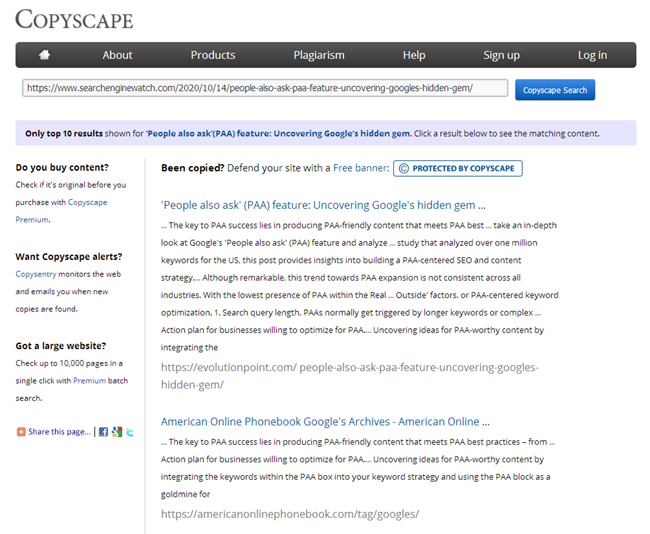
Obviamente, depois de escrever um artigo, todo redator deve verificar se ele é único em um dos serviços mais conhecidos, e todo SEO é obrigado a verificar o novo conteúdo quando postado no site nos mesmos serviços.
Mas o que fazer se um site acabou de chegar até você para promoção e você precisa verificar rapidamente todas as páginas em busca de duplicatas? Ou, no início da abertura do seu blog, você escreveu um monte de artigos do mesmo tipo, e agora, muito provavelmente, por causa deles, o site começou a afundar. Não cheque manualmente 100.500 páginas nos serviços online, somando para verificar cada artigo manualmente e gastando muito tempo nisso.
BatchUniqueChecker
É por isso que criamos o programa BatchUniqueChecker, projetado para verificar em lote um grupo de URLs quanto à exclusividade entre eles.
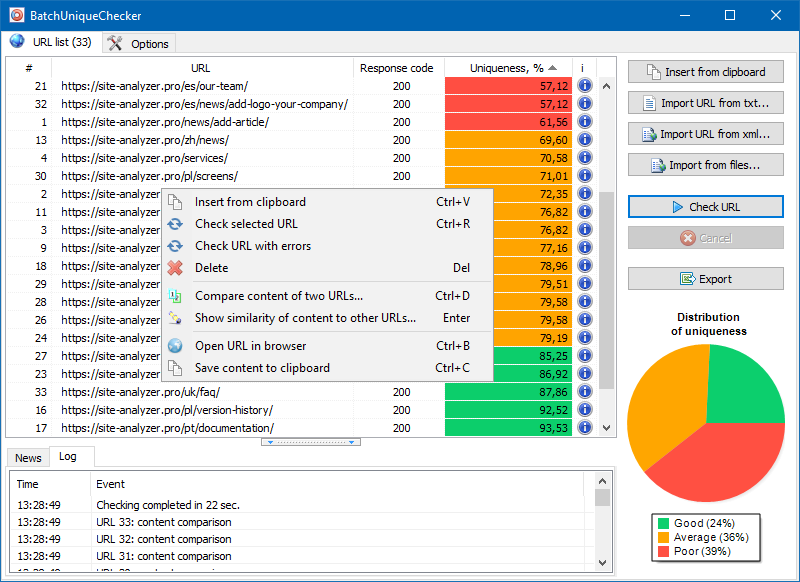
O princípio de operação do BatchUniqueChecker é simples: o programa baixa seu conteúdo usando uma lista pré-preparada de URLs, recebe PlainText (conteúdo de texto da página sem um bloco HEAD e sem tags HTML) e então os compara entre si usando o algoritmo shingle.
Assim, usando telhas, determinamos a exclusividade das páginas e podemos calcular duplicatas completas de páginas com 0% de exclusividade e duplicatas parciais com vários graus de exclusividade do conteúdo do texto.
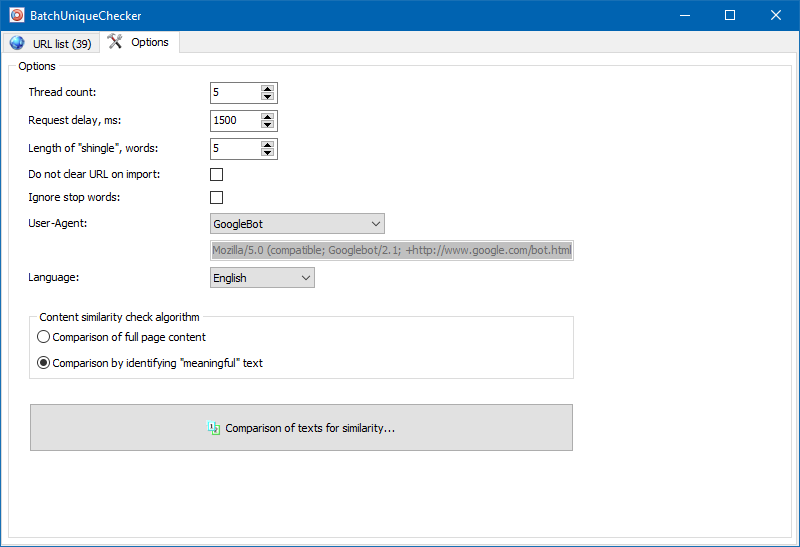
Nas configurações do programa, você pode definir manualmente o tamanho do shingle (shingle é o número de palavras no texto, cujo checksum é alternadamente comparado com os grupos subsequentes). Recomendamos definir o valor = 4. Para grandes quantidades de texto a partir de 5. Para volumes relativamente pequenos - 3-4.
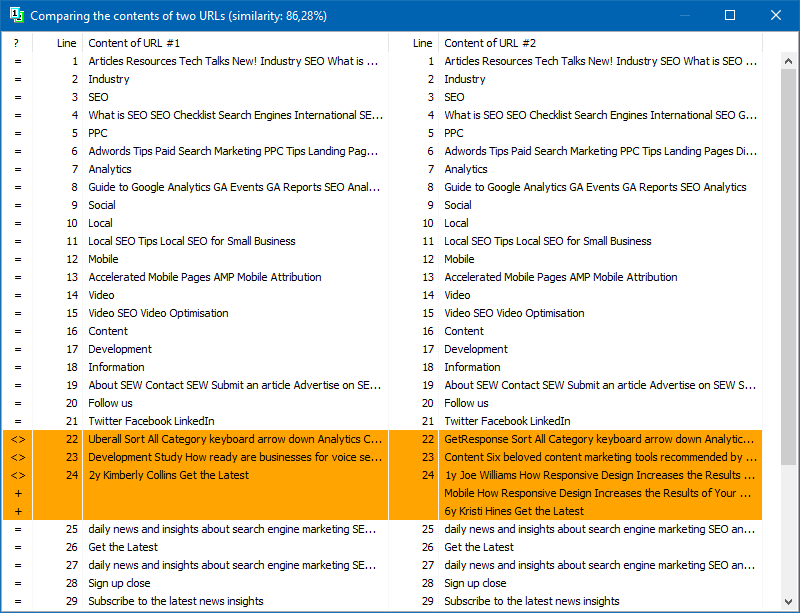
Textos significativos
Além da comparação de conteúdo de texto completo, o programa inclui um algoritmo para isolamento "inteligente" dos chamados textos "significativos".
Ou seja, a partir do código HTML da página, obtemos apenas o conteúdo contido nas tags H1-H6, P, PRE e LI. Devido a isso, nós meio que descartamos tudo que não for "significativo", por exemplo, conteúdo do menu de navegação do site, texto do rodapé ou menu lateral.
Como resultado de tais manipulações, obtemos apenas conteúdo de página "significativo" que, quando comparado, mostrará resultados de exclusividade mais precisos com outras páginas.
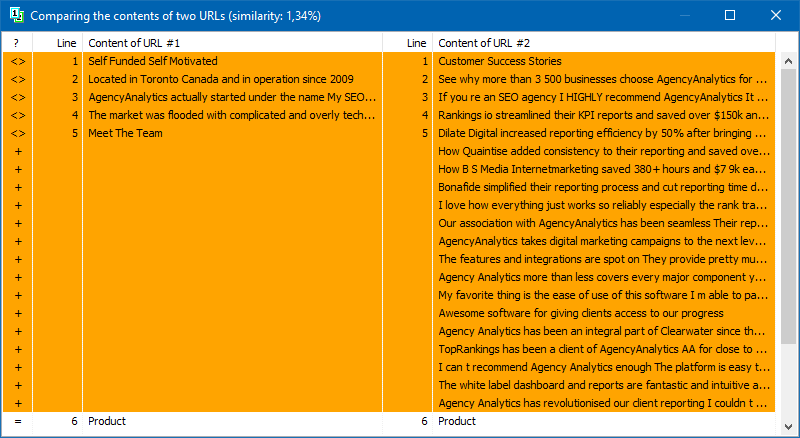
A lista de páginas para sua análise subsequente pode ser adicionada de várias maneiras: colar da área de transferência, carregar de um arquivo de texto ou importar de Sitemap.xml do disco do seu computador.
Devido ao funcionamento multithread do programa, a verificação de centenas ou mais URLs pode demorar apenas alguns minutos, o que no modo manual, através dos serviços online, pode demorar um dia ou mais.
Assim, você obtém uma ferramenta simples para verificar rapidamente a exclusividade do conteúdo de um grupo de URLs, que pode ser executado até mesmo em mídia removível.
BatchUniqueChecker é gratuito, ocupa apenas 4 MB no arquivo e não requer instalação.
Tudo o que você precisa para começar é baixar o kit de distribuição e adicionar uma lista de URLs de interesse para verificação, que pode ser obtida por meio de um programa gratuito de auditoria técnica SiteAnalyzer.
Outros artigos



















