





















 3,281
3,281Cześć wszystkim! Wracamy do biznesu!
Po bardzo długim okresie przygotowaliśmy wreszcie nową wersję SiteAnalyzera, która mamy nadzieję, że spełni Twoje oczekiwania i stanie się niezastąpionym pomocnikiem w promocji SEO.
W nowej wersji SiteAnalyzer zaimplementowaliśmy kilka najbardziej pożądanych przez użytkowników funkcji, takich jak: data scraping (pobieranie danych ze strony), sprawdzanie unikalności treści oraz sprawdzanie szybkości ładowania strony przez Google PageSpeed. Jednocześnie naprawiono wiele błędów i zmieniono stylizację logo. Porozmawiajmy o wszystkim bardziej szczegółowo.

Główne zmiany
1. Skrobanie danych za pomocą XPath, CSS, XQuery, RegEx.
Web scraping to zautomatyzowany proces wydobywania danych z interesujących stron w witrynie zgodnie z określonymi zasadami.
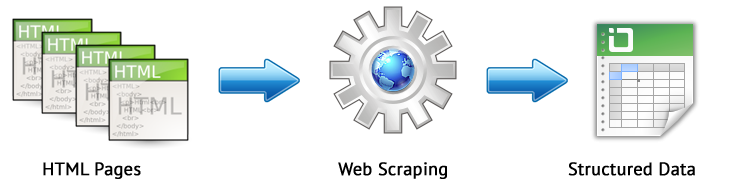
Głównymi metodami web scrapingu są metody parsowania wykorzystujące XPath, selektory CSS, szablony XQuery, RegExp i HTML.
- XPath to specjalny język zapytań dla elementów dokumentów XML / XHTML. Aby uzyskać dostęp do elementów, XPath używa nawigacji DOM, opisując ścieżkę do żądanego elementu na stronie. Za jego pomocą można uzyskać wartość elementu po jego numerze porządkowym w dokumencie, wyodrębnić jego zawartość tekstową lub kod wewnętrzny, sprawdzić obecność określonego elementu na stronie.
- Selektory CSS służą do znalezienia elementu jego części (atrybutu). CSS jest składniowo podobny do XPath, ale w niektórych przypadkach lokalizatory CSS są szybsze, bardziej opisowe i zwięzłe. Wadą CSS jest to, że działa tylko w jednym kierunku - w głąb dokumentu. Z drugiej strony XPath działa w obie strony (na przykład możesz wyszukać element nadrzędny przez dziecko).
- XQuery jest oparty na XPath. XQuery naśladuje XML, który umożliwia tworzenie zagnieżdżonych wyrażeń w sposób, który nie jest możliwy w XSLT.
- RegExp to formalny język wyszukiwania służący do wyodrębniania wartości z zestawu ciągów tekstowych spełniających wymagane warunki (wyrażenie regularne).
- Szablony HTML to język wyodrębniania danych z dokumentów HTML, który jest kombinacją znaczników HTML opisujących szablon wyszukiwania dla żądanego fragmentu oraz funkcji i operacji służących do wyodrębniania i przekształcania danych.
Zazwyczaj skrobanie służy do rozwiązywania zadań trudnych do ręcznego wykonania. Może to być wyodrębnianie opisów produktów w celu stworzenia nowego sklepu internetowego, skrobanie w badaniach marketingowych w celu monitorowania cen lub monitorowania reklam.

W SiteAnalyzer skrobanie jest konfigurowane na karcie Wyodrębnianie danych, na której konfiguruje się reguły wyodrębniania. Reguły można zapisywać i w razie potrzeby edytować.
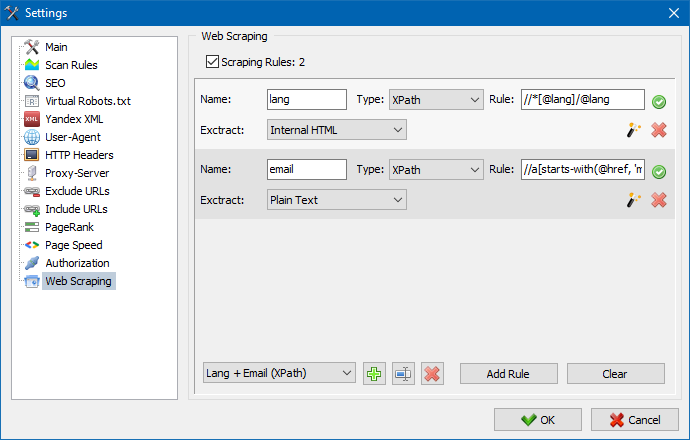
Dostępny jest również moduł testowania reguł. Korzystając z wbudowanego debugera reguł, możesz szybko i łatwo pobrać zawartość HTML dowolnej strony w witrynie i przetestować działanie zapytań, a następnie użyć debugowanych reguł do analizy danych w SiteAnalyzer.

Po zakończeniu ekstrakcji danych wszystkie zebrane informacje można wyeksportować do Excela.
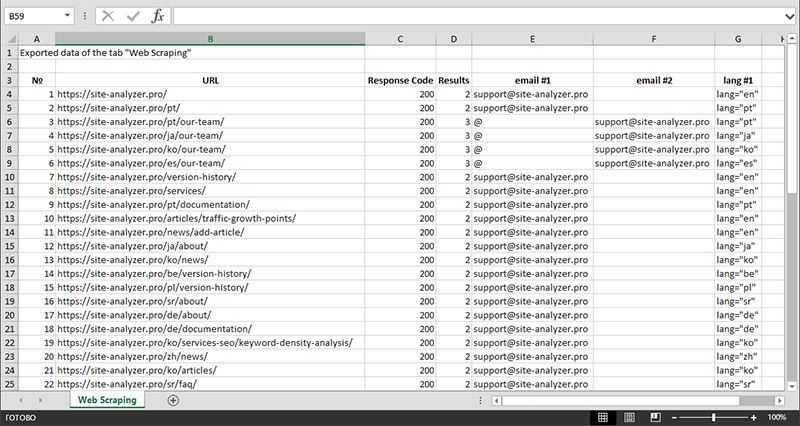
Bardziej szczegółowe badanie działania modułu oraz listę najczęstszych reguł i wyrażeń regularnych można znaleźć w artykule
2. Sprawdzanie unikalności treści w obrębie serwisu.
To narzędzie umożliwia wyszukiwanie duplikatów stron i sprawdzanie unikalności tekstów w serwisie. Innymi słowy, jest to zbiorcze sprawdzenie grupy adresów URL pod kątem niepowtarzalności między sobą.
Może to być przydatne w przypadkach:
- Wyszukiwanie pełnych duplikatów stron (na przykład strony z parametrami i tej samej strony, ale w widoku CNC).
- Aby wyszukać częściowe dopasowania treści (na przykład dwa przepisy barszczowe na blogu kulinarnym, które są do siebie podobne w 96%, co sugeruje, że należy usunąć jeden z artykułów, aby pozbyć się możliwej kanibalizacji ruchu).
- Kiedy na stronie z artykułami przypadkowo napisałeś artykuł na temat, który napisałeś już 10 lat temu. W takim przypadku nasze narzędzie wykryje również duplikat takiego artykułu.
Zasada działania narzędzia do sprawdzania unikalności treści jest prosta: program pobiera ich treść z listy adresów URL witryn, otrzymuje treść tekstową strony (bez bloku HEAD i bez tagów HTML), a następnie porównuje je ze sobą inne przy użyciu algorytmu gontu.

Tak więc za pomocą gontów określamy unikalność stron i możemy obliczyć zarówno pełne duplikaty stron o unikalności 0%, jak i częściowe duplikaty o różnym stopniu unikalności treści tekstowej. Program działa z gontem o długości 5.
Więcej o działaniu modułu dowiesz się z tego artykułu.: >>
3. Sprawdzanie szybkości ładowania stron przez Google PageSpeed.
Narzędzie PageSpeed Insights giganta wyszukiwania Google pozwala sprawdzić szybkość ładowania niektórych elementów strony, a także pokazuje ogólny wynik szybkości ładowania interesujących adresów URL dla wersji przeglądarki na komputery i urządzenia mobilne.

Narzędzie Google jest dobre dla każdego, jednak ma jedną istotną wadę - nie pozwala na tworzenie grupowych kontroli adresów URL, co stwarza niedogodności podczas sprawdzania wielu stron Twojej witryny: zgódź się na ręczne sprawdzanie szybkości pobierania dla 100 lub więcej adresów URL na jedna strona to przykry obowiązek i może zająć dużo czasu.
Dlatego stworzyliśmy moduł, który pozwala za darmo tworzyć grupowe kontrole szybkości ładowania strony poprzez specjalne API w narzędziu Google PageSpeed Insights.

Główne analizowane parametry:
- FCP (First Contentful Paint) – czas na wyświetlenie pierwszej treści.
- SI (Speed Index) – wskaźnik szybkości wyświetlania treści na stronie.
- LCP (Largest Contentful Paint) – czas wyświetlania największego elementu na stronie.
- TTI (Time to Interactive) – czas, w którym strona jest w pełni gotowa do interakcji z użytkownikiem.
- TBT (Total Blocking Time) – czas od pierwszego renderowania treści do gotowości do interakcji użytkownika.
- CLS (Cumulative Layout Shift) – skumulowane przesunięcie układu. Służy do pomiaru stabilności wizualnej strony.
Ze względu na wielowątkową pracę SiteAnalyzer, sprawdzenie setek lub więcej adresów URL może zająć tylko kilka minut, co może zająć dzień lub więcej w trybie ręcznym w przeglądarce.
Jednocześnie analiza samego adresu URL odbywa się za pomocą zaledwie kilku kliknięć, po czym można pobrać raport zawierający główne cechy sprawdzeń w wygodnej formie w Excelu.
Wszystko, czego potrzebujesz, aby zacząć, to zdobyć klucz API.
Jak to zrobić, opisano w tym artykule. >>
4. Dodano możliwość grupowania projektów według folderów.
Dla wygodniejszego poruszania się po liście projektów dodano możliwość grupowania witryn według folderów.

Dodatkowo pojawiła się możliwość filtrowania listy projektów po nazwie.
5. Zaktualizowano interfejs ustawień programu.
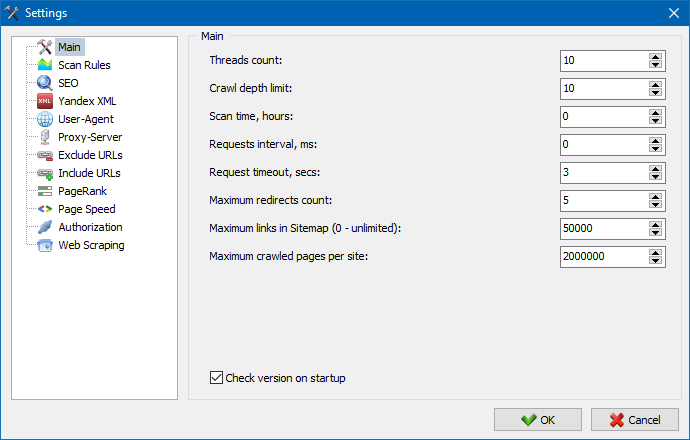
Wraz z rozszerzeniem funkcjonalności programu korzystanie z kart stało się dla nas "ciasne", więc przeformatowaliśmy okno ustawień na bardziej zrozumiały i funkcjonalny interfejs.
Uwagi:
- naprawiono niepoprawne rozliczanie wyjątków URL URL
- naprawiono nieprawidłowe księgowanie głębokości indeksowania witryny site
- przywrócono wyświetlanie przekierowań dla adresów URL importowanych z pliku
- przywrócono możliwość zmiany kolejności i zapamiętywania kolejności kolumn w zakładkach
- przywrócono rozliczanie stron niekanonicznych, rozwiązano problem z pustymi metatagami
- przywrócono wyświetlanie kotwic linków na karcie Informacje
- przyspieszony import dużej liczby adresów URL ze schowka
- naprawiono nie zawsze poprawne parsowanie tytułu i opisu
- przywrócone wyświetlanie alt i tytułu w obrazach
- naprawiono zawieszanie się podczas przełączania do zakładki "Łącza zewnętrzne" podczas skanowania projektu
- naprawiono błąd występujący podczas przełączania między projektami i aktualizacji węzłów zakładki "Statystyki indeksowania witryny"
- naprawiono nieprawidłową definicję poziomu zagnieżdżenia dla adresu URL z parametrami
- poprawiono sortowanie danych według pola haszującego HTML w głównej tabeli
- zoptymalizowana praca programu z domenami cyrylicowymi
- zaktualizowany interfejs ustawień programu
- zaktualizowany projekt logo


Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Przegląd poprzednich wersji:
- Przegląd nowej wersji SiteAnalyzer 2.2
- Przegląd nowej wersji SiteAnalyzer 2.1
- Przegląd nowej wersji SiteAnalyzer 2.0


















