






















 4,078
4,078중복 페이지를 결정하는 문제와 사이트 내 텍스트의 고유성은 기술 감사 작업 목록에서 가장 중요한 문제 중 하나입니다. 중복 페이지의 존재는 사이트의 전반적인 웰빙과 낭비 될 수있는 검색 엔진 크롤링 예산의 분포를 결정하며 일반적으로 많은 양의 중복 콘텐츠로 인해 사이트 순위가 어려울 수 있습니다.

그리고 인터넷에서 개별 텍스트의 고유성을 확인하기 위해 많은 서비스와 프로그램을 쉽게 찾을 수 있다면 문제 자체가 중요하고 관련성이 있지만 특정 URL 그룹의 고유성을 확인하는 유사한 서비스가 많지 않습니다.
고유하지 않은 콘텐츠 문제에 대해 사이트에있을 수있는 옵션은 무엇입니까?
1. 다른 URL에 대해 동일한 콘텐츠.
일반적으로 이것은 매개 변수와 동일한 페이지가있는 페이지이지만 SEF (사람이 읽을 수있는 URL) 형식입니다.
- 예:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
이것은 SEF를 설정 한 후 프로그래머가 매개 변수가있는 페이지에서 SEF가있는 페이지로 301 리디렉션을 설정하는 것을 잊었을 때 매우 일반적인 문제입니다.
이 문제는 사이트의 모든 페이지를 비교 한 결과 두 페이지가 동일한 해시 코드 (MD5)를 가지고 있음을 발견하고 301 리디렉션을 설치하기 위해 동일한 프로그래머 인 작업을 설정해야하는 옵티 마이저에게 알리는 웹 크롤러로 쉽게 해결할 수 있습니다. SEF 페이지에.
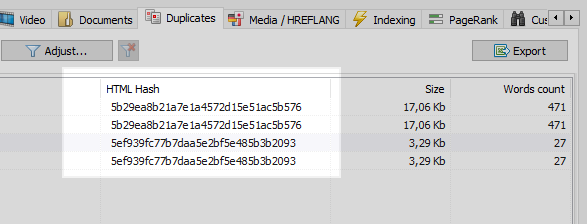
그러나 모든 것이 그렇게 간단하지는 않습니다.
2. 중복 콘텐츠.
유사한 콘텐츠는 페이지가 다르지만 실제로는 같거나 유사한 콘텐츠가있을 때 생성됩니다.
예 1
1 년 전 플라스틱 창문 판매 웹 사이트의 뉴스 섹션에서 카피라이터가 3 월 8 일 500 자 축하를 써서 플라스틱 창문 설치에 대해 15 % 할인을 주었다.
그리고 올해 콘텐츠 관리자는 "속임수"를 결정하고 더 이상 고민하지 않고 이전에 게시 된 뉴스를 할인과 함께 찾아 복사하고 할인을 15 %에서 12 %로 변경하고 추가 축하와 함께 50 개의 사인을 추가했습니다.
따라서 결국 우리는 거의 동일한 두 개의 텍스트 (90 % 유사)를 갖게되는데, 그 자체로는 퍼지 중복이며, 그 중 하나는 정당한 이유로 긴급 재 작성이 필요합니다.
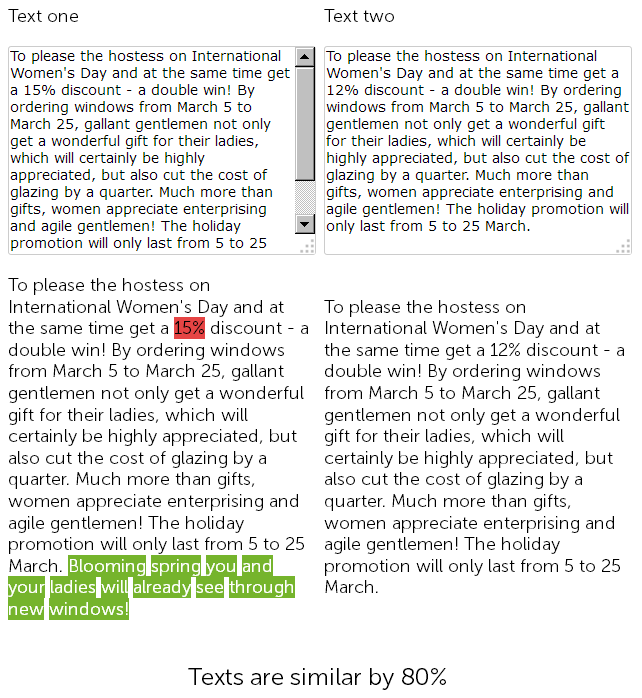
동시에, 기술 감사 서비스의 경우 사이트의 SEF가 이미 구성되어 있고 페이지의 체크섬이 무엇을 말하든 일치하지 않기 때문에이 두 뉴스는 다를 것입니다.
결국 어느 페이지의 순위가 더 좋을지가 큰 문제입니다 ...
그러나 그들은 그러한 뉴스입니다. 그들은 빨리 구식이되는 경향이 있으므로 더 흥미로운 예를 들어 보겠습니다.
예 2
사이트에 기사 섹션이 있거나 취미 / 취미를위한 개인 페이지를 유지합니다 (예 : "요리 블로그").
예를 들어, 귀하의 블로그는 이미 전체 시간 동안 100 개 이상 또는 수백 개 이상의 기사를 축적했습니다. 그래서 당신은 주제를 골라 새로운 기사를 썼고, 그것을 게시했고, 나중에 어떻게 든 비슷한 기사가 이미 3 년 전에 쓰여졌다는 것을 발견했습니다. 내용을 작성하기 전에 모든 제목을 살펴보고 게시 된 주제 목록으로 Excel을 열었지만 "집에서 핫 초콜릿 만드는 법"기사의 과거 내용이 방금 작성한 자료와 강하게 일치한다는 사실을 고려하지 않았습니다. 그리고 온라인 서비스 중 하나 에서이 두 기사를 확인할 때 부분적인 중복으로 인해 이러한 페이지와 검색 엔진 사이에 검색 쿼리가 잠식되기 때문에 78 % 고유 한 것으로 나타났습니다. 물론 좋지 않습니다. 이러한 중복 항목의 순위를 매길 때 질문과 어려움이 발생합니다.
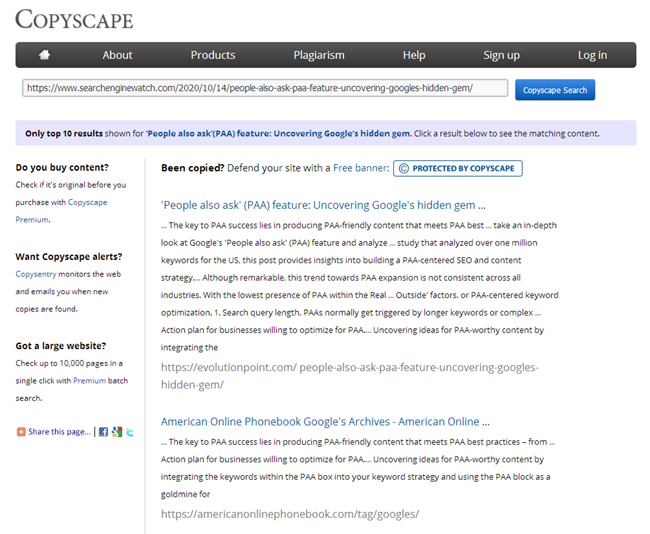
물론 기사를 작성한 후 모든 카피라이터는 잘 알려진 서비스 중 하나에서 고유성을 확인해야하며 모든 SEO는 동일한 서비스에서 사이트에 게시 될 때 새로운 콘텐츠를 확인해야합니다.
그러나 웹 사이트가 홍보를 위해 방금 방문했고 모든 페이지의 중복 여부를 빠르게 확인해야하는 경우 어떻게해야할까요? 또는 블로그를 여는 새벽에 같은 유형의 기사를 많이 썼고 이제는 그로 인해 사이트가 처지기 시작했습니다. 온라인 서비스에서 100,500 페이지를 손으로 확인하지 말고 각 기사를 직접 확인하고 많은 시간을 소비하십시오.
BatchUniqueChecker
이것이 바로 우리가 URL 그룹의 고유성을 일괄 검사하도록 설계된 BatchUniqueChecker 프로그램을 만든 이유입니다.
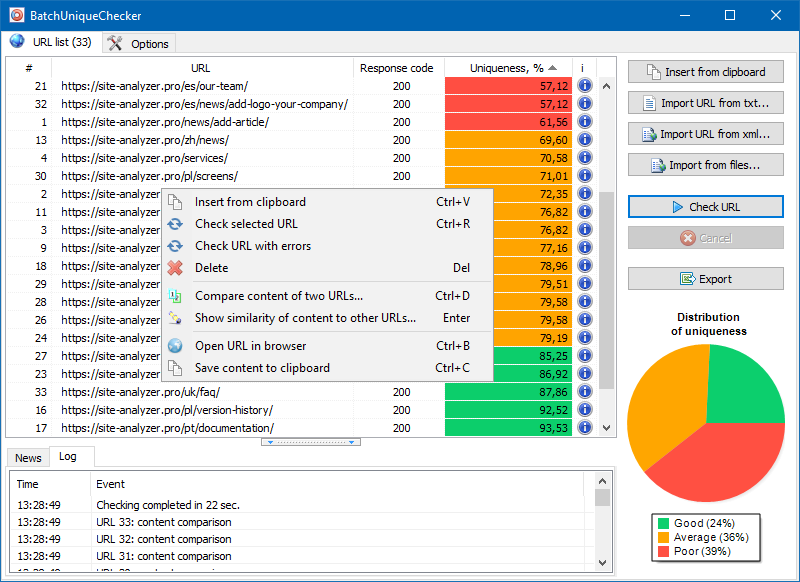
BatchUniqueChecker의 작동 원리는 간단합니다. 프로그램은 미리 준비된 URL 목록을 사용하여 콘텐츠를 다운로드하고 PlainText (HEAD 블록이없고 HTML 태그가없는 페이지의 텍스트 콘텐츠)를 수신 한 다음 shingle 알고리즘을 사용하여 서로 비교합니다.
따라서 대상 포진을 사용하여 페이지의 고유성을 확인하고 고유성이 0 % 인 페이지의 전체 복제와 텍스트 콘텐츠의 고유성이 다양한 부분 복제를 모두 계산할 수 있습니다.
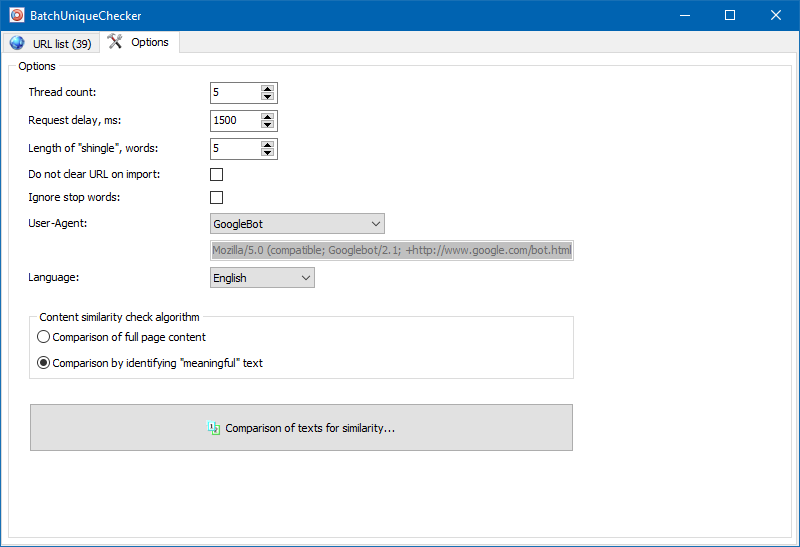
프로그램 설정에서 대상 포진의 크기를 수동으로 설정할 수 있습니다 (싱글은 텍스트의 단어 수이며 체크섬은 후속 그룹과 교대로 비교됨). 값 = 4로 설정하는 것이 좋습니다. 5 이상의 텍스트가 많은 경우. 상대적으로 적은 양의 경우-3-4.
의미있는 텍스트
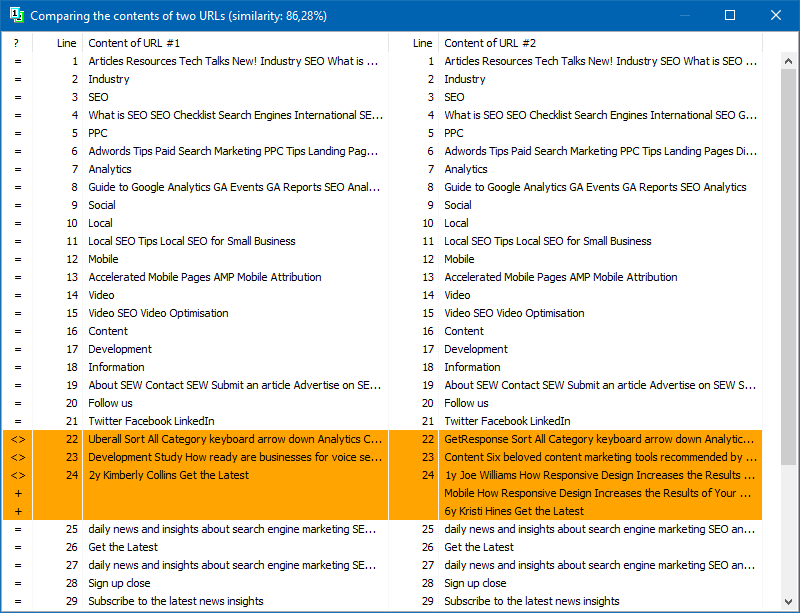
내용의 전체 텍스트 비교 외에도 프로그램에는 소위 "중요한"텍스트의 "스마트"분리 알고리즘이 포함되어 있습니다.
즉, 페이지의 HTML 코드에서 H1-H6, P, PRE 및 LI 태그에 포함 된 콘텐츠 만 수신합니다. 이로 인해 사이트 탐색 메뉴의 콘텐츠, 바닥 글 또는 사이드 메뉴의 텍스트와 같이 "중요하지 않은"모든 것을 삭제합니다.
이러한 조작의 결과로 "의미있는"페이지 콘텐츠 만 얻을 수 있으며, 비교할 때 다른 페이지와 더 정확한 고유성 결과를 보여줍니다.
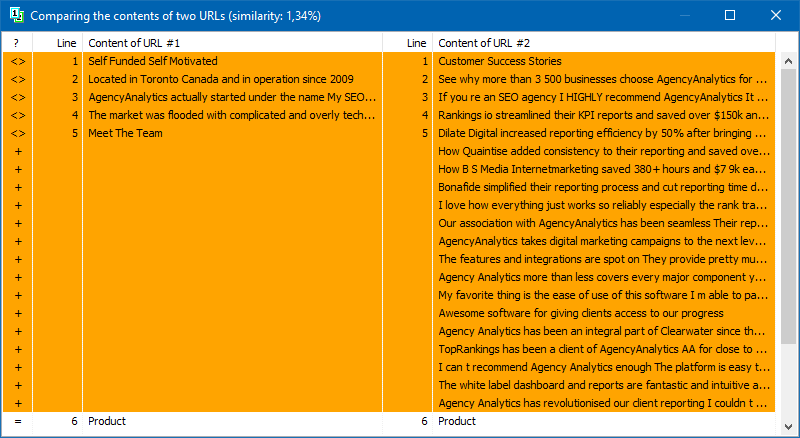
후속 분석을위한 페이지 목록은 클립 보드에서 붙여 넣기, 텍스트 파일에서로드 또는 컴퓨터 디스크의 Sitemap.xml에서 가져 오기 등 여러 가지 방법으로 추가 할 수 있습니다.
프로그램의 다중 스레드 작업으로 인해 수백 개 이상의 URL을 확인하는 데 몇 분 밖에 걸리지 않으며 수동 모드에서는 온라인 서비스를 통해 하루 이상 걸릴 수 있습니다.
따라서 이동식 미디어에서도 실행할 수있는 URL 그룹의 콘텐츠 고유성을 빠르게 확인할 수있는 간단한 도구를 얻을 수 있습니다.
BatchUniqueChecker 무료이며 아카이브에서 4MB 만 차지하며 설치가 필요하지 않습니다.
시작하는 데 필요한 것은 배포 키트를 다운로드하고 확인을 위해 관심있는 URL 목록을 추가하는 것입니다. 무료 기술 감사 프로그램을 통해 얻을 수 있습니다. SiteAnalyzer.



















