





















 3,275
3,275みなさん、こんにちは!営業を再開しました!
非常に長い期間を経て、ついにSiteAnalyzerの新しいリリースを準備しました。これは、皆様の期待に応え、SEOプロモーションに欠かせないアシスタントになることを願っています。
新しいバージョンのSiteAnalyzerでは、データスクレイピング(サイトからのデータの抽出)、コンテンツの一意性の確認、Google PageSpeedによるページの読み込み速度の確認など、ユーザーから最も要望の多かった機能をいくつか実装しました。同時に、多くのバグが修正され、ロゴのスタイルが変更されました。すべてについてもっと詳しく話しましょう。

主な変更点
1. XPath、CSS、XQuery、RegExを使用してデータをスクレイピングします。
Webスクレイピングは、特定のルールに従って、サイト上の関心のあるページからデータを抽出する自動化されたプロセスです。
主なWebスクレイピング方法は、XPath、CSSセレクター、XQuery、RegExp、およびHTMLテンプレートを使用した解析方法です。
- XPathは、XML / XHTMLドキュメント要素用の特別なクエリ言語です。要素にアクセスするために、XPathはページ上の目的の要素へのパスを記述することによってDOMナビゲーションを使用します。その助けを借りて、ドキュメント内の序数で要素の値を取得し、そのテキストコンテンツまたは内部コードを抽出し、ページ上の特定の要素の存在を確認できます。
- CSSセレクターは、その部分(属性)の要素を見つけるために使用されます。 CSSは構文的にXPathに似ていますが、CSSロケーターの方が高速で、より説明的で簡潔な場合があります。 CSSの欠点は、一方向、つまりドキュメントの奥深くでしか機能しないことです。一方、XPathは両方の方法で機能します(たとえば、子で親要素を検索できます)。
- XQueryはXPathに基づいています。 XQueryはXMLを模倣しているため、XSLTでは不可能な方法でネストされた式を作成できます。
- RegExpは、必要な条件(正規表現)に一致する一連のテキスト文字列から値を抽出するための正式な検索言語です。
- HTMLテンプレートは、HTMLドキュメントからデータを抽出するための言語であり、目的のフラグメントの検索テンプレートを記述するためのHTMLマークアップと、データを抽出および変換するための関数と操作を組み合わせたものです。
通常、スクレーピングは、手動で処理するのが難しいタスクを解決するために使用されます。これは、製品の説明を抽出して新しいオンラインストアを作成したり、マーケティングリサーチをスクレイピングして価格を監視したり、広告を監視したりする場合があります。

SiteAnalyzerでは、スクレイピングは抽出ルールが構成されている[データ抽出]タブで構成されます。ルールは保存でき、必要に応じて編集できます。
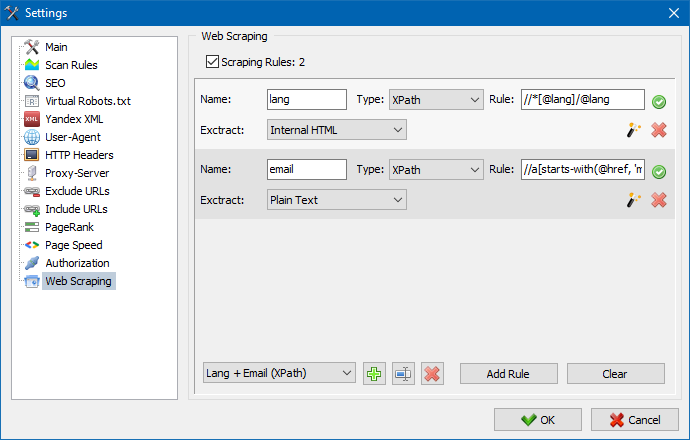
ルールテストモジュールもあります。組み込みのルールデバッガーを使用すると、サイト上の任意のページのHTMLコンテンツをすばやく簡単に取得してクエリの動作をテストし、デバッグされたルールを使用してSiteAnalyzerでデータを解析できます。

データの抽出が完了すると、収集されたすべての情報をExcelにエクスポートできます。
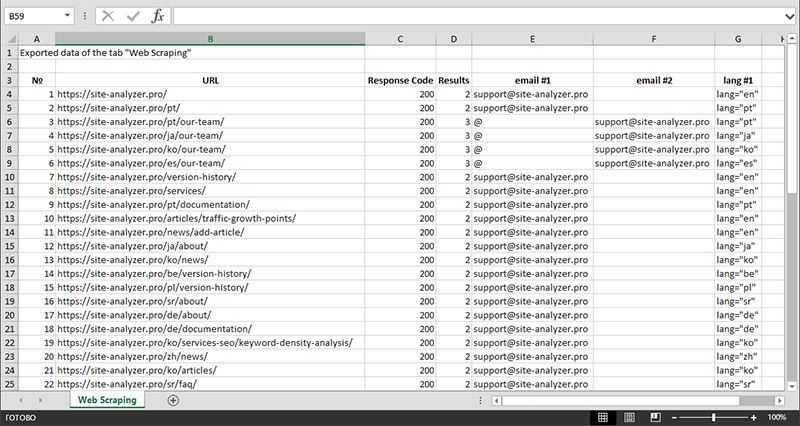
モジュールの操作の詳細と、最も一般的なルールと正規表現のリストについては
2. サイト内のコンテンツの一意性を確認します。
このツールを使用すると、重複するページを検索し、サイト内のテキストの一意性を確認できます。つまり、これはURLのグループの一意性をバッチチェックするものです。
これは、次の場合に役立ちます。
- 完全に重複するページを検索します(たとえば、パラメーターがあり、同じページであるが、CNCビューにあるページ)。
- 部分的なコンテンツの一致を検索するには(たとえば、料理ブログの2つのボルシチレシピは互いに96%類似しており、トラフィックの共食いの可能性を取り除くために記事の1つを削除する必要があることを示唆しています)。
- 記事サイトで、10年前にすでに書いたトピックに関する記事を誤って書いたとき。この場合、私たちのツールはそのような記事の重複も検出します。
コンテンツの一意性をチェックするためのツールの原理は単純です。プログラムはWebサイトのURLのリストからコンテンツをダウンロードし、ページのテキストコンテンツ(HEADブロックなしおよびHTMLタグなし)を受信して、それぞれと比較します。その他は、シングルアルゴリズムを使用します。

したがって、帯状疱疹を使用して、ページの一意性を判断し、0%の一意性を持つページの完全な複製と、テキストコンテンツのさまざまな程度の一意性を持つ部分的な複製の両方を計算できます。プログラムは、シングルの長さが5で動作します。
この記事で、モジュールがどのように機能するかについて詳しく知ることができます。: >>
3. GooglePageSpeedによるページの読み込み速度の確認。
Google検索の巨人のPageSpeedInsightsツールを使用すると、特定のページ要素の読み込み速度を確認できます。また、デスクトップバージョンとモバイルバージョンのブラウザの対象URLの全体的な読み込み速度スコアも表示されます。

Googleのツールはすべての人に適していますが、1つの大きな欠点があります。グループURLチェックを作成できないため、サイトの多くのページをチェックするときに不便になります。100以上のURLのダウンロード速度を手動でチェックすることに同意してください。 1ページは雑用であり、多くの時間がかかる場合があります。
そのため、Google PageSpeed Insightsツールの特別なAPIを使用して、ページの読み込み速度のグループチェックを無料で作成できるモジュールを作成しました。

主な分析パラメータ:
- FCP (First Contentful Paint) – 最初のコンテンツを表示する時間。
- SI (Speed Index) – コンテンツがページに表示される速さの指標。
- LCP (Largest Contentful Paint) – ページ上の最大の要素の表示時間。
- TTI (Time to Interactive) – ページがユーザーとの対話の準備が完全に整うまでの時間。
- TBT (Total Blocking Time) – コンテンツの最初のレンダリングからユーザーインタラクションの準備ができるまでの時間。
- CLS (Cumulative Layout Shift) – 累積レイアウトシフト。ページの視覚的な安定性を測定するのに役立ちます。
SiteAnalyzerのマルチスレッド作業により、数百以上のURLのチェックにかかる時間はわずか数分で、ブラウザを使用した手動モードでは1日以上かかる場合があります。
同時に、URL自体の分析は数回クリックするだけで実行され、その後、Excelの便利な形式のチェックの主な特徴を含むレポートをダウンロードできます。
始めるために必要なのは、APIキーを取得することだけです。
これを行う方法は、この記事で説明されています。 >>
4. プロジェクトをフォルダごとにグループ化する機能が追加されました。
プロジェクトのリストをより便利にナビゲートするために、フォルダーごとにサイトをグループ化する機能が追加されました。

さらに、プロジェクトのリストを名前でフィルタリングすることが可能になりました。
5. プログラム設定のインターフェースが更新されました。
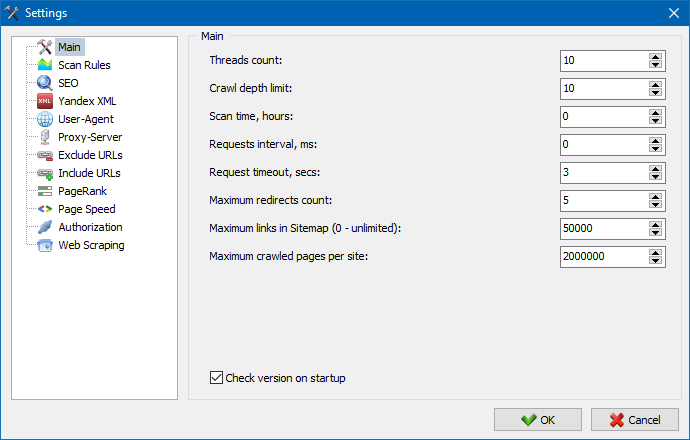
プログラムの機能の拡張に伴い、タブを使用することが「タイト」になったため、設定ウィンドウをより理解しやすく機能的なインターフェイスに再フォーマットしました。
注記:
- URL例外の誤ったアカウンティングを修正しました
- サイトのクロール深度の誤ったアカウンティングを修正しました
- ファイルからインポートされたURLのリダイレクトの表示を復元
- タブ内の列の順序を再配置して記憶する機能を復元しました
- 非正規ページのアカウンティングを復元し、空のメタタグの問題を解決しました
- [情報]タブのリンクアンカーの表示を復元しました
- クリップボードからの多数のURLのインポートの高速化
- タイトルと説明の正しい解析が常に正しいとは限らない問題を修正
- 画像内のaltとtitleの表示を復元
- プロジェクトのスキャン中に[外部リンク]タブに切り替えるとフリーズする問題が修正されました
- プロジェクトを切り替えて[サイトクロール統計]タブのノードを更新するときに発生したエラーを修正しました
- パラメータ付きのURLのネストレベルの誤った定義を修正しました
- メインテーブルのHTMLハッシュフィールドによるデータの並べ替えを修正しました
- キリル文字ドメインを使用したプログラムの最適化された作業
- 更新されたプログラム設定インターフェイス
- 更新されたロゴデザイン


Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
以前のバージョンの概要:



















