





















 1,205
1,205नमस्ते! हम व्यवसाय में वापस आ गए हैं!
बहुत लंबी अवधि के बाद, हमने आखिरकार साइट एनालाइज़र की एक नई रिलीज़ तैयार की है, जो हमें उम्मीद है, आपकी अपेक्षाओं को पूरा करेगी और एसईओ प्रचार में एक अनिवार्य सहायक बन जाएगी।
SiteAnalyzer के नए संस्करण में, हमने उपयोगकर्ताओं द्वारा सबसे अधिक अनुरोधित सुविधाओं में से कुछ को लागू किया है, जैसे डेटा स्क्रैपिंग (साइट से डेटा निकालना), सामग्री की विशिष्टता की जाँच करना, और Google पेजस्पीड द्वारा पेज लोडिंग गति की जाँच करना। वहीं, कई बग्स को बंद कर दिया गया और लोगो को रेस्ट दिया गया। आइए हर चीज के बारे में अधिक विस्तार से बात करें।

बड़े बदलाव
1. XPath, CSS, XQuery, RegEx के साथ डेटा स्क्रैपिंग।
वेब स्क्रैपिंग कुछ नियमों के अनुसार वेबसाइट पर रुचि के पृष्ठों से डेटा निकालने की एक स्वचालित प्रक्रिया है।
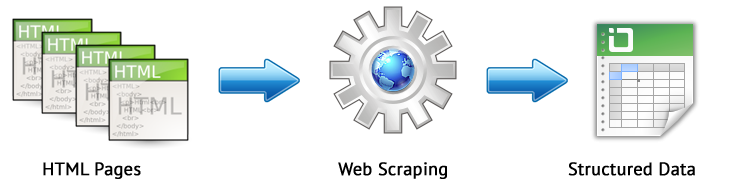
वेब स्क्रैपिंग की मुख्य विधियाँ XPath, CSS चयनकर्ताओं, XQuery, RegExp और HTML टेम्प्लेट का उपयोग करके डेटा पार्सिंग विधियाँ हैं।
- XPath XML / XHTML दस्तावेज़ तत्वों के लिए एक विशेष क्वेरी भाषा है। तत्वों तक पहुँचने के लिए, XPath पृष्ठ पर वांछित तत्व के पथ का वर्णन करके DOM नेविगेशन का उपयोग करता है। इसके साथ, आप दस्तावेज़ में उसके सीरियल नंबर द्वारा किसी तत्व का मान प्राप्त कर सकते हैं, उसकी टेक्स्ट सामग्री या आंतरिक कोड निकाल सकते हैं, पृष्ठ पर किसी विशिष्ट तत्व की उपस्थिति की जांच कर सकते हैं।
- CSS चयनकर्ताओं का उपयोग किसी तत्व को उसके भाग (विशेषता) द्वारा खोजने के लिए किया जाता है। CSS वाक्यात्मक रूप से XPath के समान है, लेकिन कुछ मामलों में CSS लोकेटर तेज़ और अधिक वर्णनात्मक और संक्षिप्त हैं। CSS का नुकसान यह है कि यह केवल एक दिशा में काम करता है - दस्तावेज़ में गहराई से। XPath दोनों तरीकों से काम करता है (उदाहरण के लिए, आप किसी बच्चे द्वारा मूल तत्व की खोज कर सकते हैं)।
- XQuery XPath भाषा पर आधारित है। XQuery XML की नकल करता है, जिससे आप इस तरह से नेस्टेड एक्सप्रेशन बना सकते हैं जो XSLT के साथ संभव नहीं है।
- RegExp आवश्यक शर्तों (नियमित अभिव्यक्ति) से मेल खाने वाले टेक्स्ट स्ट्रिंग्स के एक सेट से मान निकालने के लिए एक औपचारिक खोज भाषा है।
- HTML टेम्प्लेट HTML दस्तावेज़ों से डेटा निकालने के लिए एक भाषा है, जो वांछित टुकड़े के लिए एक खोज टेम्पलेट का वर्णन करने के लिए HTML मार्कअप का एक संयोजन है, साथ ही डेटा निकालने और बदलने के लिए कार्य और संचालन।
स्क्रैपिंग आमतौर पर उन कार्यों को हल करता है जिन्हें मैन्युअल रूप से संभालना मुश्किल होता है। यह एक नया ऑनलाइन स्टोर बनाने के लिए उत्पाद विवरण निकालने, कीमतों की निगरानी के लिए विपणन अनुसंधान में स्क्रैपिंग या विज्ञापनों की निगरानी करने के लिए हो सकता है।

SiteAnalyzer में, "डेटा एक्सट्रैक्शन" टैब स्क्रैपिंग सेट करने के लिए ज़िम्मेदार है, जिसमें निष्कर्षण नियम कॉन्फ़िगर किए गए हैं। नियमों को सहेजा जा सकता है और, यदि आवश्यक हो, संपादित किया जा सकता है।
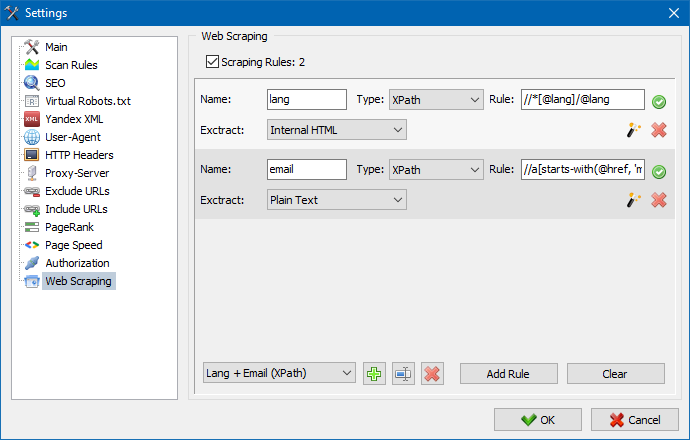
एक नियम परीक्षण मॉड्यूल भी है। अंतर्निहित नियम डीबगर का उपयोग करके, आप साइट पर किसी भी पृष्ठ की HTML सामग्री को जल्दी और आसानी से प्राप्त कर सकते हैं और अनुरोधों के संचालन का परीक्षण कर सकते हैं, और फिर साइट एनालाइज़र में डेटा पार्स करने के लिए डीबग किए गए नियमों का उपयोग कर सकते हैं।

डेटा निष्कर्षण पूरा होने के बाद, सभी एकत्रित जानकारी एक्सेल को निर्यात की जा सकती है।
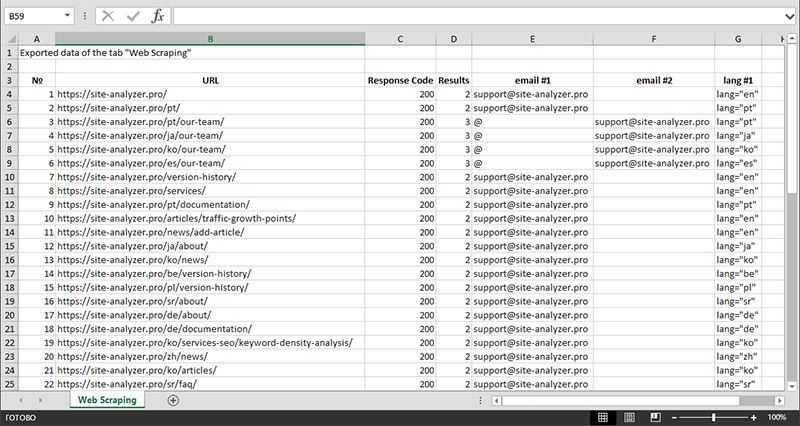
आप मॉड्यूल के संचालन के बारे में अधिक जान सकते हैं और लेख में सबसे सामान्य नियमों और नियमित अभिव्यक्तियों की सूची से परिचित हो सकते हैं
2. साइट के भीतर सामग्री की विशिष्टता की जाँच करना।
यह टूल आपको डुप्लीकेट पृष्ठों की खोज करने और साइट के भीतर टेक्स्ट की विशिष्टता की जांच करने की अनुमति देता है। दूसरे शब्दों में, यह आपस में विशिष्टता के लिए URL के समूह का बैच चेक है।
यह मामलों में उपयोगी हो सकता है:
- पूर्ण पृष्ठ डुप्लीकेट खोजने के लिए (उदाहरण के लिए, पैरामीटर वाला पृष्ठ और एक ही पृष्ठ, लेकिन सीएनसी के रूप में)।
- आंशिक सामग्री मिलान खोजने के लिए (उदाहरण के लिए, एक खाद्य ब्लॉग पर दो बोर्स्च व्यंजन जो एक दूसरे के समान 96% हैं, जो सुझाव देता है कि संभावित ट्रैफ़िक नरभक्षण से छुटकारा पाने के लिए लेखों में से एक को हटा दिया जाना चाहिए)।
- जब आपने किसी लेख साइट पर गलती से किसी ऐसे विषय पर लेख लिखा था जिसे आपने 10 साल पहले ही लिखा था। इस मामले में, हमारा टूल ऐसे लेख के डुप्लिकेट का भी पता लगाएगा।
सामग्री विशिष्टता जाँच उपकरण के संचालन का सिद्धांत सरल है: साइट URL की सूची के अनुसार, कार्यक्रम उनकी सामग्री को डाउनलोड करता है, पृष्ठ की पाठ्य सामग्री प्राप्त करता है (बिना HEAD ब्लॉक और HTML टैग के), और फिर उनकी तुलना करता है एक दूसरे को शिंगल एल्गोरिथम का उपयोग करते हुए।

इस प्रकार, दाद की मदद से, हम पृष्ठों की विशिष्टता का निर्धारण करते हैं और 0% विशिष्टता के साथ पूर्ण पृष्ठ डुप्लिकेट और टेक्स्ट सामग्री विशिष्टता की विभिन्न डिग्री के साथ आंशिक डुप्लिकेट दोनों की गणना कर सकते हैं। कार्यक्रम 5 की लंबाई के साथ काम करता है।
आप इस लेख में मॉड्यूल के संचालन के बारे में अधिक जान सकते हैं।: >>
3. Google PageSpeed पर पृष्ठ लोड करने की गति की जाँच करना।
सर्च दिग्गज Google का पेजस्पीड इनसाइट्स टूल आपको कुछ पेज तत्वों की लोडिंग गति की जांच करने की अनुमति देता है, और ब्राउज़र के डेस्कटॉप और मोबाइल संस्करणों के लिए रुचि के URL के समग्र लोड स्पीड स्कोर को भी दिखाता है।

Google टूल सभी के लिए अच्छा है, हालांकि, इसकी एक महत्वपूर्ण खामी है - यह आपको समूह URL चेक बनाने की अनुमति नहीं देता है, जो आपकी साइट के कई पृष्ठों की जाँच करते समय असुविधा पैदा करता है: आपको यह स्वीकार करना होगा कि मैन्युअल रूप से 100 के लिए डाउनलोड गति की जाँच करना या एक पृष्ठ पर अधिक URL एक घर का काम है और इसमें बहुत समय लग सकता है।
इसलिए, हमने एक मॉड्यूल बनाया है जो आपको Google पेजस्पीड इनसाइट्स टूल में एक विशेष एपीआई के माध्यम से पेज लोडिंग स्पीड की मुफ्त ग्रुप चेक बनाने की अनुमति देता है।

मुख्य विश्लेषण पैरामीटर:
- FCP (First Contentful Paint) – पहली सामग्री का प्रदर्शन समय।
- SI (Speed Index) – एक पृष्ठ पर सामग्री कितनी जल्दी प्रस्तुत की जाती है इसका एक उपाय।
- LCP (Largest Contentful Paint) – सबसे बड़े पृष्ठ तत्व का प्रदर्शन समय।
- TTI (Time to Interactive) – वह समय जिसके दौरान पृष्ठ उपयोगकर्ता सहभागिता के लिए पूरी तरह से तैयार हो जाता है।
- TBT (Total Blocking Time) – सामग्री के पहले प्रतिपादन से लेकर उपयोगकर्ता सहभागिता के लिए उसकी तैयारी तक का समय।
- CLS (Cumulative Layout Shift) – संचयी लेआउट शिफ्ट। एक पृष्ठ की दृश्य स्थिरता को मापने के लिए कार्य करता है।
SiteAnalyzer के बहु-थ्रेडेड वर्कफ़्लो के लिए धन्यवाद, सैकड़ों या अधिक URL की जाँच में केवल कुछ मिनट लग सकते हैं, जिसमें ब्राउज़र के माध्यम से मैन्युअल रूप से एक दिन या उससे अधिक समय लग सकता है।
उसी समय, URL विश्लेषण स्वयं कुछ ही क्लिक में होता है, जिसके बाद एक रिपोर्ट उपलब्ध होती है जिसमें एक्सेल में सुविधाजनक रूप में चेक की मुख्य विशेषताएं शामिल होती हैं।
आरंभ करने के लिए आपको केवल एक API कुंजी प्राप्त करने की आवश्यकता है।
यह कैसे करना है इस लेख में वर्णित है। >>
4. फ़ोल्डरों द्वारा परियोजनाओं को समूहीकृत करने की क्षमता जोड़ी गई।
परियोजनाओं की सूची के माध्यम से अधिक सुविधाजनक नेविगेशन के लिए, साइटों को फ़ोल्डरों में समूहित करने की क्षमता को जोड़ा गया है।

इसके अतिरिक्त, परियोजनाओं की सूची को नाम से फ़िल्टर करना संभव हो गया।
5. प्रोग्राम सेटिंग्स इंटरफ़ेस अपडेट किया गया है।
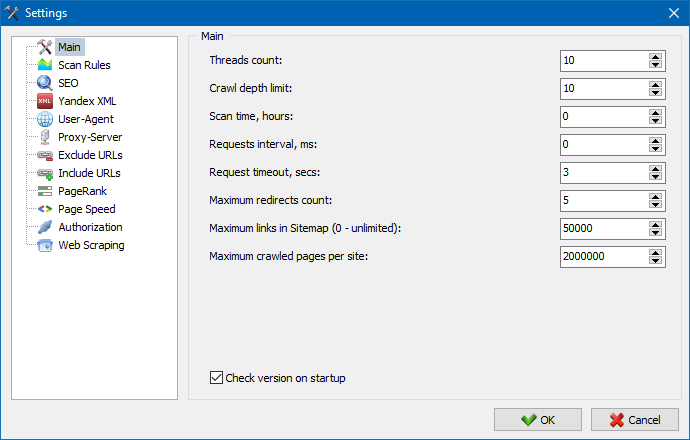
कार्यक्रम की कार्यक्षमता के विस्तार के साथ, हमारे लिए टैब का उपयोग करना "कठिन" हो गया, इसलिए हमने सेटिंग्स विंडो को अधिक समझने योग्य और कार्यात्मक इंटरफ़ेस में पुन: स्वरूपित किया।
टिप्पणियाँ:
- URL अपवादों का निश्चित गलत प्रबंधन
- साइट क्रॉल गहराई का निश्चित गलत खाता
- फ़ाइल से आयात किए गए URL के लिए पुनर्निर्देशों का पुनर्स्थापित प्रदर्शन
- टैब पर स्तंभों के क्रम को पुनर्व्यवस्थित करने और याद रखने की क्षमता को बहाल किया
- गैर-विहित पृष्ठों के लिए लेखांकन बहाल किया, खाली मेटा टैग के साथ समस्या को ठीक किया
- जानकारी टैब पर लिंक एंकरों का पुनर्स्थापित प्रदर्शन
- क्लिपबोर्ड से बड़ी संख्या में URL का त्वरित आयात
- शीर्षक और विवरण की निश्चित रूप से सही पार्सिंग हमेशा सही नहीं होती है
- छवियों के लिए Alt और शीर्षक का पुनर्स्थापित प्रदर्शन
- प्रोजेक्ट स्कैनिंग के दौरान "बाहरी लिंक" टैब पर स्विच करते समय निश्चित हैंग
- प्रोजेक्ट के बीच स्विच करते समय और क्रॉल स्टैटिस्टिक्स टैब के नोड्स को अपडेट करते समय होने वाली बग को ठीक किया
- पैरामीटर वाले URL के लिए गलत नेस्टिंग स्तर का पता लगाना तय किया गया है
- मुख्य तालिका में HTML-हैश फ़ील्ड द्वारा निश्चित डेटा छँटाई
- सिरिलिक डोमेन के साथ कार्यक्रम का अनुकूलित कार्य
- अद्यतन कार्यक्रम सेटिंग्स इंटरफ़ेस
- अद्यतन लोगो डिजाइन


Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
पिछले संस्करणों का अवलोकन:
- नए संस्करण का अवलोकन SiteAnalyzer 2.2
- नए संस्करण का अवलोकन SiteAnalyzer 2.1
- नए संस्करण का अवलोकन SiteAnalyzer 2.0


















