






















 1,866
1,866La cuestión de determinar las páginas duplicadas y la singularidad de los textos dentro del sitio es uno de los más importantes en la lista de trabajos de auditoría técnica. La presencia de páginas duplicadas determina tanto el bienestar general del sitio como la distribución del presupuesto de rastreo del motor de búsqueda, que puede desperdiciarse y, en general, la clasificación del sitio puede ser difícil debido a la gran cantidad de contenido duplicado.

Y si puede encontrar fácilmente una gran cantidad de servicios y programas para verificar la singularidad de textos individuales en Internet, entonces no hay muchos servicios similares para verificar la singularidad de un grupo de URL específicas entre sí, aunque el problema en sí es importante y relevante.
Qué opciones para problemas con contenido no exclusivo puede haber en el sitio?
1. Mismo contenido para diferentes URL.
Por lo general, esta es una página con parámetros y la misma página, pero en forma de SEF (URL legible por humanos).
- Ejemplo:
- https://some-site.com/index.php?page=contacts
- https://some-site.com/contacts/
Este es un problema bastante común cuando, después de configurar el SEF, el programador se olvida de configurar un redireccionamiento 301 de páginas con parámetros a páginas con SEF.
Este problema puede ser resuelto fácilmente por cualquier rastreador web, el cual, habiendo comparado todas las páginas del sitio, encontrará que dos de ellas tienen los mismos códigos hash (MD5), e informará al optimizador, quien tendrá que configurar la tarea, el mismo programador, para instalar redireccionamientos 301. a las páginas del SEF.
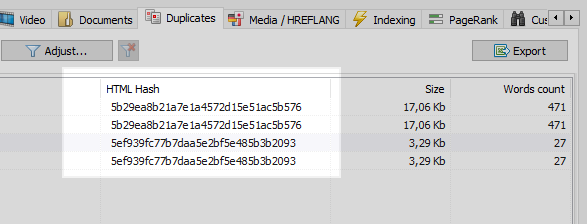
Sin embargo, no todo es tan sencillo.
2. Contenido superpuesto.
Se genera contenido similar cuando tenemos páginas diferentes, pero, de hecho, con contenido igual o similar.
Ejemplo 1
En el sitio web de venta de ventanas de plástico, en la sección de noticias, un redactor hace un año escribió una felicitación el 8 de marzo por 500 caracteres y dio un 15% de descuento en la instalación de ventanas de plástico.
Y este año, el administrador de contenido decidió "hacer trampa", y sin más preámbulos, encontró las noticias publicadas anteriormente con descuentos, las copió y cambió el tamaño del descuento del 15 al 12% + agregó 50 carteles de él mismo con felicitaciones adicionales.
Así, al final tenemos dos textos casi idénticos, un 90% similares, que en sí mismos son duplicados borrosos, uno de los cuales, por un buen motivo, requiere una reescritura urgente.
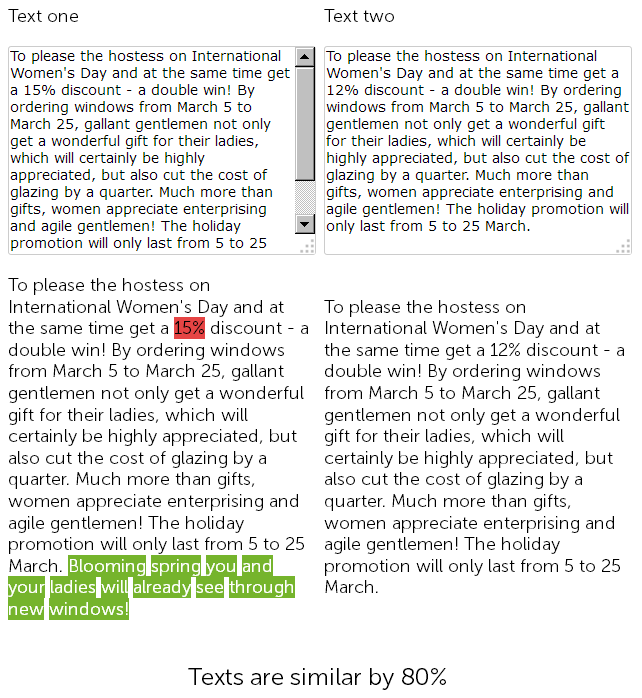
Al mismo tiempo, para los servicios de auditoría técnica, estas dos novedades serán diferentes, ya que el SEF en el sitio ya está configurado y las sumas de comprobación de las páginas no coincidirán, digan lo que digan.
Al final, qué página se clasificará mejor es una gran pregunta ...
Pero son una gran noticia, tienden a quedar obsoletas rápidamente, así que tomemos un ejemplo más interesante.
Ejemplo 2
Tiene una sección de artículos en su sitio, o mantiene una página personal para su hobby / hobby, por ejemplo, es un "blog culinario".
Y, por ejemplo, su blog ya ha acumulado un pedido de artículos durante todo el tiempo, más de 100 o incluso varios cientos. Así que escogiste un tema y escribiste un nuevo artículo, lo publicaste y luego, de alguna manera, descubriste que ya se había escrito un artículo similar hace 3 años. Aunque parecería que antes de escribir el contenido, recorriste todos los títulos, abriste Excel con una lista de temas publicados, pero no tomaste en cuenta que el contenido pasado del artículo "Cómo hacer chocolate caliente en casa" coincide fuertemente con el material recién escrito. Y al revisar estos dos artículos en uno de los servicios online, resulta que son un 78% únicos entre sí, lo que, por supuesto, no es nada bueno, ya que por duplicación parcial hay una canibalización de consultas de búsqueda entre estas páginas, y el buscador. surgen preguntas y dificultades al clasificar tales duplicados.
Por supuesto, después de escribir un artículo, cada redactor publicitario debe verificar su singularidad en uno de los servicios conocidos, y todo SEO está obligado a verificar el contenido nuevo cuando se publica en el sitio en los mismos servicios.
Pero, ¿qué hacer si un sitio web acaba de llegar a usted para promocionarlo y necesita verificar rápidamente todas sus páginas para ver si hay duplicados? O, al comienzo de la apertura de su blog, escribió un montón de artículos del mismo tipo y ahora, muy probablemente, debido a ellos, el sitio comenzó a hundirse. No revise a mano 100.500 páginas en servicios en línea, agregue revisar cada artículo a mano y dedicar mucho tiempo a él.
BatchUniqueChecker
Es por eso que creamos el programa BatchUniqueChecker, diseñado para verificar por lotes un grupo de URL para ver si son únicas entre sí.
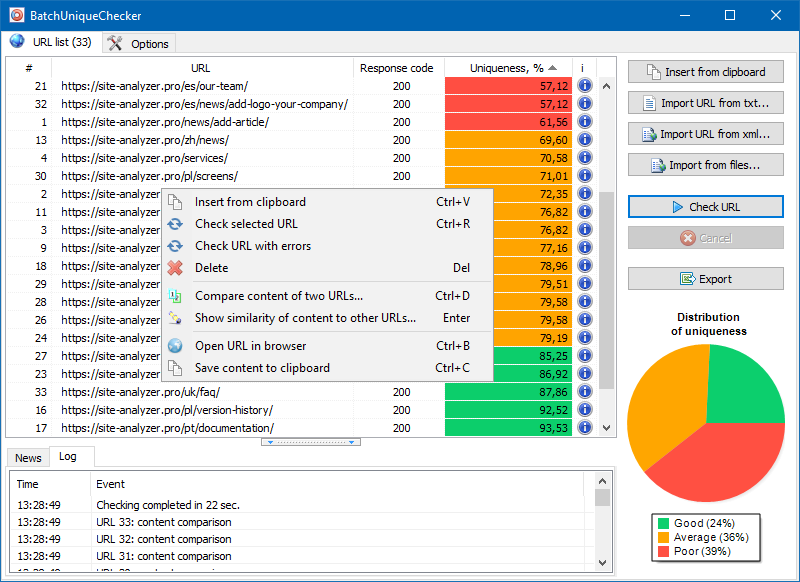
El principio de funcionamiento de BatchUniqueChecker es simple: el programa descarga su contenido usando una lista de URL previamente preparada, recibe PlainText (el contenido de texto de la página sin un bloque HEAD y sin etiquetas HTML) y luego los compara entre sí usando el algoritmo shingle.
Por lo tanto, al usar tejas, determinamos la singularidad de las páginas y podemos calcular tanto los duplicados completos de páginas con 0% de singularidad como los duplicados parciales con diversos grados de singularidad del contenido del texto.
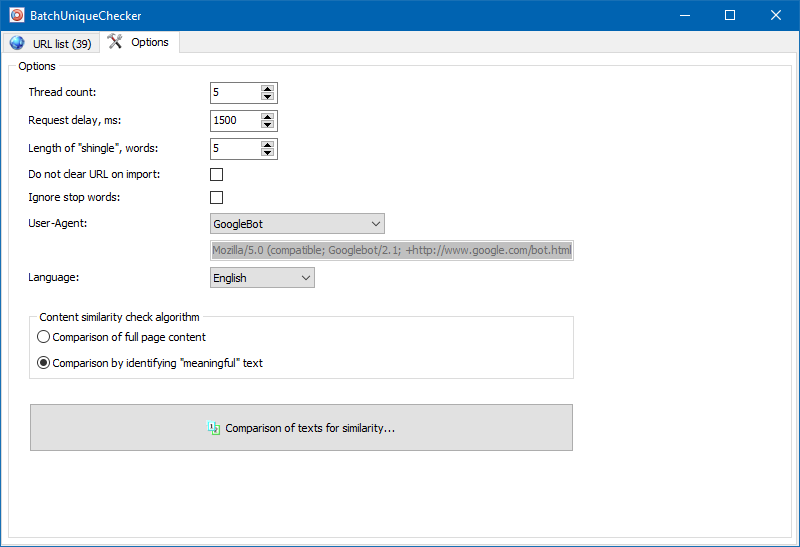
En la configuración del programa, puede establecer manualmente el tamaño de la teja (teja es el número de palabras en el texto, cuya suma de verificación se compara alternativamente con los grupos posteriores). Recomendamos establecer el valor = 4. Para grandes cantidades de texto de 5 en adelante. Para volúmenes relativamente pequeños: 3-4.
Textos significativos
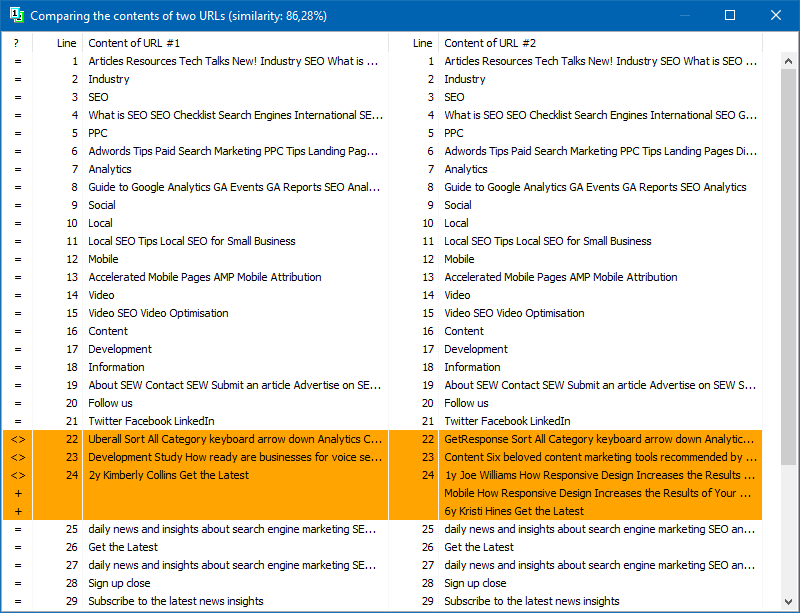
Además de la comparación de contenido de texto completo, el programa incluye un algoritmo para el aislamiento "inteligente" de los llamados textos "significativos".
Es decir, del código HTML de la página obtenemos solo el contenido contenido en las etiquetas H1-H6, P, PRE y LI. Debido a esto, descartamos todo lo que "no es significativo", por ejemplo, el contenido del menú de navegación del sitio, el texto del pie de página o el menú lateral.
Como resultado de tales manipulaciones, solo obtenemos contenido de página "significativo" que, cuando se compara, mostrará resultados de unicidad más precisos con otras páginas.
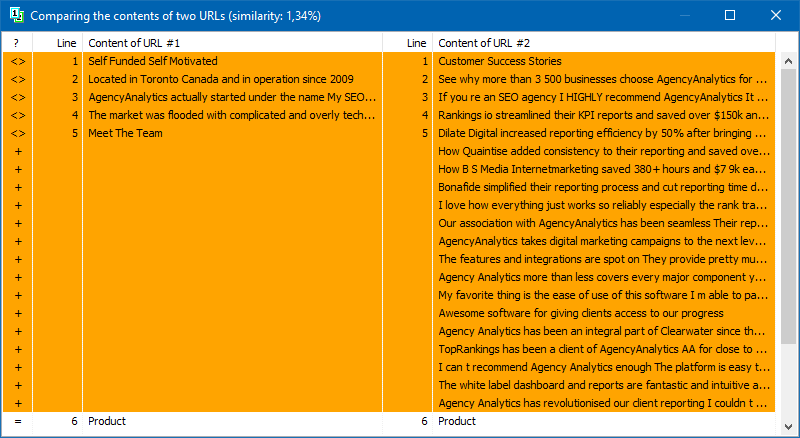
La lista de páginas para su posterior análisis se puede agregar de varias formas: pegar desde el portapapeles, cargar desde un archivo de texto o importar desde Sitemap.xml desde el disco de su computadora.
Debido a la operación multiproceso del programa, la verificación de cientos o más URL puede llevar solo unos minutos, lo que en el modo manual, a través de servicios en línea, podría llevar un día o más.
Por lo tanto, obtiene una herramienta simple para verificar rápidamente la singularidad del contenido de un grupo de URL, que se puede ejecutar incluso desde medios extraíbles.
BatchUniqueChecker es gratuito, solo ocupa 4 MB en el archivo y no requiere instalación.
Todo lo que necesita para comenzar es descargar el kit de distribución y agregar una lista de URL de interés para la verificación, que se puede obtener a través de un programa de auditoría técnica gratuito SiteAnalyzer.
Otros articulos




















