





















 1,564
1,564Всім привіт! Ми знову в справі!
Після досить тривалого періоду ми, нарешті, підготували новий реліз SiteAnalyzer, який, сподіваємося, виправдає ваші очікування і стане незамінним помічником в SEO-просуванні.
У новій версії SiteAnalyzer ми реалізували кілька з найбільш затребуваних користувачами функцій, таких, як: скрейпінг даних (витяг даних з сайту), перевірка унікальності контенту і перевірка швидкості завантаження сторінок по Google PageSpeed. Разом з цим було закрито безліч багів і проведено рестайлінг логотипу. Розповімо про все докладніше.

Основні зміни
1. Скрейпінг даних за допомогою XPath, CSS, XQuery, RegEx.
Веб-скрейпінг - це автоматизований процес вилучення даних з цікавлять сторінок сайту за певними правилами.
Основними способами веб-скрейпінга є методи аналізу інформації використовуючи XPath, CSS-селектори, XQuery, RegExp і HTML templates.
- XPath є спеціальна мова запитів до елементів документа формату XML / XHTML. Для доступу до елементів XPath використовує навігацію по DOM шляхом опису шляху до потрібного елемента на сторінці. З його допомогою можна отримати значення елемента по його порядковому номеру в документі, витягти його текстовий вміст або внутрішній код, перевірити наявність певного елемента на сторінці.
- CSS-селектори використовуються для пошуку елемента його частини (атрибут). CSS синтаксично схожий на XPath, при цьому в деяких випадках CSS-локатори працюють швидше і описуються більш наочно і коротко. Мінусом CSS є те, що він працює лише в одному напрямку - вглиб документа. XPath же працює в обидві сторони (наприклад, можна шукати батьківський елемент по дочірньому).
- XQuery має в якості основи мову XPath. XQuery імітує XML, що дозволяє створювати вкладені вирази в такий спосіб, який неможливий в XSLT.
- RegExp - формальна мова пошуку для вилучення значень з безлічі текстових рядків, відповідних необхідним умовам (регулярному виразу).
- HTML templates - мова вилучення даних з HTML документів, який являє собою комбінацію HTML-розмітки для опису шаблону пошуку потрібного фрагмента плюс функції і операції для вилучення і перетворення даних.
Зазвичай за допомогою скрейпінга вирішуються завдання, з якими складно впоратися вручну. Це може бути витяг описів товарів для створення нового інтернет-магазину, скрейпінг в маркетингових дослідженнях для моніторингу цін, або для моніторингу оголошень.

У SiteAnalyzer за настройку скрейпінга відповідає вкладка "Витяг даних", в якій настроюються правила вилучення. Правила можна зберігати і, при необхідності, редагувати.
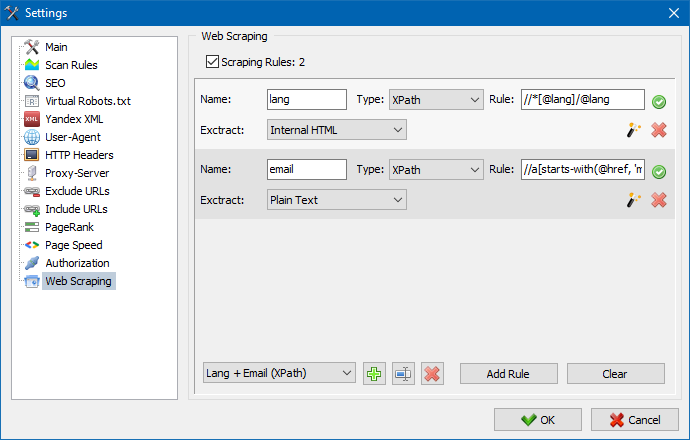
Також присутній модуль тестування правил. За допомогою вбудованого відладчика правил можна швидко і просто отримати HTML-вміст будь-якої сторінки сайту і тестувати роботу запитів, після чого використовувати налагоджені правила для парсинга даних в SiteAnalyzer.

Після закінчення вилучення даних всю зібрану інформацію можна експортувати в Excel.
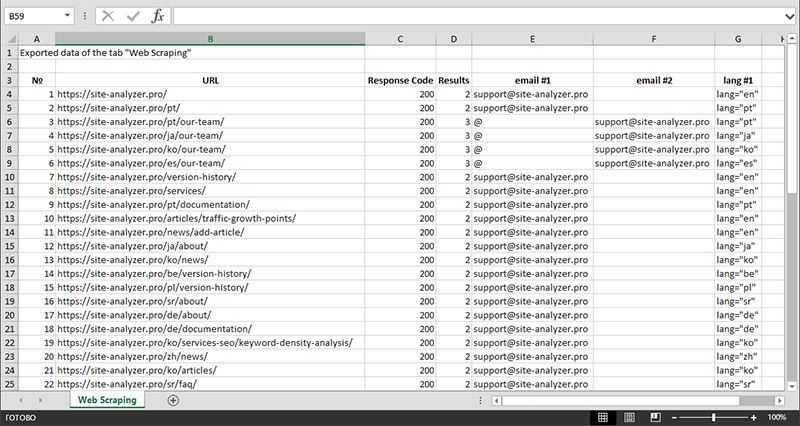
Більш детально вивчити роботу модуля і ознайомитися зі списком найбільш часто зустрічаються правил і регулярних виразів можна в статті
2. Перевірка унікальності контенту всередині сайту.
Даний інструмент дозволяє провести пошук дублікатів сторінок і перевірити унікальність текстів всередині сайту. Іншими словами це пакетна перевірка групи URL на унікальність між собою.
Це може бути корисно у випадках:
- Для пошуку повних дублів сторінок (наприклад, сторінка з параметрами і та ж сама сторінка, але у вигляді ЧПУ).
- Для пошуку часткових збігів контенту (наприклад, два рецепта борщу в кулінарному блозі, які схожі між собою на 96%, що наводить на думку, що одну зі статей краще видалити, щоб позбутися від можливої канібалізації трафіку).
- Коли на статейному сайті ви випадково написали статтю по темі, яку вже писали раніше 10 років тому. У цьому випадку наш інструмент також виявить дублікат такої статті.
Принцип роботи інструменту перевірки унікальності контенту простий: за списком URL сайту програма завантажує їх вміст, отримує текстове вміст сторінки (без блоку HEAD і без HTML-тегів), а потім за допомогою алгоритму шинглів порівнює їх один з одним.

Таким чином, за допомогою шинглів ми визначаємо унікальність сторінок і можемо обчислити як повні дублі сторінок з 0% унікальністю, так і часткові дублі з різними ступенями унікальності текстового вмісту. Програма працює з довжиною шингли дорівнює 5.
Більш детально вивчити роботу модуля можна в даній статті: >>
3. Перевірка швидкості завантаження сторінок по Google PageSpeed.
Інструмент PageSpeed Insights пошукового гіганта Google дозволяє перевіряти швидкість завантаження тих чи інших елементів сторінок, а також показує загальний бал швидкості завантаження цікавлять URL для деськтопной і мобільної версії браузера.

Інструмент Google всім хороший, проте, має один істотний мінус - він не дозволяє створювати групові перевірки URL, що створює незручності при перевірці безлічі сторінок вашого сайту: погодьтеся, що вручну перевіряти швидкість завантаження для 100 і більше URL по одній сторінці клопітно і може зайняти чимало часу.
Тому, нами був створений модуль, що дозволяє безкоштовно створювати групові перевірки швидкості завантаження сторінок через спеціальний API в інструменті Google PageSpeed Insights.

Основні аналізовані параметри:
- FCP (First Contentful Paint) – час відображення першого контенту.
- SI (Speed Index) – показник того, як швидко відображається контент на сторінці.
- LCP (Largest Contentful Paint) – час відображення найбільшого за розміром елемента сторінки.
- TTI (Time to Interactive) – час, протягом якого сторінка стає повністю готова до взаємодії з користувачем.
- TBT (Total Blocking Time) – час від першої відтворення контенту до його готовності до взаємодії з користувачем.
- CLS (Cumulative Layout Shift) – накопичувальний зрушення макета. Служить для вимірювання візуальної стабільності сторінки.
Завдяки многопоточной роботі програми SiteAnalyzer, перевірка сотні і більше URL може зайняти всього декілька хвилин, на що в ручному режимі, через браузер, міг би піти день або більше.
При цьому, сам аналіз URL відбувається всього в пару кліків, після чого доступна вивантаження звіту, що включає основні характеристики перевірок в зручному вигляді в Excel.
Все що вам потрібно для початку роботи - отримати ключ API.
Як це зробити - описано в даній статті >>
4. Додана можливість угруповання проектів по папках.
Для більш зручної навігації по списку проектів була додана можливість угруповання сайтів по папках.

Додатково з'явилася можливість фільтрації списку проектів за назвою.
5. Оновлений інтерфейс налаштувань програми.
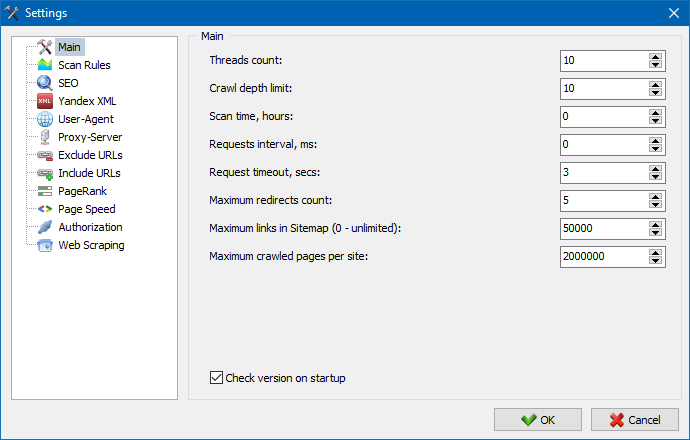
З розширенням функціоналу програми нам стало "тісно" використовувати таби, тому ми переформатували вікно налаштувань в більш зрозумілий і функціональний інтерфейс.
Примітки:
- виправлений некоректний облік винятків URL
- виправлений некоректний облік глибини сканування сайту
- відновлено відображення редиректів для URL, імпортованих з файлу
- відновлена можливість перестановки і запамятовування порядку стовпців на вкладках
- відновлений облік неканонічних сторінок, вирішена проблема з порожніми мета-тегами
- відновлено відображення анкоров посилань на вкладці Інфо
- прискорений імпорт великої кількості URL з буфера обміну
- виправлений не завжди коректний парсинг title і description
- відновлено відображення alt і title у зображень
- виправлено зависання при переході на вкладку "Зовнішні посилання" під час сканування проекту
- виправлена помилка, що виникає при перемиканні між проектами і оновленні вузлів вкладки "Статистика обходу сайту"
- виправлено некоректне визначення рівня вкладеності для URL з параметрами
- виправлена сортування даних по полю HTML-hash в головній таблиці
- оптимізована робота програми з кириличними доменами
- оновлений інтерфейс налаштувань програми
- оновлений дизайн логотипу

Огляд попередніх версій:
- Огляд нової версії SiteAnalyzer 2.2
- Огляд нової версії SiteAnalyzer 2.1
- Огляд нової версії SiteAnalyzer 2.0



















