





















 1,970
1,970У версії 1.9 додана можливість сканування довільних списків URL, а також XML-карт сайту Sitemap.xml (в тому числі і індексних) для їх подальшого аналізу на предмет пошуку "битих" посилань, некоректних мета-тегів, порожніх заголовків і тому подібних помилок.
Основні зміни
Додана можливість сканування списку довільних URL, використовуючи буфер обміну або завантаження URL з файлу на диску.
- Буфер обміну. Самий простий і швидкий варіант сканування довільних URL - через буфера обміну. Маючи в буфері обміну список URL для аналізу, ви вибираєте в меню програми пункт "Імпорт URL" -> "З буфера обміну", після чого програма автоматично копіює вміст буфера обміну в окрему форму, в якій ви можете додати нові або редагувати поточні URL. Після натискання на кнопку ОК список URL додається в програму, після чого починається їх сканування, аналогічно тому, як якщо б ви сканували звичайний сайт.
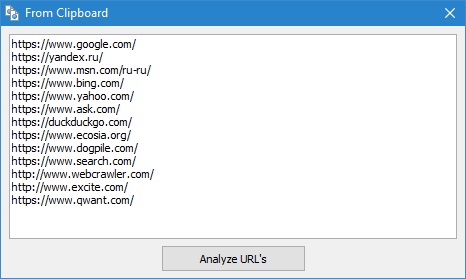
- З файлу на диску. Цей варіант зручний, якщо список URL для перевірки знаходиться на жорсткому диску в текстовому файлі або в файлі Sitemap (*.txt і *.xml формати). У цьому випадку імпорт URL цього типу файлів аналогічний імпорту з буфера обміну за тим лише винятком, що після відкриття файлів відбувається їх парсинг на предмет пошуку в них URL, а потім повторюється процедура додавання знайдених URL у форму і подальше їх сканування програмою SiteAnalyzer.
- Примітка: при імпорті Sitemap.xml з жорсткого диска відбувається його аналіз на предмет, чи є він індексним, і якщо це так, то у формі відображається список внутрішніх XML файлів, вміст яких буде завантажено і додано в програму. При імпорті текстових файлів, що містять списки URL, відбувається просте додавання їх вмісту у форму для відправки URL на подальше сканування.
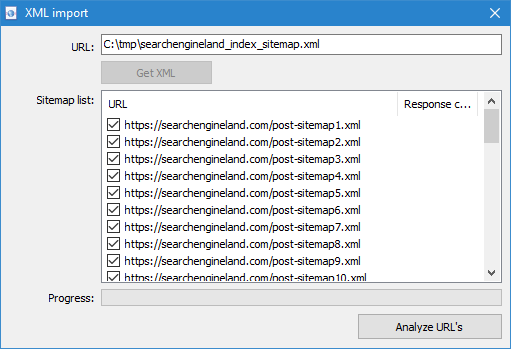
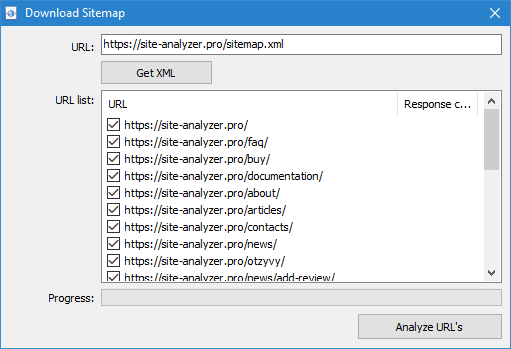
Додана можливість сканування файлів Sitemap.xml (класичний Sitemap або індексний зі списком файлів XML).
- Сканування Sitemap.xml безпосередньо з сайту доступні через пункт меню "Імпорт URL" -> "Завантажити Sitemap". У вікні необхідно вказати URL для скачування і парсинга вмісту Sitemap.xml. Після натискання на кнопку "Імпортувати" програма проведе аналіз вмісту файлу на предмет того, чи є даний сайтмап індексним або це звичайний Sitemap.xml зі списком URL сайту.
- Класичний Sitemap.xml. Якщо це виявився класичний Sitemap.xml, то далі програма спарсит всі його URL та після натискання кнопки ОК додасть їх у програму і почне їх сканування.
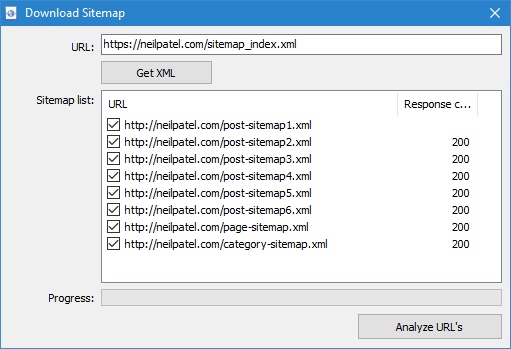
- Індексний Sitemap.xml. У разі, якщо Sitemap.xml виявиться індексним файлом, то в цьому ж вікні програма відобразить списк його внутрішніх *.xml файлів, а також код відповіді кожного з них. З допомогою чекбоксов можна вибрати ті файли, вміст яких планується просканувати. Після натискання кнопки ОК вміст XML-файлів буде також додано в програму і почнеться їх сканування.
Примітки:
- При імпорті URL відбувається автоматична валідація посилань на коректність. Якщо рядок не є URL, то вона не буде додана в чергу сканування.
- Перевіряються лише ті URL, які були відправлені на перевірку, і тільки вони. Таким чином, при парсингу URL сканер не переходить за посиланнями і не додає їх в список сканування, як при скануванні повноцінних сайтів. Скільки URL було імпортовано на вході - стільки і буде проскановано на виході. Ця особливість стосується усіх типів сканування довільних URL.
- При скануванні довільних URL сам "проект" не зберігається в програмі і дані за нього не додається в базу. Також не доступні розділи "Структура сайту" і "Дашборд".
Інші зміни
- Додана можливість виділення і копіювання в буфер обміну значень клітинок за Ctrl+A.
- Прискорена операція видалення проектів (для повного видалення проектів необхідно робити стиснення бази через меню програми).
- Виправлена проблема з не завжди коректним підрахунком порожніх тегів H1.
- Виправлена проблема з не завжди коректним парсингом атрибута «title» у зображень.
- Виправлено зависання програми при переміщенні по записах під час сканування.
Ми не зупиняємося на досягнутому і вже готуємо для вас нову фішку, яку плануємо випустити найближчим часом.
Слідкуйте за оновленнями! :-)
Оцініть статтю
5/5
1


















