





















 1,514
1,514Herkese merhaba! İşe geri döndük!
Çok uzun bir aradan sonra, beklentilerinizi karşılayacağını ve SEO tanıtımlarında vazgeçilmez bir yardımcı haline geleceğini umduğumuz SiteAnalyzer'ın yeni sürümünü nihayet hazırladık.
SiteAnalyzer'ın yeni sürümünde, kullanıcılar tarafından en çok istenen işlevlerden bazılarını uyguladık, örneğin: veri kazıma (siteden veri çıkarma), içeriğin benzersizliğini kontrol etme ve Google PageSpeed ile sayfa yükleme hızını kontrol etme. Aynı zamanda birçok hata düzeltildi ve logo yeniden şekillendirildi. Her şey hakkında daha ayrıntılı konuşalım.

Temel değişiklikler
1. XPath, CSS, XQuery, RegEx ile verileri kazıma.
Web kazıma, sitedeki ilgilenilen sayfalardan belirli kurallara göre otomatik olarak veri çıkarma işlemidir.
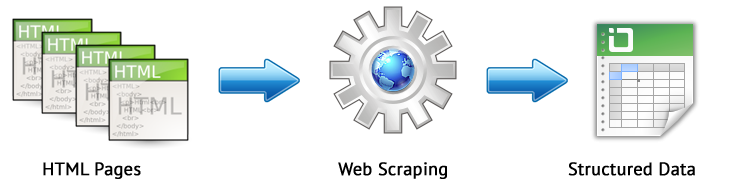
Ana web kazıma yöntemleri, XPath, CSS seçicileri, XQuery, RegExp ve HTML şablonlarını kullanan ayrıştırma yöntemleridir.
- XPath, XML / XHTML belge öğeleri için özel bir sorgu dilidir. Öğelere erişmek için XPath, sayfada istenen öğenin yolunu açıklayarak DOM gezinmesini kullanır. Yardımıyla, bir öğenin değerini belgedeki sıra numarasına göre alabilir, metin içeriğini veya dahili kodunu çıkarabilir, sayfada belirli bir öğenin olup olmadığını kontrol edebilirsiniz.
- CSS seçicileri, parçasının (öznitelik) bir öğesini bulmak için kullanılır. CSS sözdizimsel olarak XPath'a benzer, ancak bazı durumlarda CSS konum belirleyicileri daha hızlıdır ve daha açıklayıcı ve özlüdür. CSS'nin dezavantajı, yalnızca bir yönde çalışmasıdır - belgenin daha derinlerinde. Öte yandan XPath, her iki şekilde de çalışır (örneğin, bir alt öğe tarafından bir üst öğe arayabilirsiniz).
- XQuery, XPath'e dayanmaktadır. XQuery, XSLT'de mümkün olmayan bir şekilde iç içe ifadeler oluşturmanıza olanak tanıyan XML'i taklit eder.
- RegExp, gerekli koşullarla (normal ifade) eşleşen bir dizi metin dizesinden değerleri çıkarmak için resmi bir arama dilidir.
- HTML şablonları, istenen parça için arama şablonunu tanımlayan HTML işaretlemesinin ve ayrıca verileri ayıklamak ve dönüştürmek için işlevler ve işlemlerin bir kombinasyonu olan HTML belgelerinden veri çıkarmak için kullanılan bir dildir.
Tipik olarak, kazıma, elle işlenmesi zor olan görevleri çözmek için kullanılır. Bu, yeni bir çevrimiçi mağaza oluşturmak için ürün açıklamalarını çıkarmak, fiyatları izlemek veya reklamları izlemek için pazarlama araştırmasında kazımak olabilir.

SiteAnalyzer'da, kazıma, çıkarma kurallarının yapılandırıldığı Veri Çıkarma sekmesinde yapılandırılır. Kurallar kaydedilebilir ve gerekirse düzenlenebilir.
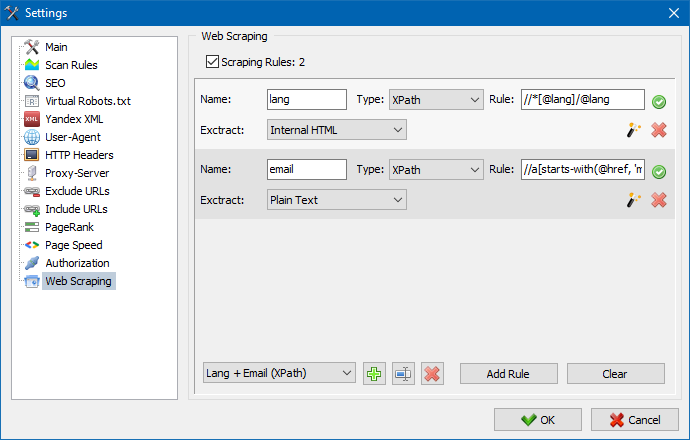
Ayrıca bir kural test modülü vardır. Yerleşik kural hata ayıklayıcısını kullanarak sitedeki herhangi bir sayfanın HTML içeriğini hızlı ve kolay bir şekilde alabilir ve sorguların çalışmasını test edebilir ve ardından SiteAnalyzer'da verileri ayrıştırmak için hata ayıklanmış kuralları kullanabilirsiniz.

Veri çıkarma işlemini bitirdikten sonra, toplanan tüm bilgiler Excel'e aktarılabilir.
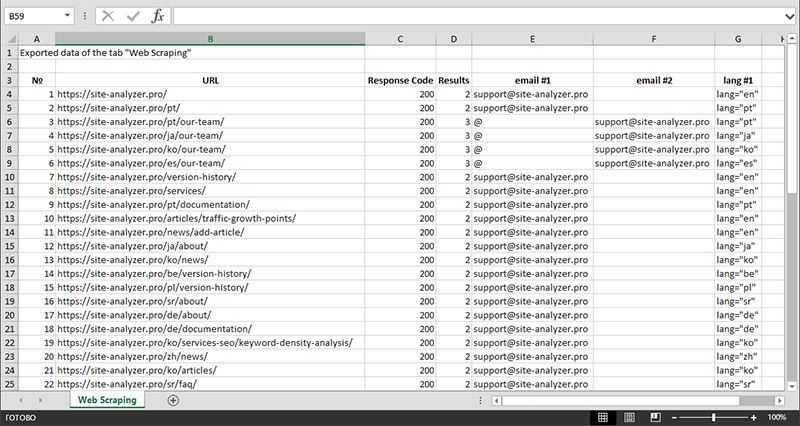
Modülün işleyişi hakkında daha ayrıntılı bir çalışma ve en yaygın kuralların ve düzenli ifadelerin bir listesi için
2. Site içindeki içeriğin benzersizliğini kontrol etme.
Bu araç, yinelenen sayfaları aramanıza ve site içindeki metinlerin benzersizliğini kontrol etmenize olanak tanır. Başka bir deyişle, bu, kendi aralarında benzersizlik için bir grup URL'nin toplu kontrolüdür.
Bu, şu durumlarda yararlı olabilir:
- Tam yinelenen sayfaları aramak için (örneğin, parametreleri ve aynı sayfayı içeren ancak CNC görünümünde olan bir sayfa).
- Kısmi içerik eşleşmeleri aramak için (örneğin, bir mutfak blogunda birbirine %96 benzeyen iki pancar çorbası tarifi, olası trafik yamyamlığından kurtulmak için makalelerden birinin silinmesi gerektiğini düşündürür).
- Bir makale sitesinde, yanlışlıkla 10 yıl önce yazdığınız bir konu hakkında bir makale yazdınız. Bu durumda, aracımız böyle bir makalenin bir kopyasını da algılayacaktır.
İçeriğin benzersizliğini kontrol etme aracının prensibi basittir: program, içeriği web sitesi URL'leri listesinden indirir, sayfanın metin içeriğini alır (HEAD bloğu ve HTML etiketleri olmadan) ve ardından bunları her biri ile karşılaştırır. diğer shingle algoritmasını kullanarak.

Böylece, zona kullanarak sayfaların benzersizliğini belirleriz ve hem %0 benzersizliğe sahip sayfaların tam kopyalarını hem de metin içeriğinin çeşitli benzersizlik derecelerine sahip kısmi kopyaları hesaplayabiliriz. Program shingle uzunluğu 5 ile çalışmaktadır.
Bu makalede modülün nasıl çalıştığı hakkında daha fazla bilgi edinebilirsiniz.: >>
3. Google PageSpeed tarafından sayfa yükleme hızının kontrol edilmesi.
Google arama devinin PageSpeed Insights aracı, belirli sayfa öğelerinin yükleme hızını kontrol etmenize olanak tanır ve ayrıca tarayıcının masaüstü ve mobil sürümleri için ilgilenilen URL'lerin genel yükleme hızı puanını gösterir.

Google'ın aracı herkes için iyidir, ancak önemli bir dezavantajı vardır - sitenizin birçok sayfasını kontrol ederken rahatsızlık yaratan grup URL kontrolleri oluşturmanıza izin vermez: 100 veya daha fazla URL için indirme hızını manuel olarak kontrol etmeyi kabul edin. bir sayfa bir angaryadır ve çok zaman alabilir.
Bu nedenle, Google PageSpeed Insights aracındaki özel bir API aracılığıyla ücretsiz olarak sayfa yükleme hızının grup kontrollerini oluşturmanıza olanak tanıyan bir modül oluşturduk.

Ana analiz edilen parametreler:
- FCP (First Contentful Paint) – ilk içeriği görüntüleme zamanı.
- SI (Speed Index) – içeriğin bir sayfada ne kadar hızlı görüntülendiğinin bir göstergesi.
- LCP (Largest Contentful Paint) – sayfadaki en büyük öğe için görüntüleme süresi.
- TTI (Time to Interactive) – sayfanın kullanıcı etkileşimi için tamamen hazır hale geldiği süre.
- TBT (Total Blocking Time) – içeriğin ilk oluşturulmasından kullanıcı etkileşimi için hazır oluşuna kadar geçen süre.
- CLS (Cumulative Layout Shift) – kümülatif düzen kayması. Sayfanın görsel kararlılığını ölçmeye yarar.
SiteAnalyzer'ın çok iş parçacıklı çalışması nedeniyle, yüzlerce veya daha fazla URL'yi kontrol etmek yalnızca birkaç dakika sürebilir ve bu, bir tarayıcı aracılığıyla manuel modda bir gün veya daha fazla sürebilir.
Aynı zamanda, URL'nin analizi sadece birkaç tıklamayla gerçekleşir, ardından kontrollerin ana özellikleri de dahil olmak üzere Excel'de uygun bir biçimde bir rapor indirilebilir.
Başlamak için tek ihtiyacınız olan bir API anahtarı almak.
Bunun nasıl yapılacağı bu makalede anlatılmaktadır. >>
4. Projeleri klasörlere göre gruplandırma özelliği eklendi.
Projeler listesinde daha rahat gezinme için siteleri klasörlere göre gruplandırma özelliği eklendi.

Ayrıca proje listesini isme göre filtrelemek de mümkün oldu.
5. Program ayarlarının arayüzü güncellendi.
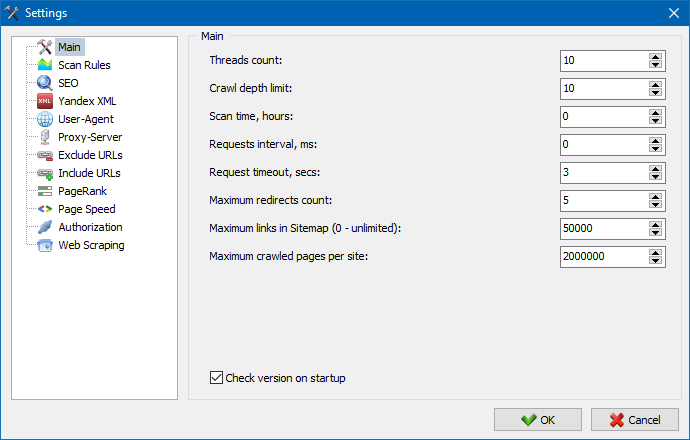
Programın işlevselliğinin genişlemesiyle, sekmeleri kullanmamız "sıkışık" hale geldi, bu nedenle ayarlar penceresini daha anlaşılır ve işlevsel bir arayüze yeniden biçimlendirdik.
Notlar:
- URL istisnalarının yanlış hesaplanması düzeltildi
- site tarama derinliğinin yanlış hesaplanması düzeltildi
- bir dosyadan içe aktarılan URL'ler için yeniden yönlendirmelerin görüntülenmesi
- sekmelerdeki sütunların sırasını yeniden düzenleme ve hatırlama yeteneği geri yüklendi
- kanonik olmayan sayfaların geri yüklenen muhasebesi, sorunu boş meta etiketlerle çözdü
- Bilgi sekmesinde bağlantı bağlantılarının geri yüklenen görüntüsü
- panodan çok sayıda URL'nin hızlandırılmış içe aktarımı
- başlık ve açıklamanın her zaman doğru ayrıştırılmaması düzeltildi
- resimlerde alt ve başlığın restore edilmiş görüntüsü
- bir projeyi tararken "Harici bağlantılar" sekmesine geçerken sabit donma
- projeler arasında geçiş yaparken ve "Site tarama istatistikleri" sekmesinin düğümlerini güncellerken oluşan hatayı düzeltti
- parametrelerle URL için yuvalama düzeyinin yanlış tanımı düzeltildi
- ana tablodaki HTML-karma alanına göre sabit veri sıralaması
- programın Kiril alanlarıyla optimize edilmiş çalışması
- güncellenmiş program ayarları arayüzü
- güncellenmiş logo tasarımı


Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Önceki Sürümlere Genel Bakış:
- Genel bakış yeni sürümü SiteAnalyzer 2.2
- Genel bakış yeni sürümü SiteAnalyzer 2.1
- Genel bakış yeni sürümü SiteAnalyzer 2.0



















