





















Celem programu
Program SiteAnalyzer jest przeznaczony do analizy strony internetowej i identyfikacji błędów technicznych (wyszukiwanie uszkodzonych linków, duplikatów stron niepoprawnych odpowiedzi serwera), a także błędów i braków w SEO-optymalizacji (puste meta-tagi, nadmiar lub brak nagłówków h1, analiza treści strony, jakość перелинковки i wiele innych parametrów SEO).

Podstawowe możliwości
- Skanowanie wszystkich stron serwisu, a także obrazków, skryptów i dokumentów
- Pobieranie kody odpowiedzi serwera dla każdej strony serwisu (200, 301, 302, 404, 500, 503 itp.)
- Oznaczanie obecności i zawartości Title, Keywords, Description, H1-H6
- Wyszukiwanie i wyświetlanie "duplikatów" stron, meta-tagów i nagłówków
- Wykrywanie obecności atrybutu rel="canonical" dla każdej strony serwisu
- Zgodnie z wytycznymi pliku "robots.txt", metatag "roboty" lub X-Robots-Tag
- Księgowanie "noindex" i "nofollow" podczas indeksowania stron witryny
- Skrobanie danych za pomocą XPath, CSS, XQuery, RegEx
- Sprawdzanie unikalności treści w serwisie
- Sprawdzanie szybkości ładowania strony przez Google PageSpeed
- Analiza referencyjna: definicja linków wewnętrznych i zewnętrznych dla dowolnej strony witryny
- Obliczanie wewnętrznego PageRank dla każdej strony witryny
- Określanie liczby przekierowań ze strony (przekierowania)
- Skanuj dowolne adresy URL i zewnętrzny plik Sitemap.xml
- Generowanie mapy witryny "sitemap.xml" (z możliwością podziału na kilka plików)
- Filtrowanie danych według dowolnego parametru (elastyczna konfiguracja filtrów o dowolnej złożoności)
- Szukaj dowolnych treści na stronie
- Eksport raportów w formacie CSV, Excel i PDF
Różnice w stosunku do analogów
- Niskie wymagania co do zasobów komputera, małe zużycie pamięci ram
- Skanowanie stron internetowych praktycznie każdej ilości z powodu niskich wymagań do zasobów komputera
- Przenośny format (działa bez instalacji na komputerze PC lub bezpośrednio z nośnika wymiennego)
Sekcje dokumentacji
- Początek pracy
- Ustawienia programu
- Podstawowe ustawienia
- Skanowanie
- SEO
- Wirtualne roboty.txt new
- Yandex XML
- User-Agent
- Dowolne nagłówki HTTP new
- Proxy-serwer
- Wyklucz adres URL
- Śledź adres URL
- PageRank
- Upoważnienie
- Praca z programem
- Ustawienie kolumn i kart
- Filtrowanie danych
- Statystyki witryny technicznej
- Statystyki SEO
- Custom Filters
- Custom Search
- Skrobanie danych
- Sprawdzanie unikalności treści
- Sprawdzanie szybkości ładowania strony
- Struktura witryny
- Menu kontekstowe listy projektów
- Wizualizacja struktury strony
- Wykres rozkładu linków wewnętrznych
- Wykres prędkości ładowania strony
- Generowanie Sitemap.xml
- Skanowanie dowolnych adresów URL
- Dashboard
- Eksport danych
- Wielojęzyczność
- Kompresja bazy danych
Początek pracy
Po uruchomieniu programu użytkownik jest pasek adresu, aby wprowadzić adres URL analizowanego serwisu (można wpisać dowolną stronę serwisu, tak jak robot, klikając na linki oryginalnej strony ominie wszystkie strony, w tym strony głównej, pod warunkiem, że wszystkie linki są w HTML i nie wykorzystują Javascript).
Po naciśnięciu przycisku "Start", robot zaczyna pominięciem wszystkich stron wewnętrznych linków (na zasoby zewnętrzne nie przechodzi, także nie przechodzi na linki, wykonującym na Javascript).
Po tym, jak robot ominie wszystkie strony staje się dostępny raport wykonany w postaci tabeli i wyświetlający dane pogrupowane w tematycznych zakładkach.
Wszystkie analizowane projekty są wyświetlane w lewej części programu i automatycznie zapisywane w bazie danych programu wraz z uzyskanymi danymi. W celu usunięcia niepotrzebnych stron internetowych za pomocą menu kontekstowego listy projektów.
Uwaga:
- po kliknięciu na przycisk "Pauza" skanowanie projektu zostaje zawieszone, równolegle aktualny postęp skanowania jest zapisywany do bazy, co pozwala, na przykład, zamknąć program i kontynuować skanowanie projektu po ponownym uruchomieniu programu od miejsca zatrzymania
- przycisk "Stop", aby przerwać skanowanie bieżącego projektu bez możliwości przedłużenia jego skanowania
Ustawienia programu
Sekcja menu głównego "Ustawienia" przeznaczony jest do cienkich ustawień programu z zewnętrznymi stronami i zawiera 7 kart:

Sekcja podstawowych ustawień służy do określenia programu własnych wytycznych wykorzystywanych podczas indeksowania witryny.
Opis parametrów:
- Ilość strumieni
- Im więcej wątków, tym więcej URL będzie w stanie obsłużyć w jednostce czasu. Przy tym należy wziąć pod uwagę, że większa liczba wątków prowadzi do większej ilości zasobów KOMPUTERA. Zaleca się liczba wątków w przedziale 5-10.
- Czas skanowania
- Służy do ustawiania ograniczenia skanowania serwisu na czas. Jest mierzona w godzinach.
- Maksymalna głębokość
- Ten parametr służy do określania głębokości skanowania serwisu. Strona główna serwisu ma poziom zagnieżdżenia = 0. Na przykład, jeśli chcesz skanować strony widoku "somedomain.ru/catalog.html" i "somedomain.ru/catalog/tovar.html" to w takim przypadku należy ustawić wartość maksymalną głębokość = 2.
- Opóźnienie między żądaniami
- Służy do ustawiania przerwy w działaniach skanera do stron serwisu. To jest konieczne dla stron internetowych na "słabych" miejsc, nie выдерживающих dużych obciążeń i częste do nich spraw.
- Limit czasu żądania
- Ustawianie czasu oczekiwania na odpowiedź serwisu na żądanie programu. Jeżeli którakolwiek ze stron serwisu odpowiadają powoli (długo się ładują), skanowanie strony może potrwać dość długo. Takie strony można odciąć, określając wartość, po którym skaner przejdzie do skanowania pozostałych stron witryny, a tym samym nie będzie opóźniać ogólny postęp.
- Liczba skanowanych stron serwisu
- Ograniczenie na maksymalną liczbę skanowanych stron. Jest to przydatne, jeśli, na przykład, trzeba przeskanować pierwsze N stron (przy czym nie są brane pod uwagę zdjęcia, pliki stylów, skrypty i inne typy plików).

Wziąć pod uwagę treści
- W tej sekcji można wybrać typy danych, które będą brane pod uwagę parser podczas przeszukiwania stron (obrazów, filmów, style, skrypty), albo wykluczyć nadmiar informacji podczas парсинге.
Zasady skanowania
- Dane ustawienia związane z ustawieniami wyjątków podczas przeszukiwania witryny сканнером za pomocą pliku "robots.txt", na linki typu "nofollow", a także za pomocą dyrektywy "meta name= "robots" bezpośrednio w kodzie stron serwisu.

Ta sekcja służy do określenia głównych analizowanych parametrów SEO, które w przyszłości będą sprawdzane na poprawność przy парсинге stron, po czym generowane statystyki będą wyświetlane w zakładce "Statystyki SEO" w prawej części głównego okna programu.
Za pomocą tych ustawień możesz wybrać usługę, dzięki której sprawdzisz indeksację stron w wyszukiwarce Yandex. Istnieją dwie opcje sprawdzania indeksacji: przy użyciu usługi Yandex XML lub usługi Majento.ru.

Wybierając usługę Yandex XML, należy wziąć pod uwagę możliwe ograniczenia (godzinowe lub dzienne), które można zastosować podczas sprawdzania indeksacji stron, dotyczące istniejących limitów na koncie Yandex, w wyniku czego często mogą wystąpić sytuacje, w których ograniczenia na koncie nie wystarczą, aby sprawdzić wszystkie strony na raz i do tego trzeba czekać na następną godzinę.
Korzystając z usługi Majento.ru, ograniczenia godzinowe lub dzienne są praktycznie nieobecne, ponieważ twój limit dosłownie łączy się z ogólną pulą limitów, która nie jest mała sama w sobie, ale ma także znacznie większy limit z ograniczeniami godzinowymi niż którekolwiek z indywidualnych kont użytkownika w Yandex XML.

Wirtualnego pliku robots.txt można użyć zamiast prawdziwego robots.txt hostowanego w witrynie.
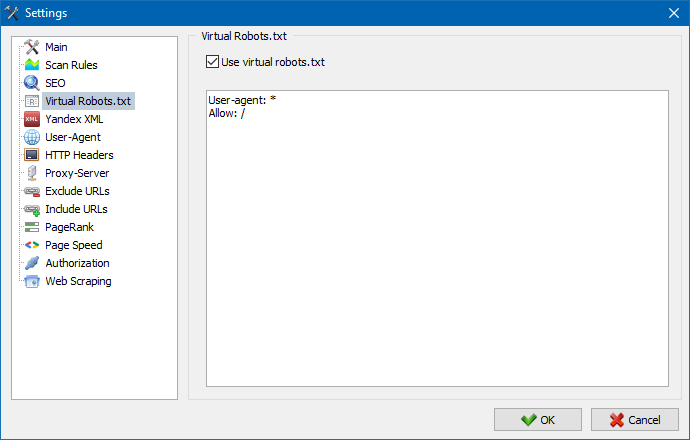
Jest to przydatne podczas testowania witryny, gdy na przykład musisz zindeksować pewne sekcje witryny, które są zamknięte przed indeksowaniem (lub odwrotnie - nie bierz ich pod uwagę podczas indeksowania), a nie musisz fizycznie wykonywać zmiany w prawdziwym pliku robots.txt i poświęć na to czas programisty.
Uwaga: podczas importowania listy adresów URL są brane pod uwagę dyrektywy wirtualnego pliku robots.txt (jeśli ta opcja jest aktywna), w przeciwnym razie żaden plik robots.txt nie jest brany pod uwagę dla listy adresów URL.
W sekcji User-Agent można określić, w jaki użytkownik-agent będzie się przedstawiać program podczas dostępu do zewnętrznych stron internetowych podczas skanowania. W умочанию, zainstalowana użytkownika użytkownik-agent, jednak w razie potrzeby można wybrać jeden ze standardowych agentów, najczęściej spotykanych w internecie. Są wśród nich takie, jak: boty wyszukiwarek YandexBot, GoogleBot, MicrosoftEdge, boty przeglądarek Chrome, Firefox, IE8, a także urządzeń mobilnych iPhone, Android i wiele innych.

Korzystając z tej opcji, możesz analizować reakcję witryny i stron na różne żądania. Na przykład ktoś może potrzebować wysłać Referer w żądaniu, właściciele witryn wielojęzycznych chcą przesyłać Accept-Language | Charset | Encoding, a ktoś musi przesłać nietypowe dane w nagłówkach Accept-Encoding, Cache-Control, Pragma itd. NS.
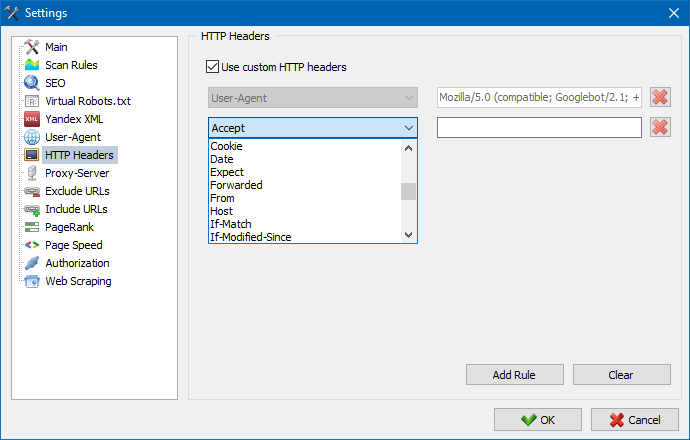
Korzystając z tej opcji, możesz analizować reakcję witryny i stron na różne żądania. Na przykład ktoś może potrzebować wysłać Referer w żądaniu, właściciele witryn wielojęzycznych chcą przesyłać Accept-Language | Charset | Encoding, a ktoś musi przesłać nietypowe dane w nagłówkach Accept-Encoding, Cache-Control, Pragma itd. NS.
Jeśli istnieje potrzeba działać przez pełnomocnika, w tym dziale możesz dodać listę serwerów proxy, przez które program będzie odwoływać się do zewnętrznych zasobów. Dodatkowo, istnieje możliwość sprawdzania proxy na wydolność, a także funkcja usuwania nieaktywnych serwerów proxy.

Ta sekcja jest przeznaczona dla wykluczenia pominięcie niektórych stron i sekcji strony internetowej przy парсинге.
Korzystanie z wzorców wyszukiwania * i ? możesz określić, które sekcje witryny nie powinny być przeszukiwane przez przeszukiwacz, a zatem nie powinny być uwzględniane w bazie danych programu. Ta lista jest lokalny listą wyjątków na czas skanowania strony (w stosunku do niego "globalnym" listą jest plik "robots.txt" w katalogu głównym serwisu).

Podobnie pozwala dodawać adresy URL, które muszą być indeksowane. W takim przypadku wszystkie inne adresy URL poza tymi folderami zostaną zignorowane podczas skanowania. Ta opcja działa również z wzorcami wyszukiwania * i ?

Korzystając z parametru PageRank, możesz przeanalizować strukturę nawigacji swoich stron, a także zoptymalizować system wewnętrznych łączy zasobu internetowego, aby przesłać masę referencyjną do najważniejszych stron.

Program ma dwie możliwości obliczania PageRank: klasyczny algorytm i jego bardziej nowoczesny odpowiednik. Ogólnie rzecz biorąc, do analizy wewnętrznego linkowania witryny nie ma dużej różnicy przy korzystaniu z pierwszego lub drugiego algorytmu, więc można użyć dowolnego z dwóch algorytmów.
Szczegółowy opis algorytmu i zasady obliczania PageRank można znaleźć w artykule "Obliczanie wewnętrznego PageRank": >>

Wprowadź login i hasło do automatycznej autoryzacji na stronach zamkniętych przez .htpasswd i chronionych autoryzacją serwera BASIC.
Praca z programem
Po zakończeniu skanowania, użytkownik staje się dostępne informacje zawarte w sekcji "dane Podstawowe". Każda karta zawiera dane pogrupowane względem ich nazw (na przykład zakładka "Title" zawiera zawartość nagłówków stron <title></title>, zakładka "Zdjęcia" - zawiera listę wszystkich obrazów serwisu i tak dalej). Za pomocą tych danych można przeprowadzać analizę treści strony, znalezienie "zepsute" linki lub nieprawidłowo wypełnione meta-tagi.

W razie potrzeby (na przykład, po wprowadzeniu zmian na stronie) za pomocą menu kontekstowego istnieje możliwość nowe skanowanie adresów URL, aby wyświetlić zmian w programie.
Za pomocą tego menu można wyświetlać duplikaty stron według odpowiednich parametrów (ujęcia title, description, keywords, h1, h2, treści stron).

Element "Ponownie skanuj adres URL z kodem 0" ma na celu automatyczne sprawdzenie wszystkich stron, które dają kod odpowiedzi 0 (Limit czasu odczytu). Ten kod odpowiedzi jest zwykle podawany, gdy serwer nie ma czasu na dostarczenie treści, a połączenie zostaje przerwane odpowiednio po przekroczeniu limitu czasu, strony nie można załadować i nie można wyodrębnić z niej informacji.
Teraz można wybrać, które karty będą wyświetlane w interfejsie danych podstawowych (w końcu stało się możliwe pożegnać się z moralnie przestarzałe kartą Meta Keywords). To jest wygodne, jeśli karty nie mieszczą się na ekranie, albo rzadko ich używasz.

Kolumny można również ukryć lub przenieść w odpowiednie miejsce za pomocą przeciągania.
Wyświetlanie kart i kolumn można ustawić za pomocą wywołania menu kontekstowego na pasku podstawowych danych. Przenoszenie kolumn odbywa się za pomocą myszy.
W celu ułatwienia analizy statystyk serwisu w programie dostępna jest filtrowanie danych. Filtrowanie jest możliwe w dwóch wariantach:
- na wszystkich polach za pomocą "szybkiego" filtra
- przy użyciu niestandardowego filtra (za pomocą ustawień zaawansowanych pobierania danych)
Szybki filtr
Służy do szybkiego filtrowania danych i stosuje się jednocześnie na wszystkich polach bieżącej karty.

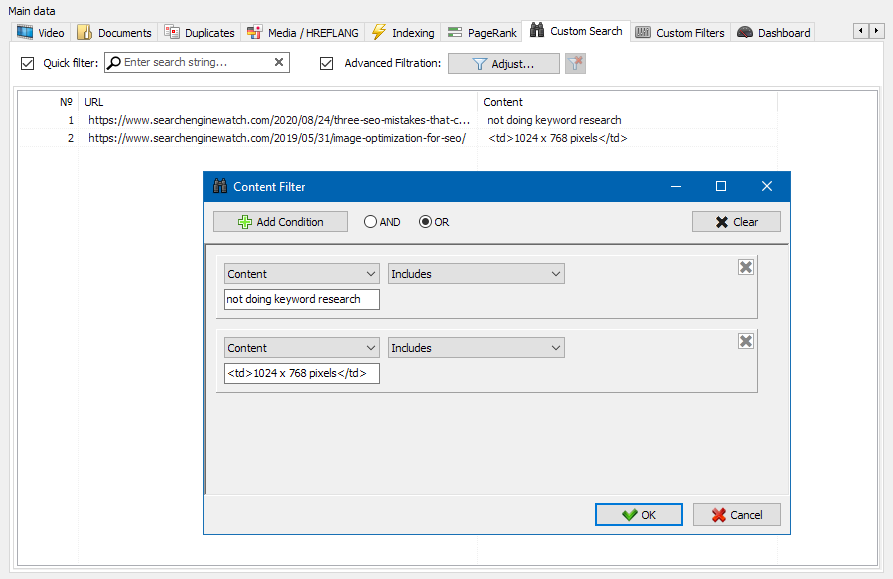
Filtr niestandardowy
Jest przeznaczony do szczegółowych filtrowania i może zawierać jednocześnie kilka warunków. Na przykład, dla meta-tagu "title" idziesz filtrować strony według ich długości, aby nie przekraczał 70 znaków i jednocześnie zawierał tekst "aktualności". Wtedy ten filtr będzie wyglądać tak:

W ten sposób, stosując konfigurowalny filtr do każdej z kart można otrzymać próbki danych o dowolnej złożoności.
Statystyki witryny technicznej
Zakładka Statystyki techniczne witryny znajduje się w panelu Dane dodatkowe i zawiera zestaw podstawowych parametrów technicznych serwisu: statystyki linków, metatagów, kodów odpowiedzi strony, parametrów indeksowania stron, typów zawartości itp. parametry.
Klikając jeden z parametrów, są one automatycznie filtrowane w odpowiedniej zakładce danych podstawowych serwisu, a jednocześnie statystyki są wyświetlane na schemacie u dołu strony.

Zakładka SEO-statistics jest przeznaczona do przeprowadzania pełnowartościowych audytów strony i zawiera ponad 50 głównych parametrów SEO oraz identyfikuje ponad 60 kluczowych błędów optymalizacji wewnętrznej! Mapowanie błędów jest podzielone na grupy, które z kolei zawierają zestawy analizowanych parametrów i filtrów wykrywających błędy na stronie.
Szczegółowy opis wszystkich sprawdzonych parametrów znajduje się w tym artykule. >>

Dla wszystkich wyników filtrowania możliwe jest szybkie eksportowanie ich do Excela bez dodatkowych dialogów (raport zapisywany jest w folderze programu).
Na tej karcie znajdują predefiniowane filtry, które umożliwiają tworzenie próbkowania dla wszystkich linków zewnętrznych, błędy 404, obrazów i innych opcji ze wszystkimi stronami, na których są obecne. W ten sposób, można teraz łatwo i szybko uzyskać listę linków i stron, na których są one umieszczone, albo wybrać wszystkie uszkodzone linki i od razu zobaczyć, na jakich stronach się znajdują.

Wszystkie raporty dostępne są w programie w trybie online i są wyświetlane w zakładce "Custom" panelu danych podstawowych. Dodatkowo, istnieje możliwość ich eksportu do programu Excel poprzez menu główne.
Funkcja wyszukiwania treści witryny umożliwia przeszukiwanie kodu źródłowego i wyświetlanie stron internetowych zawierających poszukiwaną treść.
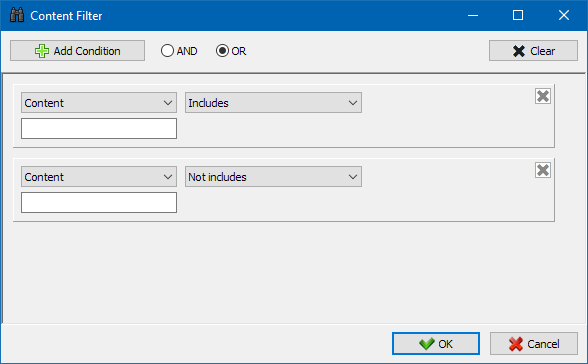
Moduł filtrów niestandardowych umożliwia sprawdzenie obecności mikro-znaczników, metatagów, systemów analitycznych, fragmentów dowolnego tekstu lub kodu HTML w serwisie.
W oknie konfiguracji filtru znajduje się kilka parametrów służących do wyszukiwania określonych fragmentów tekstu na stronach serwisu lub odwrotnie, do wykluczania stron zawierających określony tekst lub fragmenty kodu HTML z wyników wyszukiwania (ta funkcja jest podobna do wyszukiwania treści w kodzie źródłowym strony przy użyciu Ctrl-F) ...
Zazwyczaj skrobanie służy do rozwiązywania zadań trudnych do ręcznego wykonania. Może to być wyodrębnianie opisów produktów w celu stworzenia nowego sklepu internetowego, skrobanie w badaniach marketingowych w celu monitorowania cen lub monitorowania reklam.

W SiteAnalyzer skrobanie jest konfigurowane na karcie Wyodrębnianie danych, na której konfiguruje się reguły wyodrębniania. Reguły można zapisywać i w razie potrzeby edytować.
Dostępny jest również moduł testowania reguł. Korzystając z wbudowanego debugera reguł, możesz szybko i łatwo pobrać zawartość HTML dowolnej strony w witrynie i przetestować działanie zapytań, a następnie użyć debugowanych reguł do analizy danych w SiteAnalyzer.

Po zakończeniu ekstrakcji danych wszystkie zebrane informacje można wyeksportować do Excela.
Bardziej szczegółowe badanie działania modułu oraz listę najczęstszych reguł i wyrażeń regularnych można znaleźć w artykule
Sprawdzanie unikalności treści
To narzędzie umożliwia wyszukiwanie duplikatów stron i sprawdzanie unikalności tekstów w serwisie. Innymi słowy, jest to zbiorcze sprawdzenie grupy adresów URL pod kątem niepowtarzalności między sobą.
Może to być przydatne w przypadkach:
- Wyszukiwanie pełnych duplikatów stron (na przykład strony z parametrami i tej samej strony, ale w widoku CNC).
- Aby wyszukać częściowe dopasowania treści (na przykład dwa przepisy barszczowe na blogu kulinarnym, które są do siebie podobne w 96%, co sugeruje, że należy usunąć jeden z artykułów, aby pozbyć się możliwej kanibalizacji ruchu).
- Kiedy na stronie z artykułami przypadkowo napisałeś artykuł na temat, który napisałeś już 10 lat temu. W takim przypadku nasze narzędzie wykryje również duplikat takiego artykułu.
Zasada działania narzędzia do sprawdzania unikalności treści jest prosta: program pobiera ich treść z listy adresów URL witryn, otrzymuje treść tekstową strony (bez bloku HEAD i bez tagów HTML), a następnie porównuje je ze sobą inne przy użyciu algorytmu gontu.

Tak więc za pomocą gontów określamy unikalność stron i możemy obliczyć zarówno pełne duplikaty stron o unikalności 0%, jak i częściowe duplikaty o różnym stopniu unikalności treści tekstowej. Program działa z gontem o długości 5.
Więcej o działaniu modułu dowiesz się z tego artykułu.: >>
Sprawdzanie szybkości ładowania strony
Narzędzie PageSpeed Insights giganta wyszukiwania Google pozwala sprawdzić szybkość ładowania niektórych elementów strony, a także pokazuje ogólny wynik szybkości ładowania interesujących adresów URL dla wersji przeglądarki na komputery i urządzenia mobilne.

Narzędzie Google jest dobre dla każdego, jednak ma jedną istotną wadę - nie pozwala na tworzenie grupowych kontroli adresów URL, co stwarza niedogodności podczas sprawdzania wielu stron Twojej witryny: zgódź się na ręczne sprawdzanie szybkości pobierania dla 100 lub więcej adresów URL na jedna strona to przykry obowiązek i może zająć dużo czasu.
Dlatego stworzyliśmy moduł, który pozwala za darmo tworzyć grupowe kontrole szybkości ładowania strony poprzez specjalne API w narzędziu Google PageSpeed Insights.

Główne analizowane parametry:
- FCP (First Contentful Paint) – czas na wyświetlenie pierwszej treści.
- SI (Speed Index) – wskaźnik szybkości wyświetlania treści na stronie.
- LCP (Largest Contentful Paint) – czas wyświetlania największego elementu na stronie.
- TTI (Time to Interactive) – czas, w którym strona jest w pełni gotowa do interakcji z użytkownikiem.
- TBT (Total Blocking Time) – czas od pierwszego renderowania treści do gotowości do interakcji użytkownika.
- CLS (Cumulative Layout Shift) – skumulowane przesunięcie układu. Służy do pomiaru stabilności wizualnej strony.
Jednocześnie analiza samego adresu URL odbywa się za pomocą zaledwie kilku kliknięć, po czym można pobrać raport zawierający główne cechy sprawdzeń w wygodnej formie w Excelu.
Wszystko, czego potrzebujesz, aby zacząć, to zdobyć klucz API.
Jak to zrobić, opisano w tym artykule. >>
Ta funkcjonalność jest przeznaczony do tworzenia struktury strony internetowej na podstawie otrzymanych danych. Struktura strony jest generowany na podstawie zagnieżdżenia URL stron. Po generowania struktury dostępny jej eksport do pliku CSV-format (Excel).

Menu kontekstowe listy projektów
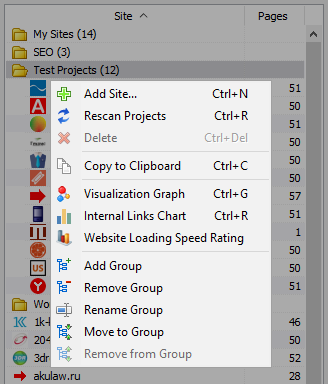
- Na liście projektów dostępne masowe skanowanie poprzez przydzielanie odpowiednich stron internetowych i naciśnięciu przycisku "Odświeża". Po czym wszystkie strony stają w kolejce i skanowane na przemian w trybie standardowym.
- Ponadto, dla ułatwienia pracy z programem, masowe usuwanie wybranych stron internetowych jest również dostępna na przycisk "Usuń".
- Oprócz pojedynczego skanowania stron internetowych, istnieje możliwość masowego dodawania witryn do listy projektów za pomocą specjalnego formularza, po czym użytkownik może wczytać interesujące projekty w całości.
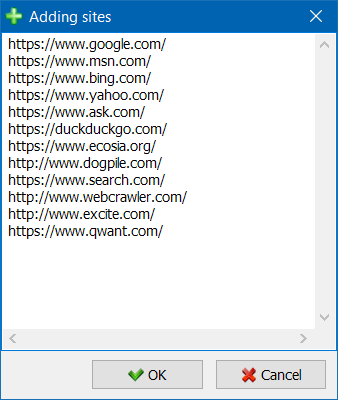
- Dla wygodniejszego poruszania się po liście projektów możliwe jest grupowanie witryn według folderów, a także filtrowanie listy projektów według nazwy.

Tryb renderowania odniesienia relacji na wykresie pomoże SEO specjalisty ocenić rozkład wewnętrznego PageRank na stronach serwisu, a także zrozumieć, jakie ze stron otrzymują większą odwołanie masę (i odpowiednio większy wewnętrzny odniesienia wagę w oczach wyszukiwarek), a w jaki stron i sekcji strony internetowej nie brakuje linków wewnętrznych.

Za pomocą trybu wizualizacji struktury witryny SEO-specjalista jest w stanie jednoznacznie ocenić, jak przebiega zmiana linków wewnętrznych na stronie internetowej, a także ze względu na prezentacji wizualnej masy PageRank, zakładanej w ten czy inny stron, niezwłocznie dokonać korekty w obecnej łączenie serwisu i tym samym zwiększyć trafność interesujących stron.
W lewej części okna wizualizacji znajdują się podstawowe narzędzia do pracy z hrabią:
- zmiana skali na wykresie
- obrót hrabiego o dowolny kąt
- przełączanie okna wykresu w tryb pełnoekranowy (działa również pod klawiszem F11)
- wyświetlanie / ukrywanie podpisów do węzłów (Ctrl-T)
- wyświetlanie / ukrywanie strzałek u linii
- wyświetlanie / ukrywanie linków do zewnętrznych zasobów (Ctrl-E)
- przełączanie trybu kolorów Dzień / Noc (Ctrl-D)
- wyświetlanie / ukrywanie legendy i statystyki hrabiego (Ctrl-L)
- zapisywanie wykresu w formacie PNG (Ctrl-S)
- okno ustawień renderowania (Ctrl-O)
W sekcji "Wygląd" jest przeznaczony do zmiany formatu wyświetlania węzłów w grafie. W trybie rysowania węzłów "PageRank", wymiary węzłów są ustawione względem ich wcześniej obliczonego wskaźnika PageRank, w wyniku czego na wykresie można wyraźnie zobaczyć, jakie strony otrzymują większy ciężar referencyjny, a jak dostaje mniej linków.
W trybie klasycznym wymiary węzłów są ustawione względem wybranej skali hrabiego wizualizacji.
Wykres rozkładu linków wewnętrznych
Ten wykres pokazuje rozkład masy linków wewnętrznych na stronach serwisu (możemy powiedzieć, że jest to wizualizacja linków w formie wizualnej, a nie jest to przedstawione na Grafie Wizualizacji). Czytaj więcej >>
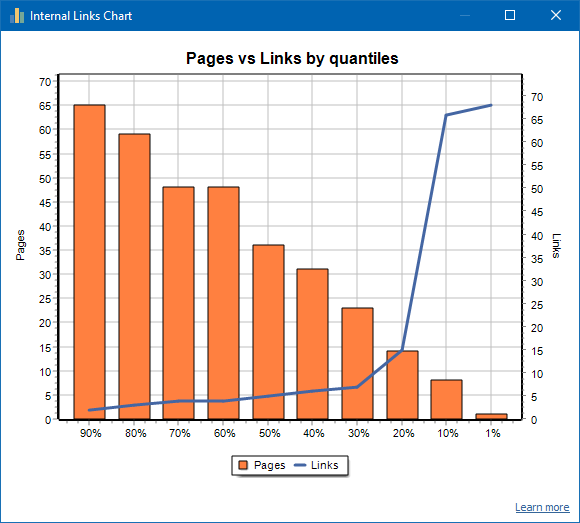
Po lewej stronie znajduje się liczba stron, po prawej liczba linków. Poniżej przedstawiono procentowe kwantyle na stronie. Podczas tworzenia wykresu zduplikowane linki są odrzucane (jeśli istnieją 3 linki ze strony A do strony B, liczymy je jako jeden).
Na przykład, na podstawie powyższego zrzutu ekranu, w przypadku witryny zawierającej około 70 stron:
- 1% strony mają ~68 linki przychodzące.
- 10% strony mają ~66 linki przychodzące.
- 20% strony mają ~15 linki przychodzące.
- 30% strony mają ~8 linki przychodzące.
- 40% strony mają ~7 linki przychodzące.
- 50% strony mają ~6 linki przychodzące.
- 60% strony mają ~5 linki przychodzące.
- 70% strony mają ~5 linki przychodzące.
- 80% strony mają ~3 linki przychodzące.
- 90% strony mają ~2 linki przychodzące.
Oznacza to, że jeśli widzimy, że mamy strony, do których prowadzi mniej niż 10 linków przychodzących, możemy uznać takie strony za słabo połączone i mamy 60% stron, do których zwykle prowadzą linki. Na tej podstawie możemy umieścić więcej wewnętrznych linków do tych słabo powiązanych stron (jeśli strony są ważne dla promocji) lub pozostawić je bez zmian, jeśli takie strony mają małe znaczenie i niski priorytet.
Ogólnie rzecz biorąc, strony zawierające mniej niż 10 linków wewnętrznych są rzadziej indeksowane przez roboty wyszukiwarek, w szczególności przez roboty Google.
Dlatego jeśli widzisz witrynę, która ma tylko 20-30% stron, do których zwykle prowadzą linki z całkowitej liczby stron w witrynie, warto zagłębić się w ustawienia linków lub pomyśleć o tym, jak sobie radzić z tymi 80-70% słabo połączonych stron (usuń, ukryj przed indeksowanie, wstaw przekierowania).
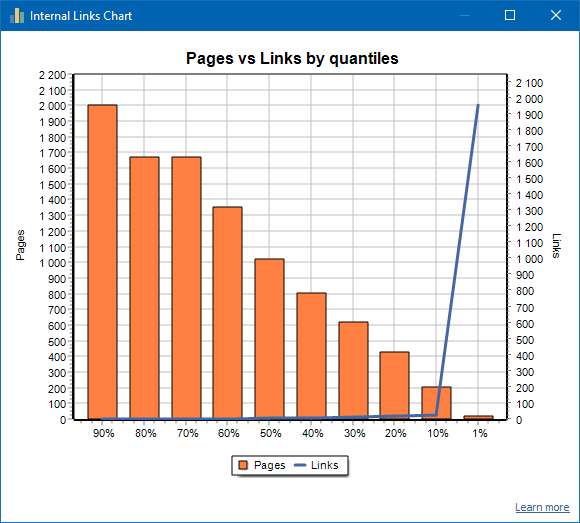
Przykład słabo połączonej witryny:
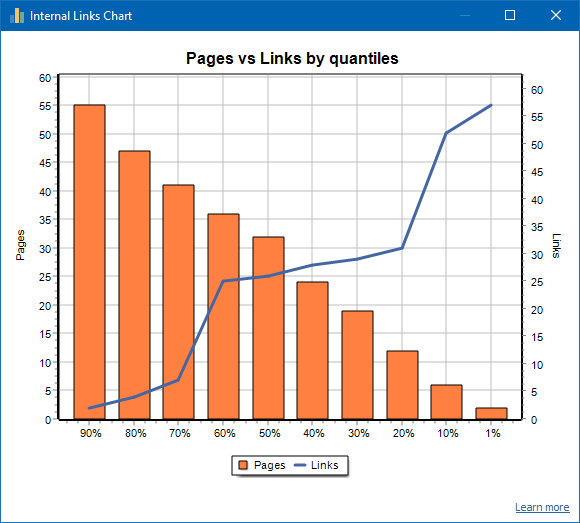
Przykład dobrze połączonej witryny:
Wykres prędkości ładowania strony
Wykres szybkości ładowania strony pozwala ocenić wydajność witryny. Dla jasności strony są podzielone na grupy i przedziały czasowe z krokiem 100 milisekund.
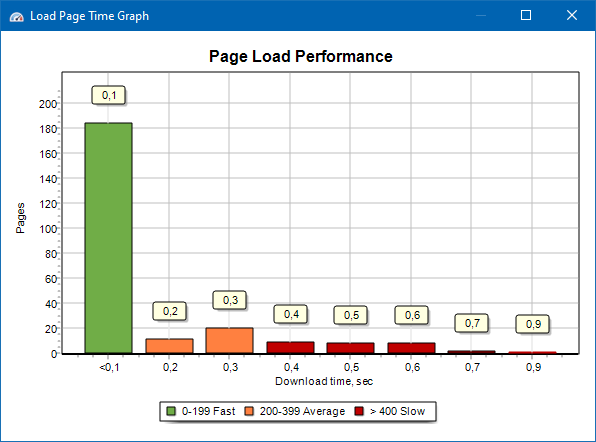
W ten sposób na podstawie wykresu można określić, jaka część stron witryny jest ładowana szybko (w ciągu 0-100 milisekund), która ze średnią prędkością (100-200 milisekund) i które strony są ładowane wystarczająco długo (400 milisekund lub więcej).
Uwaga: Podany czas to czas załadowania kodu źródłowego HTML, a nie czas pełnego załadowania stron (nie uwzględnia się renderowania strony ani ładowania elementów strony, takich jak obrazy i style).
Generowanie Sitemap.xml
Mapa witryny jest generowana na podstawie zindeksowanych stron lub obrazów witryn.
- Podczas generowania mapy serwisu składającej się ze stron, dodawane są do niej strony w formacie "tekst/html".
- Podczas generowania mapy witryny składającej się z obrazów, dodawane są do niej JPG, PNG, GIF i podobne obrazy.
Wygenerować mapę witryny można od razu po zeskanowaniu strony przez menu główne: przedmiot "Projekty -> Generowanie Sitemap".

Dla witryn dużych ilości od 50 000 stron, jest wyposażona w funkcję automatycznego podziału "sitemap.xml" na kilka plików (w tym przypadku główny plik zawiera łącza do dodatkowych, zawierających bezpośrednio linki do strony). Jest to związane z wymaganiami wyszukiwarek do obróbki plików map witryn o dużych rozmiarach.

W razie potrzeby, ilość stron w pliku "sitemap.xml" można zmieniać, zmieniając wartość 50 000 (ustawienie domyślne) na żądaną wartość w głównych ustawieniach programu.
Skanowanie dowolnych adresów URL
Punkt menu "Import URL" jest przeznaczony do skanowania dowolnych list adresów URL, a także XML-mapy witryny Sitemap.xml (w tym indeksu) w celu ich późniejszej analizy.
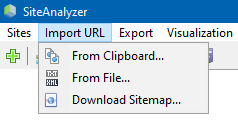
Skanowanie dowolnych adresów URL jest możliwe na trzy sposoby:
- poprzez wstawienie listy adresów URL ze schowka
- rozruchu z dysku twardego pliki w formacie *.txt i *.xml zawierający listę adresów URL
- poprzez pobraniu pliku Sitemap.xml bezpośrednio z serwisu
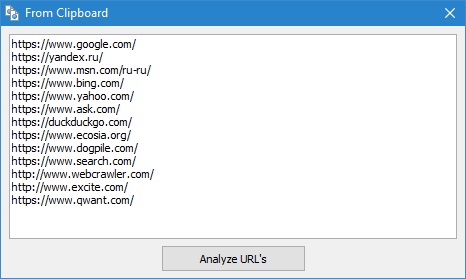
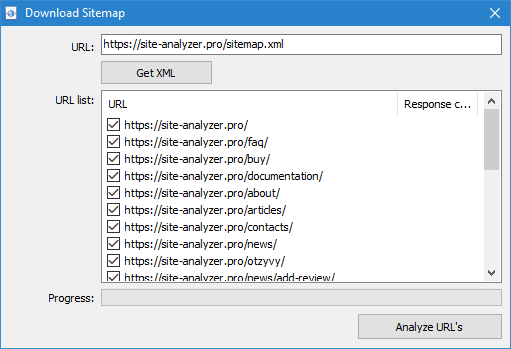
Cechą tego trybu jest to, że podczas skanowania dowolnych URL sam "projekt" nie jest zapisywane w programie i dane na nim nie jest dodawana do bazy. Również nie są dostępne sekcje "Struktura witryny" i "Дашборд".
Bardziej szczegółowo zapoznać się z pracą opcję "Import URL" można w tym artykule: Przegląd nowej wersji SiteAnalyzer 1.9.
Dashboard
Zakładka "Dashboard", wyświetla szczegółowy raport na temat aktualnego jako optymalizacji serwisu. Raport generowany jest na podstawie danych z zakładki "Statystyki SEO". Oprócz tych danych w raporcie jest wskazanie ogólnego wskaźnika jakości optymalizacji serwisu, obliczonego w 100-punktowej skali względem bieżącego stopnia jego optymalizacji. Istnieje możliwość eksportu danych z karty "Dashboard" w wygodny raport w formacie PDF.

Eksport danych
Dla bardziej elastycznego analizy uzyskanych danych istnieje możliwość ich ładowania w CSV-format (eksportowane bieżąca aktywna karta), a także generowania pełnego raportu do programu Microsoft Excel ze wszystkimi kartami w jednym pliku.

Podczas eksportu danych w programie Excel pojawi się specjalne okno, w którym użytkownik może wybrać interesujące kolumny, a następnie wygenerować raport z właściwymi danymi.

Wielojęzyczność
W programie istnieje możliwość wyboru preferowanego języka, w którym będą prowadzone prace.
Główne obsługiwane języki: polski, angielski, niemiecki, włoski, hiszpański, francuski... W tej chwili program jest przetłumaczona na więcej niż piętnaście (15) najbardziej popularnych języków.

Jeśli chcesz przetłumaczyć na swój język ojczysty, to wystarczy przetłumaczyć dowolny plik "*.lng" na żądany język, po czym przetłumaczony plik należy wysłać na adres "support@site-analyzer.pro" (komentarz do listu powinny być napisane w języku polskim lub angielskim) i twój przelew zostanie włączony w nowej wersji programu.
Bardziej szczegółowa instrukcja tłumaczenie programu na języki znajduje się w dystrybucji (plik "lcids.txt").
P.S. Jeśli masz jakieś uwagi dotyczące jakości tłumaczenia - wysyłaj uwagi i poprawki na "support@site-analyzer.ru".
Kompresja bazy danych
Polecenie menu głównego "Kompaktuj bazę danych" jest przeznaczony do wykonywania operacji pakowania bazy danych (czyszczenie bazy danych z usuniętych projektów, a także porządkowanie danych (odpowiednik defragmentacji danych na komputerach osobistych)).
Procedura ta jest skuteczna w przypadku, gdy, na przykład, z programu został usunięty duży projekt, który zawiera dużą liczbę rekordów. W ogóle zaleca się przeprowadzać okresowe kompresja danych na pozbycie się nadmiarowych danych i zmniejszenie objętości bazy.
Z odpowiedziami na pozostałe pytania można zapoznać się w dziale FAQ >>



















