





















 3,169
3,169안녕하세요 여러분! 다시 비즈니스를 시작합니다!
아주 오랜 시간이 지난 후 마침내 SiteAnalyzer의 새 릴리스를 준비했습니다. 이 새 릴리스가 귀하의 기대에 부응하고 SEO 홍보에 없어서는 안될 조수가 되기를 바랍니다.
SiteAnalyzer의 새 버전에서는 데이터 스크래핑(사이트에서 데이터 추출), 콘텐츠의 고유성 확인 및 Google PageSpeed에 의한 페이지 로드 속도 확인과 같이 사용자가 가장 많이 요청하는 몇 가지 기능을 구현했습니다. 동시에 많은 버그가 수정되었고 로고의 스타일이 변경되었습니다. 모든 것에 대해 더 자세히 이야기합시다.

주요 변경 사항
1. XPath, CSS, XQuery, RegEx로 데이터 스크래핑.
웹 스크래핑은 특정 규칙에 따라 사이트의 관심 페이지에서 데이터를 추출하는 자동화된 프로세스입니다.
주요 웹 스크래핑 방법은 XPath, CSS 선택기, XQuery, RegExp 및 HTML 템플릿을 사용한 구문 분석 방법입니다.
- XPath는 XML/XHTML 문서 요소를 위한 특수 쿼리 언어입니다. 요소에 액세스하기 위해 XPath는 페이지에서 원하는 요소에 대한 경로를 설명하여 DOM 탐색을 사용합니다. 도움을 받아 문서의 서수로 요소의 값을 얻고, 텍스트 내용이나 내부 코드를 추출하고, 페이지에 특정 요소가 있는지 확인할 수 있습니다.
- CSS 선택기는 해당 부분(속성)의 요소를 찾는 데 사용됩니다. CSS는 구문적으로 XPath와 유사하지만 경우에 따라 CSS 로케이터가 더 빠르고 더 설명적이고 간결합니다. CSS의 단점은 한 방향으로만 작동한다는 것입니다. 반면 XPath는 두 가지 방식으로 작동합니다(예: 자식으로 부모 요소를 검색할 수 있음).
- XQuery는 XPath를 기반으로 합니다. XQuery는 XML을 모방하므로 XSLT에서는 불가능한 방식으로 중첩 표현식을 생성할 수 있습니다.
- RegExp는 필요한 조건(정규 표현식)과 일치하는 일련의 텍스트 문자열에서 값을 추출하기 위한 공식 검색 언어입니다.
- HTML 템플릿은 원하는 조각에 대한 검색 템플릿을 설명하는 HTML 마크업과 데이터 추출 및 변환을 위한 기능 및 작업의 조합인 HTML 문서에서 데이터를 추출하기 위한 언어입니다.
일반적으로 스크래핑은 수동으로 처리하기 어려운 작업을 해결하는 데 사용됩니다. 이것은 새로운 온라인 상점을 만들기 위해 제품 설명을 추출하고, 가격을 모니터링하거나 광고를 모니터링하기 위해 마케팅 조사를 스크랩할 수 있습니다.

SiteAnalyzer에서 스크래핑은 추출 규칙이 구성된 데이터 추출 탭에서 구성됩니다. 규칙을 저장하고 필요한 경우 편집할 수 있습니다.
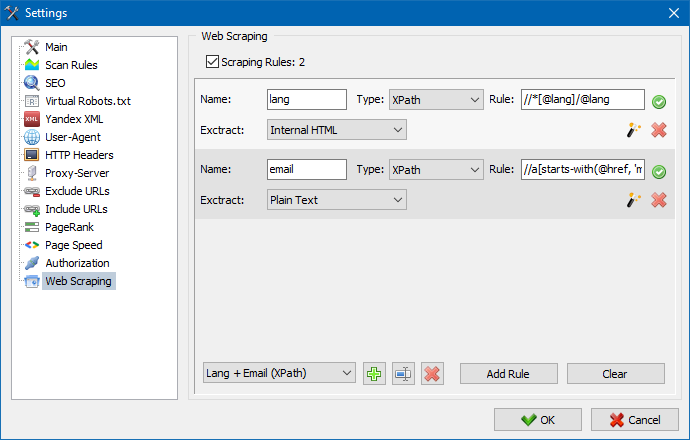
규칙 테스트 모듈도 있습니다. 기본 제공 규칙 디버거를 사용하면 사이트에 있는 모든 페이지의 HTML 콘텐츠를 빠르고 쉽게 가져오고 쿼리 작업을 테스트한 다음 SiteAnalyzer에서 데이터를 구문 분석하기 위해 디버깅된 규칙을 사용할 수 있습니다.

데이터 추출이 끝나면 수집된 모든 정보를 Excel로 내보낼 수 있습니다.
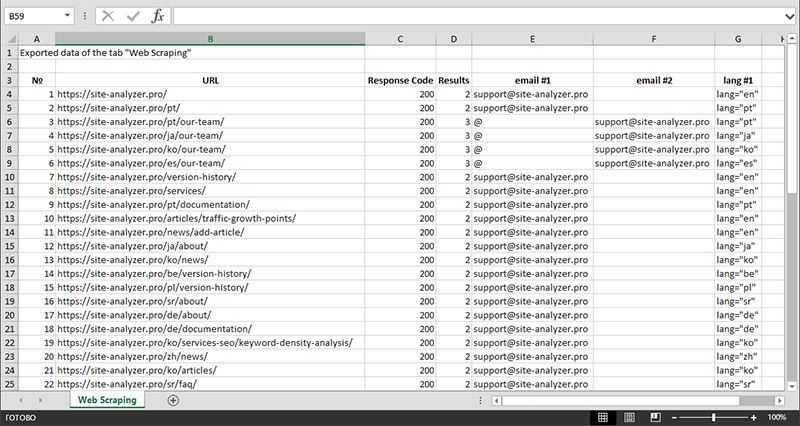
모듈 작동에 대한 자세한 연구와 가장 일반적인 규칙 및 정규식 목록은
2. 사이트 내 콘텐츠의 고유성을 확인합니다.
이 도구를 사용하면 중복 페이지를 검색하고 사이트 내 텍스트의 고유성을 확인할 수 있습니다. 즉, URL 그룹 간의 고유성에 대한 일괄 검사입니다.
다음과 같은 경우에 유용할 수 있습니다.
- 전체 중복 페이지를 검색합니다(예: 매개변수가 있는 페이지와 동일한 페이지이지만 CNC 보기에 있음).
- 부분 콘텐츠 일치 검색(예: 요리 블로그에 있는 두 개의 borscht 레시피는 서로 96% 유사합니다. 이는 가능한 트래픽 잠식을 없애기 위해 기사 중 하나를 삭제해야 함을 나타냄).
- 기사 사이트에서 실수로 10년 전에 이미 작성한 주제에 대한 기사를 작성했습니다. 이 경우 도구는 그러한 기사의 중복도 감지합니다.
콘텐츠의 고유성을 확인하는 도구의 원리는 간단합니다. 프로그램은 웹사이트 URL 목록에서 콘텐츠를 다운로드하고 페이지의 텍스트 콘텐츠(HEAD 블록 및 HTML 태그 없음)를 수신한 다음 각 콘텐츠와 비교합니다. 기타 대상 포진 알고리즘을 사용합니다.

따라서 대상 포진을 사용하여 페이지의 고유성을 결정하고 고유성이 0%인 페이지의 전체 복제본과 텍스트 콘텐츠의 고유한 정도가 다양한 부분 복제본을 모두 계산할 수 있습니다. 이 프로그램은 지붕널 길이가 5일 때 작동합니다.
이 문서에서 모듈의 작동 방식에 대해 자세히 알아볼 수 있습니다.: >>
3. Google PageSpeed로 페이지 로드 속도를 확인합니다.
Google 검색 대기업의 PageSpeed Insights 도구를 사용하면 특정 페이지 요소의 로드 속도를 확인할 수 있으며 데스크톱 및 모바일 버전의 브라우저에 대한 관심 URL의 전체 로드 속도 점수도 표시됩니다.

Google 도구는 모든 사람에게 유용하지만 한 가지 중요한 단점이 있습니다. 즉, 그룹 URL 검사를 생성할 수 없기 때문에 사이트의 많은 페이지를 검사할 때 불편을 겪을 수 있습니다. 100개 이상의 URL에 대한 다운로드 속도를 수동으로 검사하는 데 동의하십시오 한 페이지는 귀찮고 많은 시간이 걸릴 수 있습니다.
따라서 Google PageSpeed Insights 도구의 특수 API를 통해 페이지 로드 속도의 그룹 검사를 무료로 생성할 수 있는 모듈을 만들었습니다.

주요 분석 매개변수:
- FCP (First Contentful Paint) – 첫 번째 콘텐츠를 표시할 시간입니다.
- SI (Speed Index) – 콘텐츠가 페이지에 표시되는 속도를 나타내는 지표입니다.
- LCP (Largest Contentful Paint) – 페이지에서 가장 큰 요소의 표시 시간.
- TTI (Time to Interactive) – 페이지가 사용자 상호 작용을 위해 완전히 준비되는 시간입니다.
- TBT (Total Blocking Time) – 콘텐츠의 첫 번째 렌더링부터 사용자 상호 작용을 위한 준비까지의 시간입니다.
- CLS (Cumulative Layout Shift) – 누적 레이아웃 변경. 페이지의 시각적 안정성을 측정하는 역할을 합니다.
SiteAnalyzer의 다중 스레드 작업으로 인해 수백 개 이상의 URL을 확인하는 데 몇 분 밖에 걸리지 않으며 브라우저를 통한 수동 모드에서는 하루 이상이 소요될 수 있습니다.
동시에 URL 자체의 분석은 몇 번의 클릭만으로 이루어지며 Excel의 편리한 형식으로 확인의 주요 특성을 포함하여 보고서를 다운로드할 수 있습니다.
시작하기 위해 필요한 것은 API 키를 얻는 것입니다.
이 작업을 수행하는 방법은 이 문서에 설명되어 있습니다. >>
4. 폴더별로 프로젝트를 그룹화하는 기능이 추가되었습니다.
프로젝트 목록을 보다 편리하게 탐색할 수 있도록 폴더별로 사이트를 그룹화하는 기능이 추가되었습니다.

또한 이름별로 프로젝트 목록을 필터링할 수 있게 되었습니다.
5. 프로그램 설정의 인터페이스가 업데이트되었습니다.
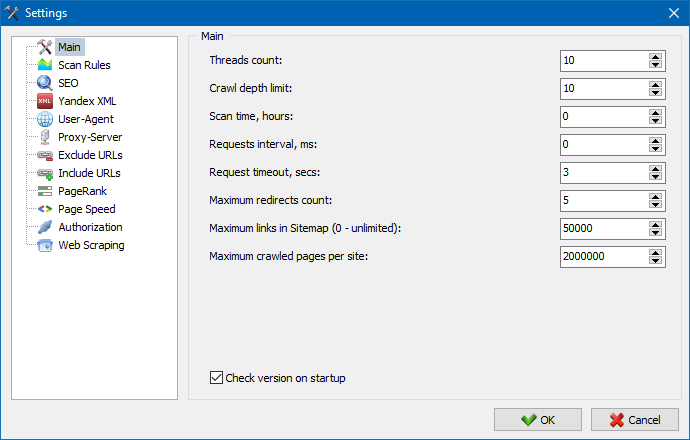
프로그램의 기능이 확장되면서 탭을 사용하는 것이 "빡빡"하게 되었기 때문에 설정 창을 더 이해하기 쉽고 기능적인 인터페이스로 다시 포맷했습니다.
Notes:
- URL 예외의 잘못된 계정 수정
- 사이트 크롤링 깊이에 대한 잘못된 계산 수정
- 파일에서 가져온 URL에 대한 리디렉션 표시 복원
- 탭의 열 순서를 재정렬하고 기억하는 기능을 복원했습니다.
- 비표준 페이지의 계정 복원, 빈 메타 태그 문제 해결
- 정보 탭에서 링크 앵커 표시 복원
- 클립보드에서 많은 수의 URL을 빠르게 가져오기
- 제목 및 설명의 구문 분석이 항상 올바른 것은 아닙니다.
- 이미지의 Alt 및 제목 표시 복원
- 프로젝트를 스캔하는 동안 "외부 링크" 탭으로 전환할 때 고정 고정
- 프로젝트 간 전환 및 "사이트 크롤링 통계" 탭의 노드 업데이트 시 발생하는 오류 수정
- 매개변수가 있는 URL에 대한 중첩 수준의 잘못된 정의 수정
- 기본 테이블의 HTML-해시 필드에 의한 고정 데이터 정렬
- 키릴 자모 도메인으로 프로그램의 최적화된 작업
- 업데이트된 프로그램 설정 인터페이스
- 업데이트된 로고 디자인


Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
이전 버전의 개요:


















