





















プログラムの目的
のプログラムSiteAnalyzerであり、分析に当ウェブサイトの特定の技術的誤差の検索のためのリンク切れの複製ページでは、誤ったサーバの応答やり、誤記や脱字の点にSEO(空白のメタタグは、超過または全くないのページの見出しのh1、分析のページの内容は、品質のリンク、その他多くのSEOパラメータ)です。

主な特徴
- スキャンすべてのページなどの画像スクリプトおよび文書
- ってサーバの応答コード毎に該当するウェブサイトからの(200, 301, 302, 404, 500, 503 等)
- 決定の存在とコンテンツのタイトル、キーワード、説明、H1-H6
- 検索-表示の"複製"のページに、メタタグとヘッダー
- 決定に存在rel="標準"の各ページのサイト
- ファイル "robots.txt"、メタタグ "robots"、またはX-Robots-Tagの指示に従います。
- サイトのページをクロールするときの "noindex"と "nofollow"の計算
- XPath、CSS、XQuery、RegExを使用したデータのスクレイピング
- サイト内のコンテンツの一意性を確認する
- GooglePageSpeedによるページ読み込み速度の確認
- 参照分析:サイトの任意のページに対する内部リンクと外部リンクの定義
- サイトの各ページの内部PageRankの計算
- グラフ上のサイトの構造の視覚化
- ページからのリダイレクト数の決定(リダイレクト)
- 任意のURLと外部のSitemap.xmlをスキャンする
- サイトマップ "sitemap.xml"の生成(いくつかのファイルに分割される可能性があります)
- 任意のパラメータによるデータのフィルタリング(任意の複雑さのフィルタの柔軟な設定)
- サイト上の任意のコンテンツを検索する
- 輸出の報告CSV、Excel、PDF
とは異なり類似
- 低要件へのコンピュータ資源、低消費量のRAM
- スキャンのサイトは、どんなサイズの減少による要件へのコンピュータ資源
- 携帯フォーマット(作業なしで設置のパソコンから直接リムーバブルメディア)
の書類
- 作品の冒頭に
- のプログラムの設定
- 基本設定
- スキャン
- SEO
- Virtual Robots.txt new
- Yandex XML
- ユーザーエージェント
- 任意のHTTPヘッダー new
- プロキシサーバー
- 除外URL
- URLをフォロー
- PageRank
- 承認
- 仕事のプログラム
- 世代Sitemap.xml
- 走査任意のURL
- Dashboard
- 輸出データ
- 多言語
- データベース圧縮
作品の冒頭に
起動する場合は、プログラムのユーザーのアドレスバーへのURLを入力し、その分析のためのサイト(入力できペットの検索ロボットのリンクの最初のページのサイトのホームページでは、すべてのリンクはHTML、Javascript)です。
を押した後の"Start"ボタンを押すと、検索エンジンを開始するクロールのすべてのページ内リンク(外部リソースになるのではない、または請求されませんを使ってことになります。
一度ロボットをバイパスすべてのページをご利用になるとの報告がなされる形のテーブルの表示、受信したデータグループ統一テーマ別のタブです。
すべての分析プロジェクト左に示すようなプログラムの一部を自動的に保存されるデータベースと一緒に受信したデータです。 削除するサイトのコンテキストメニューのプロジェクトリストです。
注意:
- をクリックすると、次のように、ボタンが"一時停止"のスキャニングプロジェクトの停止並行して現在の進捗をスキャン、データベースに登録しておきの例であり、プログラムを継続スキャニングプロジェクト後のプログラムを再起動します。
- "停止"ボタンに割り込みを行うスキャンのプロジェクトの可能性の継続スキャン
のプログラムの設定
メインメニュー"設定"ファインチューニングプログラムの外部サイトを含む7つのタブ:

の主な設定を指定するために使用するユーザのディレクティブが使用するスキャンするときにwebサイトです。
パラメータの説明:
- スレッドの数
- によりスレッドの数、URLできる処理単位時間当たります。 このスレッドが、より多くの資源の使用をコントロールします。 設定することをお勧めしますスレッドの数の範囲が5-10ます。
- スキャン時間
- 設定に使用する限定の走査サイトの時です。 で測定する時間です。
- 最大深さ
- このパラメータを指定するために使用するの深さスキャンのサイトです。 ホームページのウェブサイトでは、ネスレベル=0になります。 例えば、必要なものをスキャンし、ページ種別"somedomain.ru/catalog.html"somedomain.ru/catalog/tovar.html"この場合、して設定しなければなりませんの最大深度=2のとします。
- 間の遅延を要求
- 設定すると一時停止のスキャナーのページです。 この有サイト"弱い"ホストにない耐荷重が頻繁に訴える。
- タイムアウトの依頼
- 設定タイムアウトの対応がウェブサイトから要求プログラムです。 このページに対応でゆっくり(貨物)の走査サイトが非常に長い時間です。 これらのページでカットすることが可能です値を設定した後、スキャナをスキャンのその他のページのサイトは、このような遅延、全体の進捗します。
- のバーコードリーダモードのページ
- 制限の最大ページ数をスキャンします。 でなければならないときに便利で、例えば、スキャンNサイトのページでは画像、スタイルシート、スクリプト、その他の種類のファイル)です。

を考慮して、コンテンツ
- ここをクリックして選択するデータの種類に行われる予定であるパーサを横断ページ(画像、動画、イタリアで作られ、スクリプト)、無駄な情報が構文解析します。
スルール
- これらの設定に関する設定の場合には、例外クロールのり付けることにより、簡単にファイルのスキャナー"robots.txt"リンク型の"つやものを使用する指令"のmeta name=ロボット"直接コードページです。

ここで指定します基本的な分析SEO要因は、今後ますの正しさのチェックを行う構文解析時にページが、その後、結果の統計に表示されるので、タブの"SEO統計"の右側のウィンドウに表示します。
これらの設定の助けを借りて、検索エンジンYandexのページの索引付けをチェックするサービスを選択することができます。インデックス作成のチェックには、Yandex XMLサービスまたはMajento.ruサービスを使用する2つのオプションがあります。

Yandex XMLサービスを選択する際には、ページのインデックスを確認したり、Yandexアカウントの既存の制限に関する適用可能な制限(1時間ごとまたは毎日)を考慮する必要があります。その結果、アカウントの制限ですべてを確認できない場合がありますページを一度に表示することができます。このためには、次の1時間を待たなければなりません。
Majento.ruサービスを使用する場合、時間制限や日々の制限は事実上存在しません。これは、制限が文字通り制限の一般的なプールにマージされるためです。Yandex XMLの個々のユーザーアカウントの制限よりも、。

サイトでホストされている実際のrobots.txtの代わりに、仮想robots.txtを使用できます。
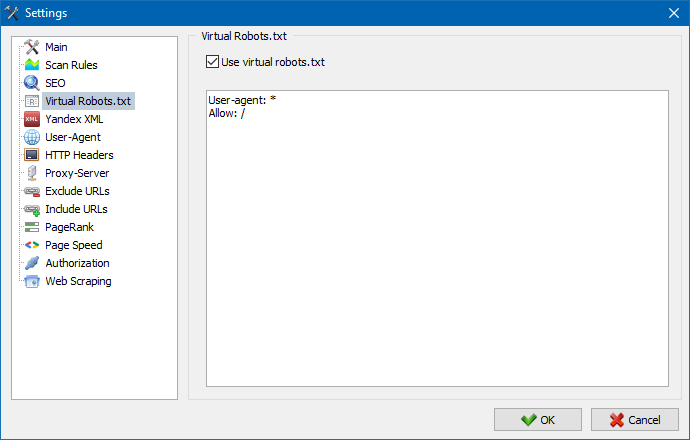
これは、サイトをテストするときに役立ちます。たとえば、サイトの特定のセクションをクロールする必要があり、物理的に作成する必要はありませんが、その逆の場合は、クロール時にそれらを考慮しないでください。実際のrobots.txtに変更を加え、開発者の時間をこれに費やします。
注:URLのリストをインポートする場合、仮想robots.txtのディレクティブが考慮されます(このオプションが有効になっている場合)。それ以外の場合、URLのリストにrobots.txtは考慮されません。
のユーザーエージェントを指定できるかユーザーエージェントが提出されたプログラムの場合、アクセス外部サイト中のスキャンします。 デフォルトで設定したカスタムユーザーエージェントが必要な場合はお選び頂くことが可能ですの標準薬剤で最も頻繁に遭遇するインターネットです。 その中などボットの検索エンジンYandexBotは、GoogleBotは、MicrosoftEdgeは、ボットブラウザChrome、Firefox、IE8では、モバイル機器やiPhone、Android、およびその他多数です。

このオプションを使用すると、さまざまなリクエストに対するサイトとページの反応を分析できます。たとえば、誰かがリクエストでリファラーを送信する必要があり、多言語サイトの所有者がAccept-Language | Charset | Encodingを送信したい場合、誰かがAccept-Encoding、Cache-Control、Pragmaヘッダーで異常なデータを送信する必要がある場合があります。 、など。NS。
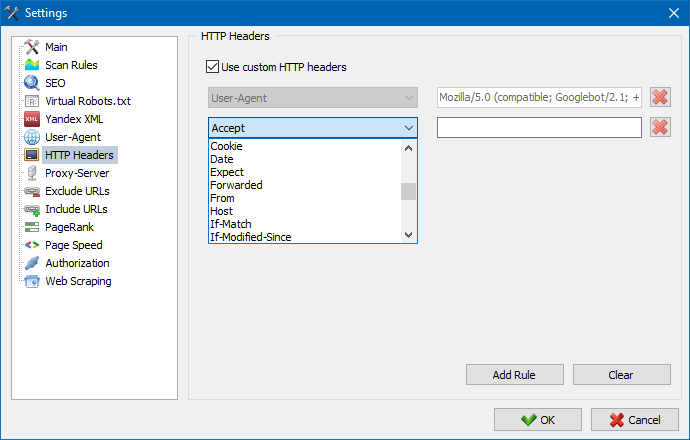
このオプションを使用すると、さまざまなリクエストに対するサイトとページの反応を分析できます。たとえば、誰かがリクエストでリファラーを送信する必要があり、多言語サイトの所有者がAccept-Language | Charset | Encodingを送信したい場合、誰かがAccept-Encoding、Cache-Control、Pragmaヘッダーで異常なデータを送信する必要がある場合があります。 、など。NS。
る必要がある場合には仕事を通じてプロキシでは、このページに追加することができますリストのプロキシサーバーを通してのプログラムにアクセス外部リソースです。 また、可能性があるチェックプロキシファイアーパフォーマンスの経験や除去は不活性プロキシサーバーです。

このことを目的として除外するバイパスでは、一部のページで、次の各号に掲げる区分のサイトが構文解析します。
検索パターンの使用*および? クローラーがサイトのどのセクションをクロールしないのかを指定できます。したがって、プログラムデータベースに含めることはできません。 このリストは地域のリスト例外時の走査サイトの(相対的に"グローバルな"リストファイル"robots.txt"の根底には、ウェブサイト)です。

同様に、クロールする必要があるURLを追加できます。 この場合、これらのフォルダー以外のURLはすべてスキャン中に無視されます。 このオプションは検索パターンでも機能します*および?

PageRankパラメータを使用すると、あなたのサイトのナビゲーション構造を分析したり、最も重要なページに参照の重みを伝達するためにWebリソースの内部リンクのシステムを最適化することができます。

プログラムはPageRankを計算するための2つのオプションを持っています:古典的なアルゴリズムとそのより現代的な対応物です。一般に、サイトの内部リンクの分析には、最初のアルゴリズムと2番目のアルゴリズムを使用しても大きな違いはありません。したがって、2つのアルゴリズムのどちらでも使用できます。
アルゴリズムとPageRankの計算原理の詳細な説明は、記事「内部PageRankの計算」にあります。 >>

.htpasswdを介して閉じられ、BASICサーバー認証によって保護されているページでの自動認証のためのログインとパスワードを入力します。
仕事のプログラム
後にスキャンが完了する情報に含まれるブロック"マスターデータ"です。 それぞれのタブに含まれるデータをグループ分けについて自分の名前(たとえば、タブタイトルが含まれますの内容のページのヘッダ<title></title>のタブ""画像の一覧が表示されている全ての画像からのサイトです。 このデータ解析を行う事ができ、本ウェブサイトのコンテンツ、"壊れた"リンクまたは不完全なメタタグです。

必要な場合(例えば、後の変更は、サイトのコンテキストメニューの可能性がありますので、新しいスキャンの個別のURLに変更は反映され、プログラムです。
このメニューを表示することができます重複したページに関連するパラメータ(doubleをタイトル、概要、キーワードに、h1、h2、コンテンツページ)です。

「コード0でURLを再スキャン」という項目は、応答コード0(読み取りタイムアウト)を返すすべてのページを自動的に再確認するように設計されています。 この応答コードは通常、サーバーにコンテンツを配信する時間がなく、接続がタイムアウトによってそれぞれ閉じられ、ページをロードできず、ページから情報を抽出できない場合に返されます。
では、今までの選択タブに表示されたインタフェースマスターデータ(最後にすることが可能になった"など少ない文字入力で長い文章の古いタブのMetaキーワードです) この時に役立つタブがない場合は、画面のごく稀にします。

列もできる隠れた希望の場所をドラッグ.
表示タブやカラムの機能を使って設定されますのでコンテキストメニュー、ツールバーのマスターデータです。 の移動のカラムによって行となります。
簡単に分析のサイトの統計、プログラムがデータをフィルターです。 フィルタリングが可能な二つの異:
- 他分野のクイックフィルター
- カスタムフィルターを使用して詳細設定のサンプルデータ)
迅速にフィルター
パッケージのデータをフィルタリングが同時にすべての分野において、現在のタブがあります。

カスタムフィルター
設計のための豊富なフィルタリングを含むことはでき複数の条件です。 たとえば、データベースのようなデータの"title"したいタグをフィルターのページによる長さでを超えないもので70文字も含まれるテキスト"ニュース"です。 このフィルターのようになります:

このように、カスタムフィルターを他のタブを得ることができサンプリングデータの複雑さです。
サイトの[技術統計]タブは[追加データ]パネルにあり、リンクに関する統計、メタタグ、ページレスポンスコード、ページインデックスパラメータ、コンテンツタイプなど、基本的なサイトの技術パラメータのセットが含まれています。パラメータ
パラメータの1つをクリックすると、それらはサイトマスタデータの対応するタブで自動的にフィルタ処理され、同時に統計がページ下部の図に表示されます。

SEO統計タブは、本格的なサイト監査を実施するためのもので、50以上の主なSEOパラメータを含み、60を超える主要な内部最適化エラーを特定します。エラーマッピングはグループに分類され、グループには分析されたパラメータとサイト上のエラーを検出するフィルタのセットが含まれています。
チェックされたすべてのパラメータの詳細な説明はこの記事にあります。 >>

すべてのフィルタリング結果について、追加のダイアログなしでそれらを素早くExcelにエクスポートすることが可能です(レポートはプログラムフォルダに保存されます)。
このタブは設定フィックスをチェックするだけサンプルすべての外部リンク先が404エラー、画像、その他のパラメータのすべてのページにとらえられた。 そこで、簡単に素早くリストを取得するには外部リンクページに位置するものであり、すべて選択リンク切れのページもあります。

すべての報告書のプログラム、オンラインに表示されている"カスタムタブの主要パネルデータです。 また、可能性があるのExcelを使用してメインメニューを開きます。
サイトコンテンツ検索機能を使用すると、ソースコードを検索して、探しているコンテンツを含むWebページを表示できます。
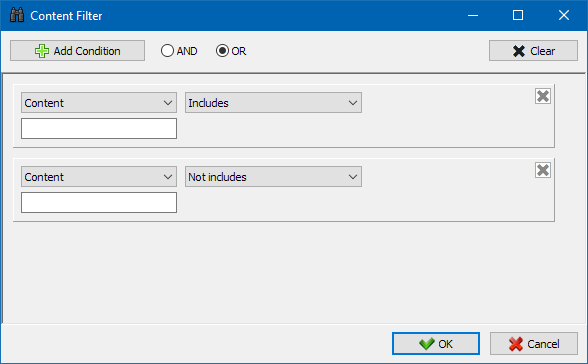
カスタムフィルターモジュールを使用すると、マイクロマークアップ、メタタグ、分析システム、サイトのフリーテキストまたはHTMLコードのフラグメントの存在を確認できます。
フィルター構成ウィンドウには、サイトページのテキストの特定のフラグメントを検索するためのパラメーターがいくつかあります。逆に、特定のテキストまたはHTMLコードフラグメントを含むページを検索結果から除外するためのパラメーターがあります(この機能は、Ctrl-Fを使用してページのソースコード内のコンテンツを検索するのと似ています) ...
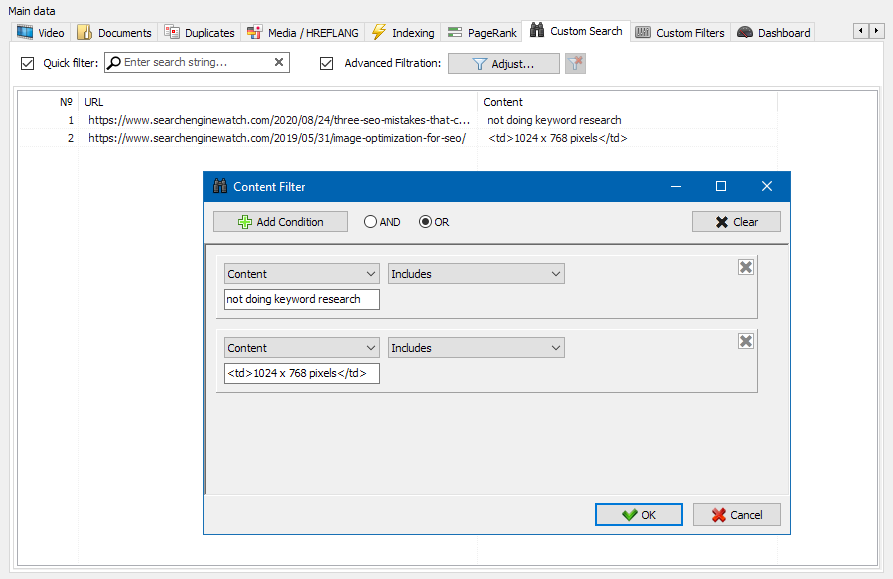
通常、スクレーピングは、手動で処理するのが難しいタスクを解決するために使用されます。これは、製品の説明を抽出して新しいオンラインストアを作成したり、マーケティングリサーチをスクレイピングして価格を監視したり、広告を監視したりする場合があります。

SiteAnalyzerでは、スクレイピングは抽出ルールが構成されている[データ抽出]タブで構成されます。ルールは保存でき、必要に応じて編集できます。
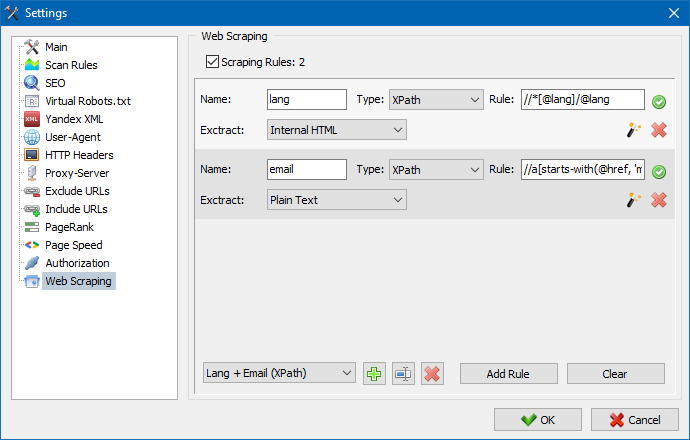
ルールテストモジュールもあります。組み込みのルールデバッガーを使用すると、サイト上の任意のページのHTMLコンテンツをすばやく簡単に取得してクエリの動作をテストし、デバッグされたルールを使用してSiteAnalyzerでデータを解析できます。

データの抽出が完了すると、収集されたすべての情報をExcelにエクスポートできます。
モジュールの操作の詳細と、最も一般的なルールと正規表現のリストについては
このツールを使用すると、重複するページを検索し、サイト内のテキストの一意性を確認できます。つまり、これはURLのグループの一意性をバッチチェックするものです。
これは、次の場合に役立ちます。
- 完全に重複するページを検索します(たとえば、パラメーターがあり、同じページであるが、CNCビューにあるページ)。
- 部分的なコンテンツの一致を検索するには(たとえば、料理ブログの2つのボルシチレシピは互いに96%類似しており、トラフィックの共食いの可能性を取り除くために記事の1つを削除する必要があることを示唆しています)。
- 記事サイトで、10年前にすでに書いたトピックに関する記事を誤って書いたとき。この場合、私たちのツールはそのような記事の重複も検出します。
コンテンツの一意性をチェックするためのツールの原理は単純です。プログラムはWebサイトのURLのリストからコンテンツをダウンロードし、ページのテキストコンテンツ(HEADブロックなしおよびHTMLタグなし)を受信して、それぞれと比較します。その他は、シングルアルゴリズムを使用します。

したがって、帯状疱疹を使用して、ページの一意性を判断し、0%の一意性を持つページの完全な複製と、テキストコンテンツのさまざまな程度の一意性を持つ部分的な複製の両方を計算できます。プログラムは、シングルの長さが5で動作します。
この記事で、モジュールがどのように機能するかについて詳しく知ることができます。: >>
Google検索の巨人のPageSpeedInsightsツールを使用すると、特定のページ要素の読み込み速度を確認できます。また、デスクトップバージョンとモバイルバージョンのブラウザの対象URLの全体的な読み込み速度スコアも表示されます。

Googleのツールはすべての人に適していますが、1つの大きな欠点があります。グループURLチェックを作成できないため、サイトの多くのページをチェックするときに不便になります。100以上のURLのダウンロード速度を手動でチェックすることに同意してください。 1ページは雑用であり、多くの時間がかかる場合があります。
そのため、Google PageSpeed Insightsツールの特別なAPIを使用して、ページの読み込み速度のグループチェックを無料で作成できるモジュールを作成しました。

主な分析パラメータ:
- FCP (First Contentful Paint) – 最初のコンテンツを表示する時間。
- SI (Speed Index) – コンテンツがページに表示される速さの指標。
- LCP (Largest Contentful Paint) – ページ上の最大の要素の表示時間。
- TTI (Time to Interactive) – ページがユーザーとの対話の準備が完全に整うまでの時間。
- TBT (Total Blocking Time) – コンテンツの最初のレンダリングからユーザーインタラクションの準備ができるまでの時間。
- CLS (Cumulative Layout Shift) – 累積レイアウトシフト。ページの視覚的な安定性を測定するのに役立ちます。
同時に、URL自体の分析は数回クリックするだけで実行され、その後、Excelの便利な形式のチェックの主な特徴を含むレポートをダウンロードできます。
始めるために必要なのは、APIキーを取得することだけです。
これを行う方法は、この記事で説明されています。 >>
この機能はオブジェクトのスタイルの構造に基づくデータが得られます。 当サイトの構造から生成されるネストしたURLに対するものとなります。 生成後に、その輸出をCSV形式(Excel)です。

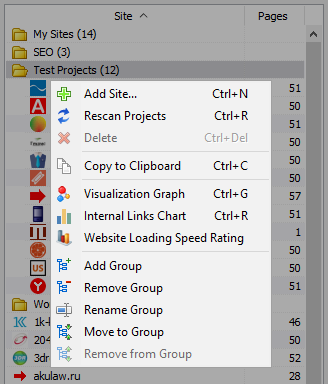
- のプロジェクトのリストは利用量スキャンを選択し、ご希望のサイトをクリックし"を再スキャン"です。 その後、すべてのサイトは、スキャンを交互に標準モードになります。
- また、の便宜のためのプログラムは、大量-削除を選択したサイトにもご利用いただけますので"削除"ボタンを押します。
- のほか、シングルスキャンのサイトは、それよりもバルクサイトの追加のプロジェクトのリストは、専用のフォーマットでは、ユーザスキャンの興味深いプロジェクト全体ます。
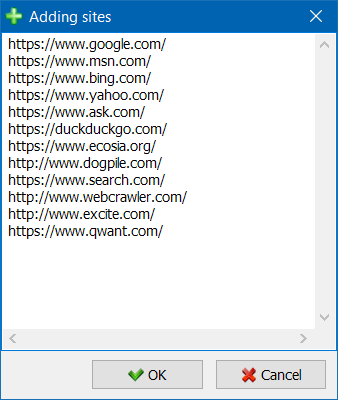
- プロジェクトのリストをより便利にナビゲートするために、サイトをフォルダーでグループ化したり、プロジェクトのリストを名前でフィルターしたりすることができます。

描画モードを参照接続をグラフにすると、SEO専門評価分布のPageRankは内部のページのサイトを理解するページのリンク重量(およびそのため、内部リンクのジュースの検索エンジンは、何ページに、次の各号に掲げる区分については、さまざまな要素により十分な内部リンクになります。

の描画モード構造のサイトのSEO専門できるかどうかを評価組織内リンクのサイトを通じて、視覚表現のPageRank量を割り当て、特定のページを迅速に調整、現在のリンクサイトを増やの関連性のです。
左部の可視化ウィンドウの作のためのツールは、グラフ:
- ズームのグラフ
- 右のグラフを任意の角度
- 切り替え、グラフウィンド全画面モードでも動作を押しF11)
- 表示/非表示ラベルをノード (Ctrl-T)
- 表示/非、矢印の線
- 表示-非表示を切り替える外部リンク (Ctrl-E)
- 切り替え、色彩の日/夜間 (Ctrl-D)
- 表示/非伝説のグラフの統計 (Ctrl-L)
- 保存グラフをPNG形式 (Ctrl-S)
- 画面設定可視化 (Ctrl-O)
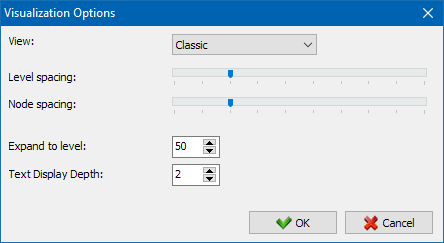
の"外観"に変更し表示フォーマットのノードのグラフで表示します。 に描画モードノード"PageRank"のノードのサイズとの対比で従来の計算指標のPageRankは、グラフの中にはっきりと見えるページよりリンクのジュースなどが以下のリンクです。
クラシックモード、ノードのサイズに対応した規模でのグラフを可視化する。
このグラフは、サイトページ上の内部リンクの質量の分布を示しています(これは、視覚化グラフに表示されているのではなく、視覚的な形式でのリンクの視覚化であると言えます)。 もっと読む >>
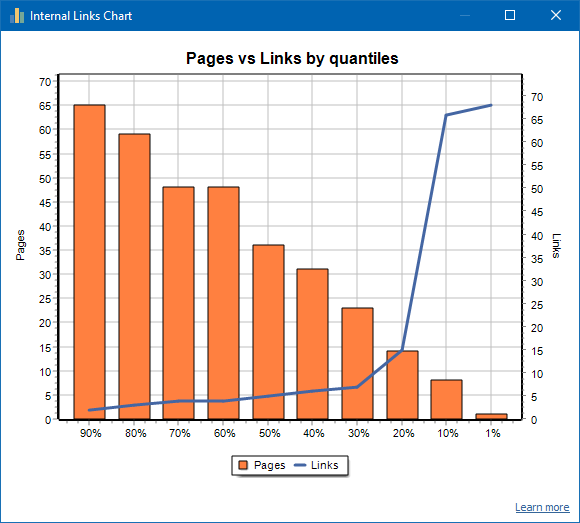
左側はページ数、右側はリンク数です。以下は、ページごとのパーセンタイルのパーセンテージです。グラフを作成するとき、重複するリンクは破棄されます(ページAからページBへのリンクが3つある場合、それらは1つとしてカウントされます)。
たとえば、上のスクリーンショットに基づいて、約70ページのサイトの場合:
- 1% ページに ~68 着信リンク.
- 10% ページに ~66 着信リンク.
- 20% ページに ~15 着信リンク.
- 30% ページに ~8 着信リンク.
- 40% ページに ~7 着信リンク.
- 50% ページに ~6 着信リンク.
- 60% ページに ~5 着信リンク.
- 70% ページに ~5 着信リンク.
- 80% ページに ~3 着信リンク.
- 90% ページに ~2 着信リンク.
つまり、10未満の着信リンクがつながるページがある場合、そのようなページは弱くリンクされていると見なすことができ、通常リンクされているページの60%があります。これに基づいて、これらの弱くリンクされたページへの内部リンクを増やす(ページがプロモーションにとって重要である場合)か、またはそのようなページの重要度が低く優先度が低い場合はそのままにすることができます。
一般的に、内部リンクが10未満のページは、検索エンジン、特にGoogleボットによってクロールされる可能性が低くなります。
したがって、サイトの合計ページ数から通常リンクされているページが20〜30%しかないサイトを見つけた場合は、リンク設定を詳しく調べるか、弱くリンクされたこれらのページの80〜70%に対処する方法(削除、非表示)を検討することをお勧めします。インデックス作成、リダイレクトを配置します)。
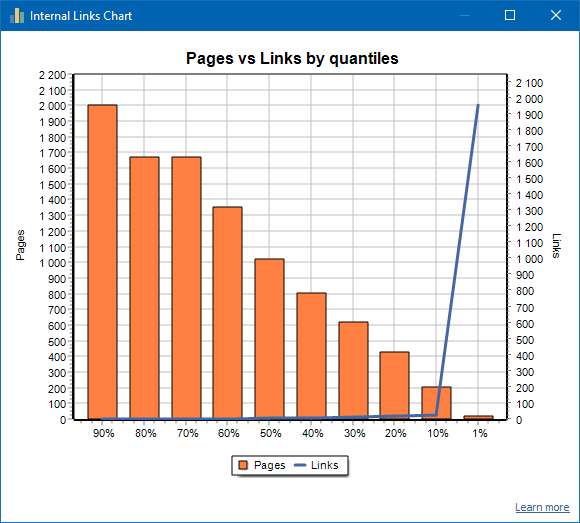
弱くリンクされたサイトの例:
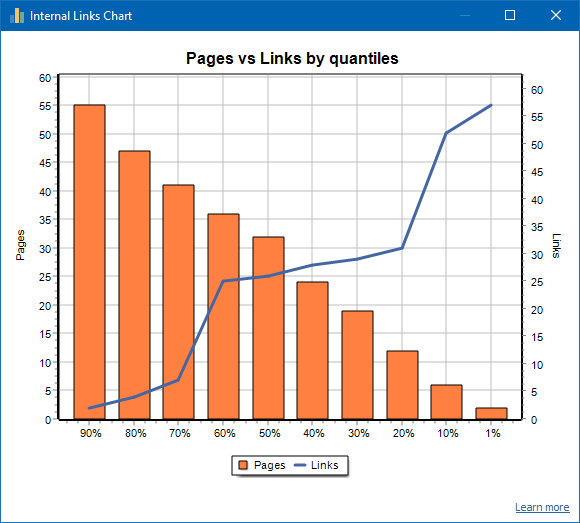
よくリンクされたサイトの例:
ページの読み込み速度のグラフを使用すると、サイトのパフォーマンスを評価できます。わかりやすくするために、ページは100ミリ秒単位でグループと時間間隔に分割されています。
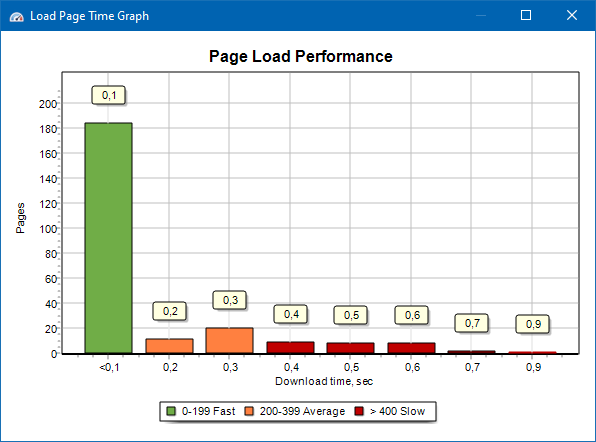
したがって、グラフに基づいて、サイトページのどの割合がすばやく(0〜100ミリ秒以内に)読み込まれ、どの割合が平均速度(100〜200ミリ秒)で、どのページが十分に長く読み込まれるか(400ミリ秒以上)を判断できます。
注:表示されている時間は、HTMLソースコードをロードする時間であり、ページを完全にロードする時間ではありません(ページのレンダリング、および画像やスタイルなどのページ要素のロードは考慮されていません)。
世代Sitemap.xml
サイトマップは、クロールされたページまたはサイトイメージに基づいて生成されます。
- ページで構成されるサイトマップを生成すると、「text / html」形式のページが追加されます。
- 画像で構成されるサイトマップを生成すると、JPG、PNG、GIFなどの画像が追加されます。
を生成する地図サイトの直後の走査サイトのメインメニュー項目"プロジェクトにつき)->の生成サイトマップ"です。

サイトとの大量50,000ページに自動分割"sitemap.xml"複数のファイル(この場合、ファイルへのリンクが含まれて追加の含有が直接ページへのリンクサイト)です。 これにより、安定した要件の検索エンジンの処理にSitemapsの大きな寸法です。

必要な場合は、金額のページのファイル"sitemap.xml"可変にすることでより価値の50 000(デフォルトの値は本プログラムを設定します。
走査任意のURL
のメニュー項目の"インポートURL"は任意のスキャンリストの行動履歴(アクセスしたURL、XML Sitemaps Sitemap.xml を含む指数)のための分析.
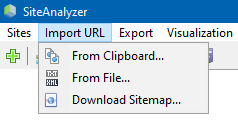
スキャンカスタムのURLは次の
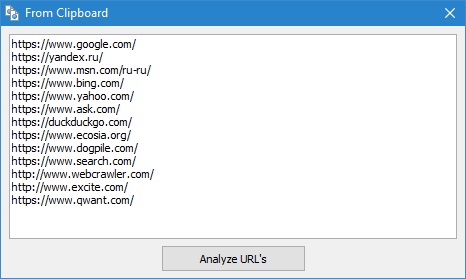
- 差し込むURLのリストからのクリップボード
- 起動からハードディスクファイル形式*.txt、*.xml、上場URL
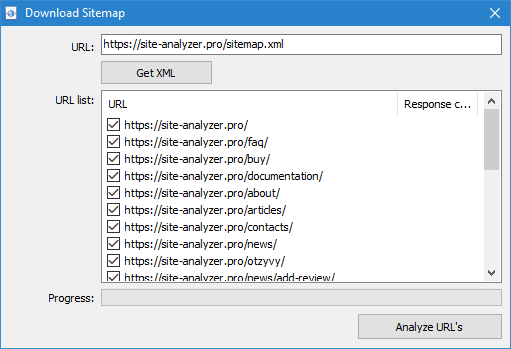
- によるこのファイルをダウンロードSitemap.xml から直接サイト
特徴のこのモードでスキャンす任意のURLのプロジェクト"に保存されていないプログラムやデータに付加されていないデータベースです。 もご利用いただけませんの部"構造"及び"ダッシュボード".
詳細についてのインポート]を選択しURLの"この条: 概要新しいバージョン SiteAnalyzer 1.9.
Dashboard
ダッシュボードをタブ表示の詳細な報告書は、現在の品質のウェブサイトの最適化します。 報告書の生成に基づくデータをタブの"SEO統計"です。 ほか、これらのデータの報告書を含むの合計品質インデックスのウェブサイトの最適化し、算出した100点の対比では、現在の最適化します。 エクスポート処理が可能でのデータをタブの"ダッシュボード"が便利なPDFを報告します。

輸出データ
より柔軟な解析のデータをダウンロードCSV形式(輸出される現在のアクティブなタブ)を完全に報告されたMicrosoft Excelの全てのタブを一つのファイルです。

輸出時における優れたプロフェッショナルがウィンドウは、ユーザが選択でき、ご希望のカラムを生成する報告書をもとに、ご希望のデータです。

多言語
のプログラムのオプションを選択する優先言語る。
主な対応言語:ロシア語、英語、ドイツ語、イタリア語、スペイン語、フランス---のようで、ソフトウェア翻訳されている以上15人気の言語です。

したい場合は翻訳のプログラムへの母国語で翻訳ファイルには"*.lng"の言語に翻訳ファイルに送る必要があります。アドレス"support@site-analyzer.pro"のコメント文字のいずれかで記述しなければなロシア語または英語と翻訳が含まれの新しいリリースのプログラムです。
具体的な使用方法については、翻訳文の言語での配布ファイル("lcids.txt"という。
P.S.本サイトに関するご意見、質の翻訳-送信コメントを修正する"support@site-analyzer.ru"です。
データベース圧縮
メインメニュー項目に"収縮のデータベースがありますので、操作の商品については、パッケージをデータベース(クリーニングデータベースから削除プロジェクトをデータと同様のdefragmentationのデータをパソコンなし)ます。
この手続きは有効な場合には、例えば、プログラムから削除された大規模なプロジェクトを含む多数の記録です。 ついては、一般的に推奨を定期的に圧縮データのう冗長データのサイズを縮小し、データベースです。
の回答、その他のご質問をFAQ >>



















