





















 3,170
3,170Ciao a tutti! Siamo tornati in affari!
Dopo un periodo molto lungo, abbiamo finalmente preparato una nuova versione di SiteAnalyzer, che, speriamo, soddisferà le tue aspettative e diventerà un assistente indispensabile nella promozione SEO.
Nella nuova versione di SiteAnalyzer, abbiamo implementato alcune delle funzioni più richieste dagli utenti, come: data scraping (estrazione di dati dal sito), verifica dell'unicità dei contenuti e verifica della velocità di caricamento della pagina da parte di Google PageSpeed. Allo stesso tempo, sono stati corretti molti bug e il logo è stato rinnovato. Parliamo di tutto in modo più dettagliato.

Le principali modifiche
1. Raschiare i dati con XPath, CSS, XQuery, RegEx.
Il web scraping è un processo automatizzato di estrazione dei dati dalle pagine di interesse del sito secondo determinate regole.
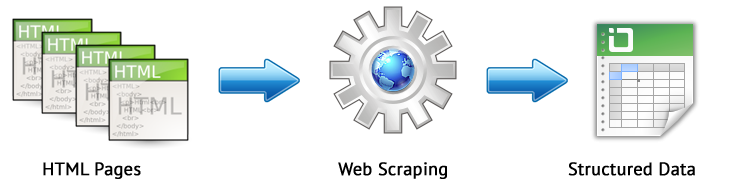
I principali metodi di web scraping sono metodi di analisi che utilizzano XPath, selettori CSS, XQuery, RegExp e modelli HTML.
- XPath è un linguaggio di query speciale per elementi di documenti XML/XHTML. Per accedere agli elementi, XPath utilizza la navigazione DOM descrivendo il percorso dell'elemento desiderato nella pagina. Con il suo aiuto, puoi ottenere il valore di un elemento in base al suo numero ordinale nel documento, estrarne il contenuto testuale o il codice interno, verificare la presenza di un elemento specifico nella pagina.
- I selettori CSS sono usati per trovare un elemento della sua parte (attributo). CSS è sintatticamente simile a XPath, ma in alcuni casi i localizzatori CSS sono più veloci e sono più descrittivi e concisi. Lo svantaggio di CSS è che funziona solo in una direzione, più in profondità nel documento. XPath, d'altra parte, funziona in entrambi i modi (ad esempio, puoi cercare un elemento padre da un figlio).
- XQuery è basato su XPath. XQuery imita XML, che consente di creare espressioni nidificate in un modo che non è possibile in XSLT.
- RegExp è un linguaggio di ricerca formale per estrarre valori da un insieme di stringhe di testo che corrispondono alle condizioni richieste (espressione regolare).
- I modelli HTML è un linguaggio per l'estrazione di dati da documenti HTML, che è una combinazione di markup HTML per descrivere il modello di ricerca per il frammento desiderato, oltre a funzioni e operazioni per l'estrazione e la trasformazione dei dati.
In genere, lo scraping viene utilizzato per risolvere attività difficili da gestire manualmente. Questo può essere l'estrazione delle descrizioni dei prodotti per creare un nuovo negozio online, il raschiamento nelle ricerche di mercato per monitorare i prezzi o per monitorare gli annunci.

In SiteAnalyzer, lo scraping è configurato nella scheda Estrazione dati, dove sono configurate le regole di estrazione. Le regole possono essere salvate e, se necessario, modificate.
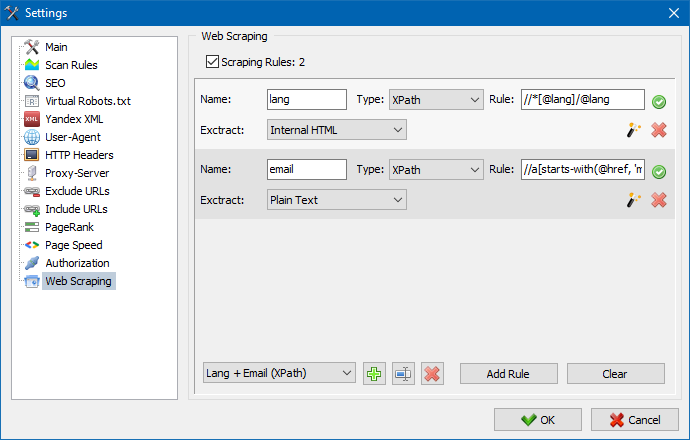
C'è anche un modulo di test delle regole. Utilizzando il debugger di regole integrato, puoi ottenere rapidamente e facilmente il contenuto HTML di qualsiasi pagina del sito e testare il lavoro delle query, quindi utilizzare le regole di debug per l'analisi dei dati in SiteAnalyzer.

Dopo aver terminato l'estrazione dei dati, tutte le informazioni raccolte possono essere esportate in Excel.
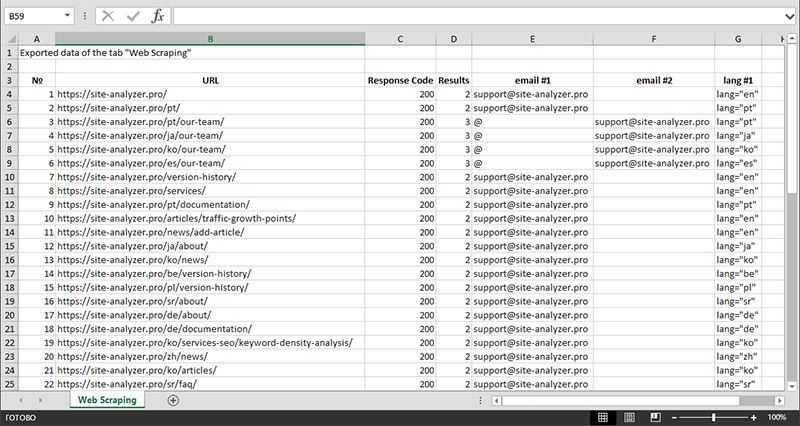
Per uno studio più dettagliato del funzionamento del modulo e un elenco delle regole e delle espressioni regolari più comuni, consultare l'articolo
2. Verifica dell'unicità dei contenuti all'interno del sito.
Questo strumento permette di cercare pagine duplicate e verificare l'unicità dei testi all'interno del sito. In altre parole, questo è un controllo batch di un gruppo di URL per verificarne l'unicità.
Questo può essere utile nei casi:
- Per cercare pagine duplicate complete (ad esempio, una pagina con parametri e la stessa pagina, ma nella vista del CNC).
- Per cercare corrispondenze parziali di contenuto (ad esempio, due ricette di borscht in un blog culinario, che sono simili al 96% tra loro, il che suggerisce che uno degli articoli dovrebbe essere eliminato per eliminare la possibile cannibalizzazione del traffico).
- Quando su un sito di articoli hai scritto accidentalmente un articolo su un argomento che hai già scritto 10 anni fa. In questo caso, il nostro strumento rileverà anche un duplicato di tale articolo.
Il principio dello strumento per verificare l'unicità dei contenuti è semplice: il programma scarica il loro contenuto dall'elenco degli URL del sito Web, riceve il contenuto testuale della pagina (senza il blocco HEAD e senza tag HTML), quindi li confronta con ciascuno altro utilizzando l'algoritmo shingle.

Pertanto, utilizzando l'herpes zoster, determiniamo l'unicità delle pagine e possiamo calcolare sia i duplicati completi di pagine con lo 0% di unicità, sia i duplicati parziali con vari gradi di unicità del contenuto del testo. Il programma funziona con una lunghezza di scandole di 5.
Puoi saperne di più su come funziona il modulo in questo articolo.: >>
3. Controllo della velocità di caricamento delle pagine da parte di Google PageSpeed.
Lo strumento PageSpeed Insights del gigante della ricerca di Google ti consente di controllare la velocità di caricamento di determinati elementi della pagina e mostra anche il punteggio complessivo della velocità di caricamento degli URL di interesse per le versioni desktop e mobile del browser.

Lo strumento di Google è buono per tutti, tuttavia, ha uno svantaggio significativo: non ti consente di creare controlli URL di gruppo, il che crea inconvenienti quando controlli molte pagine del tuo sito: accetta di controllare manualmente la velocità di download per 100 o più URL su una pagina è un lavoro ingrato e può richiedere molto tempo.
Pertanto, abbiamo creato un modulo che consente di creare controlli di gruppo della velocità di caricamento della pagina gratuitamente tramite un'API speciale nello strumento Google PageSpeed Insights.

Principali parametri analizzati:
- FCP (First Contentful Paint) – tempo per visualizzare il primo contenuto.
- SI (Speed Index) – un indicatore della velocità con cui il contenuto viene visualizzato su una pagina.
- LCP (Largest Contentful Paint) – tempo di visualizzazione per l'elemento più grande della pagina.
- TTI (Time to Interactive) – il tempo durante il quale la pagina diventa completamente pronta per l'interazione dell'utente.
- TBT (Total Blocking Time) – tempo dal primo rendering del contenuto alla sua disponibilità per l'interazione dell'utente.
- CLS (Cumulative Layout Shift) – spostamento cumulativo del layout. Serve a misurare la stabilità visiva della pagina.
A causa del lavoro multi-thread di SiteAnalyzer, il controllo di centinaia o più URL può richiedere solo pochi minuti, che potrebbero richiedere un giorno o più in modalità manuale tramite un browser.
Allo stesso tempo, l'analisi dell'URL stesso avviene in un paio di clic, dopodiché è possibile scaricare un report, contenente le principali caratteristiche dei controlli in un comodo modulo in Excel.
Tutto ciò che serve per iniziare è ottenere una chiave API.
Come farlo è descritto in questo articolo. >>
4. Aggiunta la possibilità di raggruppare i progetti per cartelle.
Per una navigazione più comoda nell'elenco dei progetti, è stata aggiunta la possibilità di raggruppare i siti per cartelle.

Inoltre, è diventato possibile filtrare l'elenco dei progetti per nome.
5. L'interfaccia delle impostazioni del programma è stata aggiornata.
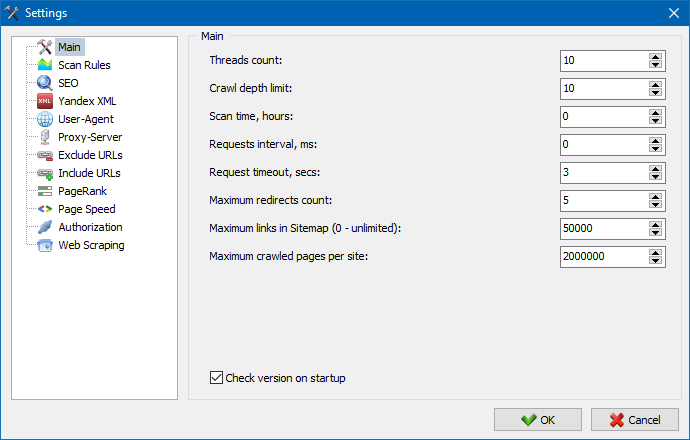
Con l'espansione delle funzionalità del programma, è diventato "stretto" per noi utilizzare le schede, quindi abbiamo riformattato la finestra delle impostazioni in un'interfaccia più comprensibile e funzionale.
Note:
- corretta contabilità errata delle eccezioni URL
- corretta contabilità errata della profondità di scansione del sito
- visualizzazione ripristinata dei reindirizzamenti per gli URL importati da un file
- ripristinata la capacità di riorganizzare e ricordare l'ordine delle colonne nelle schede
- ripristinata la contabilità delle pagine non canoniche, risolto il problema con i meta tag vuoti
- visualizzazione ripristinata degli ancoraggi dei collegamenti nella scheda Informazioni Info
- importazione accelerata di un gran numero di URL dagli appunti
- risolto l'analisi non sempre corretta di titolo e descrizione
- visualizzazione ripristinata di alt e titolo nelle immagini
- risolto il blocco quando si passa alla scheda "Collegamenti esterni" durante la scansione di un progetto
- corretto l'errore che si verificava durante il passaggio da un progetto all'altro e l'aggiornamento dei nodi della scheda "Statistiche di scansione del sito"
- corretta definizione errata del livello di nidificazione per l'URL con parametri
- sistemato l'ordinamento dei dati per campo hash HTML nella tabella principale
- lavoro ottimizzato del programma con domini cirillici
- interfaccia delle impostazioni del programma aggiornata
- design del logo aggiornato

Panoramica delle versioni precedenti:
- Recensione della nuova versione SiteAnalyzer 2.2
- Recensione della nuova versione SiteAnalyzer 2.1
- Recensione della nuova versione SiteAnalyzer 2.0


















