





















 1,456
1,456Ўсім прывітанне! Мы зноў у справе!
Пасля вельмі працяглага перыяду мы, нарэшце, падрыхтавалі новы рэліз SiteAnalyzer, які, спадзяемся, апраўдае вашы чаканні і стане незаменным памочнікам у SEO-прамоцыі.
У новай версіі SiteAnalyzer мы рэалізавалі некалькі з найбольш запатрабаваных карыстальнікамі функцый, такіх, як: скрейпинг дадзеных (выманне дадзеных з сайта), праверка унікальнасці кантэнту і праверка хуткасці загрузкі старонак па Google PageSpeed. Разам з гэтым было зачынена мноства багаў і праведзены рэстайлінг лагатыпа. Раскажам пра ўсё падрабязней.

Асноўныя змены
1. Скрейпинг дадзеных з дапамогай XPath, CSS, XQuery, RegEx.
Вэб-скрейпинг - гэта аўтаматызаваны працэс вымання дадзеных з цікавяць старонак сайта па пэўных правілах.
Асноўнымі спосабамі вэб-скрейпинга з'яўляюцца метады разбору дадзеных выкарыстоўваючы XPath, CSS-селектары, XQuery, RegExp і HTML templates.
- XPath ўяўляе сабой адмысловы мова запытаў да элементаў дакумента фармату XML / XHTML. Для доступу да элементаў XPath выкарыстоўвае навігацыю па DOM шляхам апісання шляху да патрэбнага элемента на старонцы. З яго дапамогай можна атрымаць значэнне элемента па яго парадкаваму нумару ў дакуменце, выняць яго тэкставае змесціва або ўнутраны код, праверыць наяўнасць пэўнага элемента на старонцы.
- CSS-селектары выкарыстоўваюцца для пошуку элемента яго часткі (атрыбут). CSS сінтаксічна падобны на XPath, пры гэтым у некаторых выпадках CSS-лакатары працуюць хутчэй і апісваюцца больш наглядна і коратка. Мінусам CSS з'яўляецца тое, што ён працуе толькі ў адным кірунку - углыб дакумента. XPath жа працуе ў абодва бакі (напрыклад, можна шукаць бацькоўскі элемент па даччынаму).
- XQuery мае ў якасці асновы мова XPath. XQuery імітуе XML, што дазваляе ствараць укладзеныя выразы ў такім спосабам, які немагчымы ў XSLT.
- RegExp - фармальны мову пошуку для здабывання значэнняў з мноства тэкставых радкоў, якія адпавядаюць патрабаваным умовам (рэгулярнаму выразу).
- HTML templates - мова вымання дадзеных з HTML дакументаў, які ўяўляе сабой камбінацыю HTML-разметкі для апісання шаблону пошуку патрэбнага фрагмента плюс функцыі і аперацыі для вымання і пераўтварэнні дадзеных.
Звычайна пры дапамозе скрейпинга вырашаюцца задачы, з якімі складана справіцца ўручную. Гэта можа быць выманне апісанняў тавараў для стварэнні новага інтэрнэт-крамы, скрейпинг ў маркетынгавых даследаваннях для маніторынгу коштаў, альбо для маніторынгу аб'яваў.

У SiteAnalyzer за наладу скрейпинга адказвае ўкладка "Выманне дадзеных", у якой наладжваюцца правілы здабывання. Правілы можна захоўваць і, пры неабходнасці, рэдагаваць.
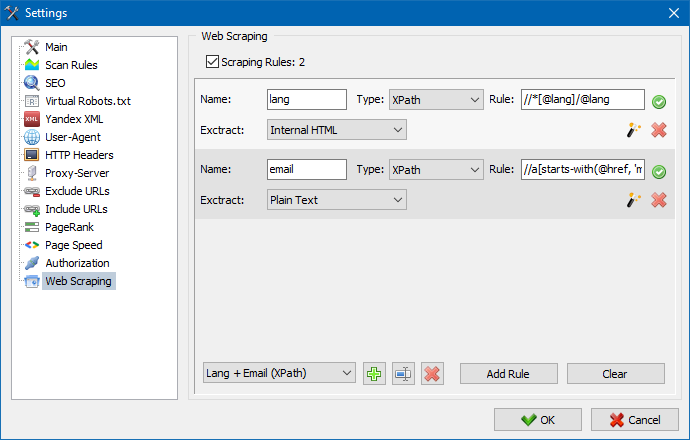
Таксама прысутнічае модуль тэставання правілаў. Пры дапамозе убудаванага адладчыка правілаў можна хутка і проста атрымаць HTML-змесціва любой старонкі сайта і тэставаць працу запытаў, пасля чаго выкарыстоўваць адладжаныя правілы для парсінга дадзеных у SiteAnalyzer.

Пасля заканчэння вымання дадзеных усю сабраную інфармацыю можна экспартаваць у Excel.
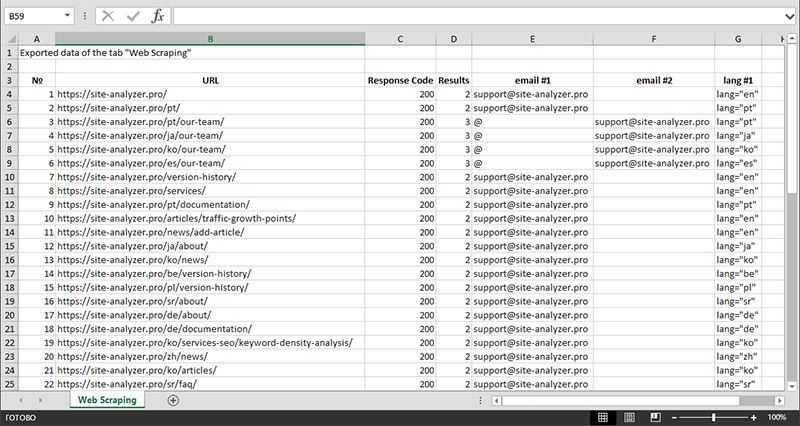
Больш падрабязна вывучыць працу модуля і азнаёміцца са спісам найбольш часта сустракаемых правілаў і рэгулярных выразаў можна ў артыкуле
2. Праверка унікальнасці кантэнту ўнутры сайта.
Дадзены інструмент дазваляе правесці пошук дублікатаў старонак і праверыць унікальнасць тэкстаў у самой сайта. Іншымі словамі гэта пакетная праверка групы URL на унікальнасць паміж сабой.
Гэта можа быць карысна ў выпадках:
- Для пошуку поўных дубляў старонак (напрыклад, старонка з параметрамі і тая ж самая старонка, але ў выглядзе ЛПК).
- Для пошуку частковых супадзенняў кантэнту (напрыклад, два рэцэпты баршчу ў кулінарным блогу, якія падобныя паміж сабой на 96%, што наводзіць на думку, што адзін з артыкулаў лепш выдаліць, каб пазбавіцца ад магчымай каннибализации трафіку).
- Калі на кожным артыкуле сайце вы выпадкова напісалі артыкул па тэме, якую ўжо пісалі раней за 10 гадоў таму. У гэтым выпадку наш інструмент таксама выявіць дублікат такога артыкула.
Прынцып працы інструмента праверкі ўнікальнасці кантэнту просты: па спісе URL сайта праграма запампоўвае іх змесціва, атрымлівае тэкставае змесціва старонкі (без блока HEAD і без HTML-тэгаў), а затым пры дапамозе алгарытму шинглов параўноўвае іх адзін з адным.

Такім чынам, пры дапамозе шинглов мы вызначаем унікальнасць старонак і можам вылічыць як поўныя дублі старонак з 0% унікальнасцю, так і частковыя дублі з рознымі ступенямі унікальнасці тэкставага змесціва. Праграма працуе з даўжынёй шингла роўнай 5.
Больш падрабязна вывучыць працу модуля можна ў дадзеным артыкуле: >>
3. Праверка хуткасці загрузкі старонак па Google PageSpeed.
Інструмент PageSpeed Insights пошукавага гіганта Google дазваляе правяраць хуткасць загрузкі тых ці іншых элементаў старонак, а таксама паказвае агульны баль хуткасці загрузкі цікавяць URL для дэсктопнай і мабільнай версіі браўзэра.

Інструмент Google усім добры, аднак, мае адзін істотны мінус - ён не дазваляе ствараць групавыя праверкі URL, што стварае нязручнасці пры праверцы мноства старонак вашага сайта: пагадзіцеся, што ўручную правяраць хуткасць загрузкі для 100 і больш URL па адной старонцы моташна і можа заняць нямала часу.
Таму, намі быў створаны модуль, які дазваляе бясплатна ствараць групавыя праверкі хуткасці загрузкі старонак праз адмысловы API ў інструменце Google PageSpeed Insights.

Асноўныя аналізаваныя параметры:
- FCP (First Contentful Paint) – час адлюстравання першага кантэнту.
- SI (Speed Index) – паказчык таго, як хутка адлюстроўваецца кантэнт на старонцы.
- LCP (Largest Contentful Paint) – час адлюстравання найбольшага па памеры элемента старонкі.
- TTI (Time to Interactive) – час, на працягу якога старонка становіцца цалкам гатовая да ўзаемадзеяння з карыстальнікам.
- TBT (Total Blocking Time) – час ад першай адмалёўкі кантэнту да яго гатоўнасці да ўзаемадзеяння з карыстальнікам.
- CLS (Cumulative Layout Shift) – назапашвальны зрух макета. Служыць для вымярэння візуальнай стабільнасці старонкі.
Дзякуючы шматструменнай працы праграмы SiteAnalyzer, праверка сотні і больш URL можа заняць усяго некалькі хвілін, на што ў ручным рэжыме, праз браўзэр, мог бы сысці дзень або больш.
Пры гэтым, сам аналіз URL адбываецца ўсяго ў пару клікаў, пасля чаго даступная выгрузка справаздачы, які ўключае асноўныя характарыстыкі праверак у зручным выглядзе ў Excel.
Усё, што вам патрабуецца для пачатку работы - атрымаць ключ API.
Як гэта зрабіць - апісана ў дадзеным артыкуле >>
4. Дададзеная магчымасць групоўкі праектаў па тэчках.
Для больш зручнай навігацыі па спісе праектаў была дададзеная магчымасць групоўкі сайтаў па тэчках.

Дадаткова з'явілася магчымасць фільтрацыі спісу праектаў па назве.
5. Абноўлены інтэрфейс налад праграмы.
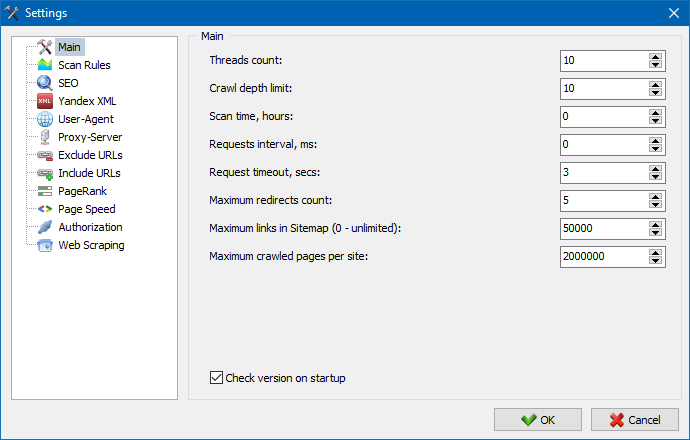
З пашырэннем функцыяналу праграмы нам стала "цесна" выкарыстоўваць табы, таму мы перафарматаваць акно налад у больш зразумелы і функцыянальны інтэрфейс.
Заўвагі:
- выпраўлены некарэктны ўлік выключэнняў URL
- выпраўлены некарэктны ўлік глыбіні сканавання сайта
- адноўлена адлюстраванне рэдырэкт для URL, імпартаваных з файла
- адноўлена магчымасць перастаноўкі і запамінання парадку слупкоў на ўкладках
- адноўлены ўлік некананічных старонак, вырашана праблема з пустымі мета-тэгамі
- адноўлена адлюстраванне Анкор спасылак на ўкладцы Інфа
- паскораны імпарт вялікай колькасці URL з буфера абмену
- выпраўлены не заўсёды карэктны парсінга title і description
- адноўлена адлюстраванне alt і title ў малюнкаў
- выпраўлена завісанне пры пераходзе на ўкладку "Знешнія спасылкі" падчас сканавання праекта
- выпраўленая памылка, якая ўзнікае пры пераключэнні паміж праектамі і абнаўленні вузлоў ўкладкі "Статыстыка абыходу сайта"
- выпраўлена некарэктнае вызначэнне ўзроўню ўкладзенасці для URL з параметрамі
- выпраўленая сартаванне дадзеных па полі HTML-hash у галоўнай табліцы
- аптымізавана праца праграмы з кірылічнымі даменамі
- абноўлены інтэрфейс налад праграмы
- абноўлены дызайн лагатыпа


Author Simagin Andrey
Over 15 years of experience in SEO and marketing. Primary areas of expertise: development of software, tools, and web services for SEO (SiteAnalyzer, SEO Tools, SERPRiver). Website promotion services in Yandex... →
Агляд папярэдніх версій:
- Агляд новай версіі SiteAnalyzer 2.2
- Агляд новай версіі SiteAnalyzer 2.1
- Агляд новай версіі SiteAnalyzer 2.0


















