





















Прызначэнне праграмы
Праграма SiteAnalyzer прызначана для аналізу сайта і выяўлення тэхнічных памылак (пошук бітых спасылак, дублікатаў старонак, некарэктных адказаў сервера), а таксама памылак і недапрацовак у SEO-аптымізацыі (незапоўненыя мета-тэгі, лішак альбо поўнае адсутнасць загалоўкаў старонак h1, аналіз кантэнту старонкі, якасць перелинковки і мноства іншых SEO-параметраў).

Асноўныя магчымасці
- Сканаванне ўсіх старонак сайта, а таксама малюнкаў, скрыптоў і дакументаў
- Атрыманне кодаў адказу сервера для кожнай старонкі сайта (200, 301, 302, 404, 500, 503 і г. д.)
- Вызначэнне наяўнасці і змесціва Title, Keywords, Description, H1-H6
- Пошук і адлюстраванне "дублікатаў" старонак, мета-тэгаў і загалоўкаў
- Вызначэнне наяўнасці атрыбуту rel="кананічны" для кожнай старонкі сайта
- Прытрымліванне дырэктывам файла "robots.txt", мета-тэга "robots", альбо X-Robots-Tag
- Ўлік "noindex" і "nofollow" падчас абходу старонак сайта
- Скрейпинг дадзеных з дапамогай XPath, CSS, XQuery, RegEx
- Праверка унікальнасці кантэнту ўнутры сайта
- Праверка хуткасці загрузкі старонак па Google PageSpeed
- Спасылачныя аналіз: вызначэнне ўнутраных і знешніх спасылак для любой старонкі сайта
- Разлік ўнутранага паказчыка PageRank для кожнай старонкі сайта
- Візуалізацыя структуры сайта на графе
- Вызначэнне колькасці перанакіраваньняў са старонкі (рэдырэкт)
- Сканаванне адвольных URL і знешніх Sitemap.xml
- Генерацыя карты сайта "sitemap.xml" (з магчымасцю разбіцця на некалькі файлаў)
- Фільтраванне дадзеных па любым параметры (гнуткая налада фільтраў любой складанасці)
- Пошук адвольнага кантэнту на сайце
- Экспарт справаздач у CSV, Excel i PDF
Адрозненні ад аналагаў
- Нізкія патрабаванні да рэсурсаў кампутара, малы расход аператыўнай памяці
- Сканаванне сайтаў практычна любых аб'ёмаў за кошт нізкіх патрабаванняў да рэсурсаў кампутара
- Партатыўны фармат (працуе без ўстаноўкі на ПК або прама са зменнага носьбіта)
Раздзелы дакументацыі
- Пачатак працы
- Налады праграмы
- Асноўныя налады
- Сканаванне
- SEO
- Віртуальны Robots.txt new
- Yandex XML
- User-Agent
- Адвольныя HTTP-загалоўкі new
- Proxy-сервер
- Выключыць URL
- Прытрымлівацца URL
- PageRank
- Аўтарызацыя
- Праца з праграмай
- Налада слупкоў і ўкладак
- Фільтраванне дадзеных
- Тэхнічная статыстыка сайта
- Статыстыка SEO
- Custom Filters
- Custom Search
- Скрейпинг дадзеных
- Праверка унікальнасці кантэнту
- Праверка хуткасці загрузкі старонак
- Структура сайта
- Кантэкстнае меню спісу праектаў
- Візуалізацыя структуры сайта
- Графік размеркавання ўнутраных спасылак
- Графік хуткасці загрузкі старонак
- Генерацыя Sitemap.xml
- Сканаванне адвольных URL
- Dashboard
- Экспарт дадзеных
- Мультиязычность
- Сціск базы дадзеных
Пачатак працы
Пры запуску праграмы карыстачу даступная адрасная радок для ўводу URL аналізаванай сайта (можна ўвесці любую старонку сайта, так як пошукавы робат, прайшоўшы па спасылках зыходнай старонкі абыдзе ўвесь сайт, у тым ліку і галоўную старонку, пры ўмове, што ўсе спасылкі выкананы ў HTML і не выкарыстоўваюць Javascript).
Пасля націску кнопкі "Старт", пошукавы робат пачынае абыход усіх старонак сайта па ўнутраных спасылках (на знешнія рэсурсы, якія ён не пераходзіць, таксама не пераходзіць па спасылках, выкананым на Javascript).
Пасля таго, як робат абміне ўсе старонкі сайта становіцца даступным справаздачу, выкананы ў выглядзе табліцы і адлюстроўвае атрыманыя дадзеныя, згрупаваныя па тэматычных вакенцамі.
Усе аналізаваных праекты адлюстроўваюцца ў левай частцы праграмы і аўтаматычна захоўваюцца ў базе праграмы разам з атрыманымі дадзенымі. Для выдалення непатрэбных сайтаў скарыстайцеся кантэкстным меню спісу праектаў.
Заўвага:
- пры націску на кнопку "Паўза" сканіраванне праекта прыпыняецца, паралельна бягучы прагрэс сканавання захоўваецца ў базу, што дазваляе, напрыклад, зачыніць праграму і працягнуць сканаванне праекта пасля перазапуску праграмы з месца прыпынку
- кнопка "Стоп" спыняе сканаванне бягучага праекта без магчымасці працягу яго сканавання
Налады праграмы
Раздзел галоўнага меню "Налады" прызначаны для тонкіх налад працы праграмы з вонкавымі сайтамі і змяшчае 7 ўкладак:

Раздзел асноўных налад служыць для ўказанні праграме карыстацкіх дырэктыў, якія выкарыстоўваюцца пры сканаванні сайта.
Апісанне параметраў:
- Колькасць патокаў
- Чым больш лік патокаў, тым больш URL зможа апрацаваць у адзінку часу. Пры гэтым трэба ўлічваць, што большая колькасць патокаў вядзе да большай колькасці выкарыстоўваных рэсурсаў ПК. Рэкамендуецца ўсталёўваць колькасць патокаў ў дыяпазоне 5-10.
- Час сканавання
- Служыць для ўстаноўкі абмежаванні сканавання сайта па часе. Вымяраецца ў гадзінах.
- Максімальная глыбіня
- Дадзены параметр служыць для ўказанні сканавання глыбіні сайта. Галоўная старонка сайта мае ўзровень ўкладзенасці = 0. Напрыклад, калі трэба прасканаваць старонкі сайта выгляду "somedomain.ru/catalog.html" і "somedomain.ru/catalog/tovar.html", то ў такім выпадку неабходна выставіць значэнне максімальнай глыбіні = 2.
- Затрымка паміж запытамі
- Служыць для ўстаноўкі паўзаў пры зваротах сканнера да старонак сайта. Гэта бывае неабходна для сайтаў на "слабых" хостынгах, не вытрымоўваюць вялікіх нагрузак і частых да іх зваротаў.
- Тайм-аўт запыту
- Ўстаноўка часу чакання адказу сайта на запыт праграмы. Калі якія-небудзь з старонак сайта адказваюць павольна (доўга грузяцца), то сканаванне сайта можа заняць досыць працяглы час. Такія старонкі можна адсекчы, паказаўшы значэнне, пасля якога сканер пяройдзе да сканавання астатніх старонак сайта і тым самым не будзе затрымліваць агульны прагрэс.
- Лік сканаваных старонак сайта
- Абмежаванне на максімальную колькасць сканаваных старонак. Бывае карысна, калі, напрыклад, вам трэба прасканаваць першыя N старонак сайта (пры гэтым не ўлічваюцца малюнка, файлы стыляў, скрыпты і іншыя тыпы файлаў).

Ўлічваць кантэнт
- У дадзеным раздзеле можна выбраць тыпы дадзеных, якія будуць улічвацца парсером пры абыходзе старонак (малюнкі, відэа, стылі, скрыпты), альбо выключыць лішнюю інфармацыю пры парсинге.
Правілы сканавання
- Дадзеныя налады звязаныя з наладамі выключэнняў пры абыходзе сайта сканнером выкарыстоўваючы файл "robots.txt", па спасылках тыпу "nofollow", а таксама выкарыстоўваючы дырэктывы "meta name=robots" непасрэдна ў кодзе старонак сайта.

Дадзены раздзел служыць для ўказанні асноўных аналізаваных SEO-параметраў, якія ў далейшым будуць правярацца на карэктнасць пры парсинге старонак, пасля чаго атрыманая статыстыка будзе адлюстравана на ўкладцы "Статыстыка SEO" у правай частцы галоўнага акна праграмы.
Пры дапамозе дадзеных налад можна выбраць сэрвіс, з дапамогай якога будзе вырабляцца праверка індэксацыі старонак у пошукавай сістэме Yandex. Маецца два варыянты праверкі індэксацыі: пры дапамозе сэрвісу Yandex XML альбо сэрвісу Majento.ru.

Пры выбары сэрвісу Yandex XML трэба ўлічваць магчымыя абмежаванні (пагадзінныя альбо штодзённыя), якія могуць быць ужытыя пры праверцы індэксацыі старонак, адносна наяўных лімітаў на Вашым рахунку Yandex, у выніку чаго часта могуць узнікаць сітуацыі, калі лімітаў вашага акаўнта не будзе хапаць для праверкі ўсіх старонак за адзін раз і для гэтага прыйдзецца чакаць наступнага гадзіны.
Пры выкарыстанні сэрвісу Majento.ru пагадзінныя альбо штодзённыя абмежаванні практычна адсутнічаюць, так як ваш ліміт літаральна ўліваецца ў агульны пул лімітаў, які сам па сабе не малы, а таксама мае значна большы ліміт пры пагадзінных абмежаваннях, чым любы з асобных карыстацкіх акаўнтаў на Yandex XML.

Віртуальны robots.txt можна выкарыстоўваць замест рэальнага robots.txt, размешчанага на сайце.
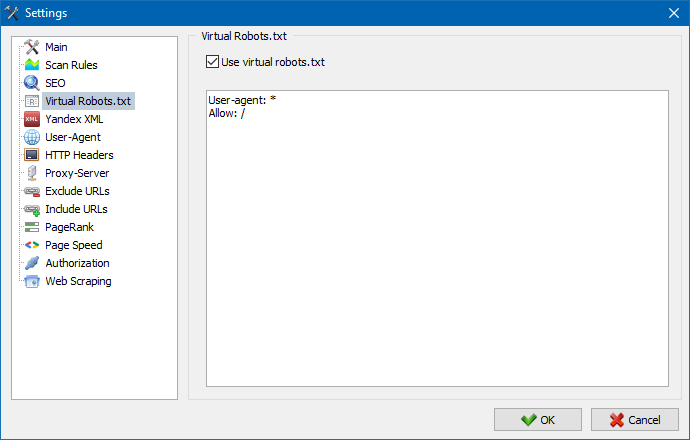
Гэта бывае зручна пры тэставанні сайта, калі, напрыклад, трэба прасканаваць пэўныя раздзелы сайта, зачыненыя ад індэксацыі (альбо наадварот - не ўлічваць іх пры сканаванні), пры гэтым не трэба фізічна ўносіць змены ў рэальны robots.txt і марнаваць на гэты час распрацоўніка.
Нататка: пры імпарце спісу URL улічваюцца дырэктывы віртуальнага robots.txt (калі гэтая опцыя актываваная), інакш ніякі robots.txt для спісу URL не ўлічваецца.
У раздзеле User-Agent можна паказаць, якім юзэр-агентам будзе прадстаўляцца праграма пры звароце да знешніх сайтаў падчас іх сканавання. Па умочанию, усталяваны карыстацкі юзэр-агент, аднак пры неабходнасці можна абраць адзін з стандартных агентаў, найбольш часта сустракаемых у інтэрнэт. Сярод іх ёсць такія, як: боты пошукавых сістэм YandexBot, GoogleBot, MicrosoftEdge, боты браўзэраў Chrome, Firefox, IE8, а таксама мабільных прылад iPhone, Android і многія іншыя.

Пры дапамозе гэтай опцыі можна аналізаваць рэакцыю сайта і старонак на розныя запыты. Напрыклад, камусьці можа спатрэбіцца аддаваць у запыце Referer, уладальнікам мультымоўных сайтаў захочацца перадаваць Accept-Language|Charset|Encoding, а ў кагосьці ёсць запатрабаванне ў перадачы незвычайных дадзеных у загалоўках Accept-Encoding, Cache-Control, Pragma і т.д. п.
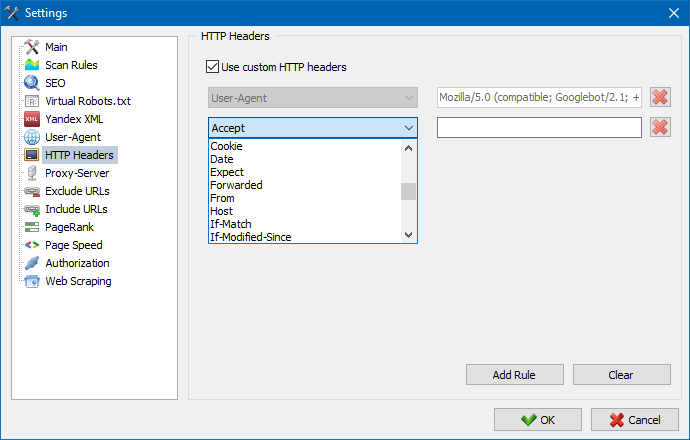
Пры дапамозе гэтай опцыі можна аналізаваць рэакцыю сайта і старонак на розныя запыты. Напрыклад, камусьці можа спатрэбіцца аддаваць у запыце Referer, уладальнікам мультымоўных сайтаў захочацца перадаваць Accept-Language|Charset|Encoding, а ў кагосьці ёсць запатрабаванне ў перадачы незвычайных дадзеных у загалоўках Accept-Encoding, Cache-Control, Pragma і т.д. п.
Калі ёсць неабходнасць працаваць праз проксі, то ў дадзеным раздзеле вы можаце дадаць спіс проксі-сервераў, праз якія праграма будзе звяртацца да знешніх рэсурсаў. Дадаткова, маецца магчымасць праверкі проксі на працаздольнасць, а таксама функцыя выдалення неактыўных проксі-сервераў.

Дадзены падзел прызначаны для выключэння абыходу пэўных старонак і падзелаў сайта пры парсинге.
Пры дапамозе шаблонаў пошуку * і ? можна паказаць, якія раздзелы сайта не павінны абыходзіцца краулером і, адпаведна, не павінны патрапіць у базу праграмы. Дадзены спіс з'яўляецца лакальным спісам выключэнняў на час сканавання сайта (адносна яго "глабальным" спісам з'яўляецца файл "robots.txt" у корані сайта).

Аналагічна дазваляе дадаваць URL, якія павінны быць абавязкова прасканавала. Пры гэтым усе астатнія URL, за межамі гэтых тэчак, падчас сканавання будуць праігнараваныя. Дадзеная опцыя таксама працуе пры дапамозе шаблонаў пошуку * і ?

Пры дапамозе параметру PageRank можна аналізаваць навігацыйную структуру вашых сайтаў, а таксама аптымізаваць сістэму ўнутраных спасылак вэб-рэсурсу для перадачы спасылкавага вагі найбольш важным старонках.

У праграме даступна два варыянты разліку PageRank: класічны алгарытм і яго больш сучасны аналаг. У цэлым, для аналізу ўнутранай перелинковки сайта няма вялікай розніцы пры выкарыстанні першага або другога алгарытмаў, таму вы можаце выкарыстоўваць любы алгарытм з двух прапанаваных.
Падрабязнае апісанне алгарытму і прынцыпы разліку PageRank чытайце ў артыкуле "Разлік ўнутранага PageRank": >>

Увод лагіна і пароля для аўтаматычнай аўтарызацыі на старонках, закрытых праз .htpasswd і абароненых BASIC аўтарызацыяй сервера.
Праца з праграмай
Пасля завяршэння сканавання карыстачу становіцца даступная інфармацыя, размешчаная ў блоку "Асноўныя звесткі". Кожная ўкладка змяшчае дадзеныя, згрупаваныя адносна іх назваў (напрыклад, ўкладка "Title" змяшчае змесціва загалоўкаў старонак <title></title>, ўкладка "Выявы" змяшчае спіс усіх малюнкаў сайта і так далей). З дапамогай гэтых дадзеных можна праводзіць аналіз змесціва сайта, знаходзіць "бітыя" спасылкі або некарэктна запоўненыя мета-тэгі.

Пры неабходнасці (напрыклад, пасля ўнясення змяненняў на сайце) з дапамогай кантэкстнага меню маецца магчымасць новае сканаванне асобных URL для адлюстравання змяненняў у праграме.
З дапамогай гэтага ж меню можна адлюстроўваць дублікаты старонак па адпаведных параметрах (дублі title, description, keywords, h1, h2, кантэнт старонак).

Пункт "Пересканировать URL з кодам 0" прызначаны для аўтаматычнай пераправеркі ўсіх старонак, якія аддаюць код адказу 0 (Read Timeout). Дадзены код адказу звычайна аддаецца, калі сервер не паспявае аддаваць кантэнт і злучэнне зачыняецца па таймаўту, адпаведна, старонка не можа быць загружана і інфармацыя з яе не можа быць вынятая.
Цяпер можна выбраць, якія ўкладкі будуць адлюстроўвацца ў інтэрфейсе асноўных дадзеных (нарэшце, стала магчымым развітацца з маральна састарэлай укладкай Meta Keywords). Гэта бывае зручна, калі табы не змяшчаюцца на экране, альбо вы рэдка іх выкарыстоўваеце.

Слупкі таксама можна хаваць небудзь перамяшчаць у патрэбнае месца шляхам перацягвання.
Адлюстраванне табаў і слупкоў можна наладзіць з дапамогай выкліку кантэкстнага меню на панэлі асноўных дадзеных. Перанос калонак ажыццяўляецца з дапамогай мышы.
Для больш зручнага аналізу статыстыкі сайта ў праграме даступная фільтраванне дадзеных. Фільтраванне магчымая ў двух варыянтах:
- па любых палёў пры дапамозе "хуткага" фільтра
- з выкарыстаннем карыстацкага фільтра (пры дапамозе пашыраных налад выбаркі дадзеных)
Хуткі фільтр
Выкарыстоўваецца для хуткай фільтрацыі дадзеных і ўжываецца адначасова да ўсіх палях бягучай ўкладкі.

Наладжвальны фільтр
Прызначаны для падрабязнай фільтрацыі і можа ўтрымліваць адначасова некалькі умоў. Напрыклад, для мета-тэга "title" вы хадзіце адфільтраваць старонкі па іх даўжыні, каб ён не перавышаў 70 знакаў і адначасова утрымліваў тэкст "навіны". Тады гэты фільтр будзе выглядаць так:

Такім чынам, ужываючы наладжвальны фільтр да любой з укладак, вы можаце атрымліваць выбаркі дадзеных любой складанасці.
Ўкладка тэхнічнай статыстыкі сайта знаходзіцца на панэлі "Дадатковыя звесткі" і змяшчае набор асноўных тэхнічных параметраў сайта: статыстыка па спасылках, мета-тэгах, кодах адказаў старонак, параметрах індэксацыі старонак, тыпах кантэнту і да т.п. параметрах.
Кліку па адным з параметраў яны аўтаматычна адфільтроўваюцца ў адпаведнай ўкладцы асноўных дадзеных сайта, а таксама адначасова адлюстроўваецца статыстыка на дыяграме ў ніжняй частцы старонкі.

Ўкладка SEO-статыстыкі прызначана для правядзення паўнавартасных аўдытаў сайта і змяшчае 50+ асноўных SEO-параметраў і вызначае больш за 60 ключавых памылак ўнутранай аптымізацыі! Адлюстраванне памылак дзеліцца на групы, якія, у сваю чаргу, ўтрымліваюць наборы аналізаваных параметраў і фільтры, што выяўляюць памылкі на сайце.
Падрабязнае апісанне ўсіх правяраемых параметраў чытайце ў гэтым артыкуле. >>

Для ўсіх вынікаў фільтрацыі ёсць магчымасць іх хуткага экспарту ў Excel без дадатковых дыялогаў (справаздачу захоўваецца ў тэчцы з праграмай).
На дадзенай ўкладцы размяшчаюцца прадусталяваныя фільтры, якія дазваляюць ствараць выбаркі па ўсіх знешніх спасылках, памылак 404, малюнкаў і іншых параметрах з усімі старонкамі, на якіх яны прысутнічаюць. Такім чынам, зараз вы можаце лёгка і хутка атрымаць спіс знешніх спасылак і старонак, на якіх яны размешчаны, або выбраць усе бітыя спасылкі і адразу ўбачыць, на старонках якіх яны размешчаны.

Усе справаздачы даступныя ў праграме ў рэжыме онлайн і адлюстроўваюцца на ўкладцы "Custom" панэлі асноўных дадзеных. Дадаткова, ёсць магчымасць іх экспарту ў Excel праз галоўнае меню.
Функцыя пошуку кантэнту на сайце дазваляе вырабляць пошук па зыходным кодзе і адлюстроўваць вэб-старонкі, якія змяшчаюць шуканы кантэнт.
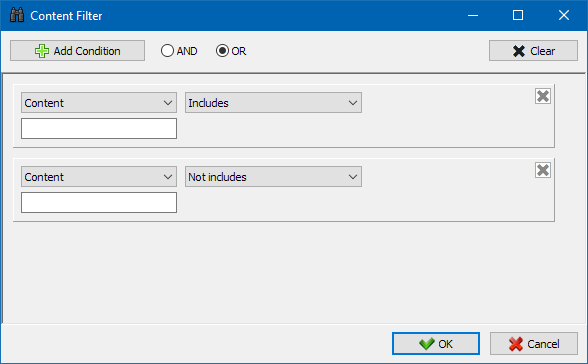
Модуль наладжвальных фільтраў дазваляе праверыць наяўнасць на сайце микроразметки, мета-тэгаў, сістэм аналітыкі, фрагментаў адвольнага тэксту альбо HTML-кода.
У акне канфігурацыі фільтра ёсць некалькі параметраў для пошуку пэўных фрагментаў тэксту на старонках сайта, альбо, наадварот, для выключэння з вынікаў пошуку старонак, якія змяшчаюць пэўны тэкст альбо фрагмэнты HTML-кода (дадзеная функцыя аналагічная пошуку кантэнту ў зыходным кодзе старонкі па Ctrl-F) .
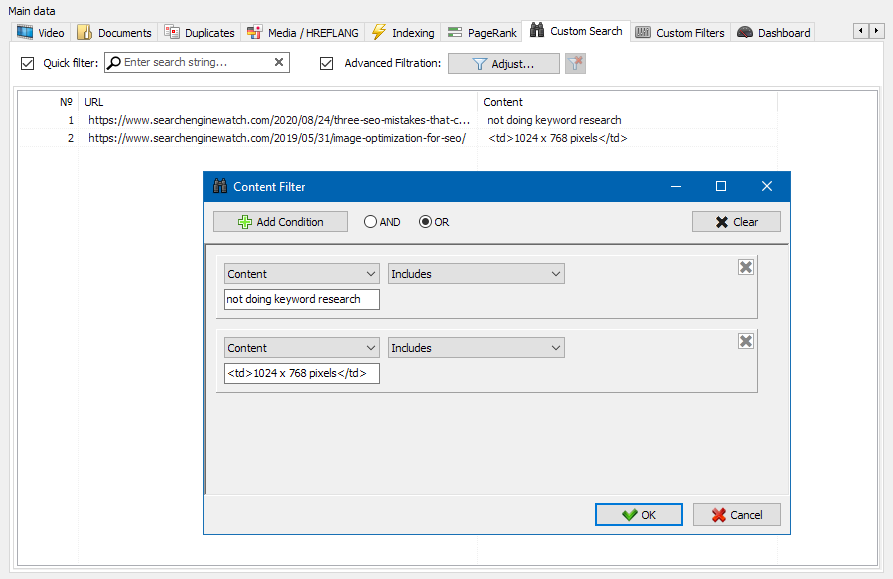
Звычайна пры дапамозе скрейпинга вырашаюцца задачы, з якімі складана справіцца ўручную. Гэта можа быць выманне апісанняў тавараў для стварэнні новага інтэрнэт-крамы, скрейпинг ў маркетынгавых даследаваннях для маніторынгу коштаў, альбо для маніторынгу аб'яваў.

У SiteAnalyzer за наладу скрейпинга адказвае ўкладка "Выманне дадзеных", у якой наладжваюцца правілы здабывання. Правілы можна захоўваць і, пры неабходнасці, рэдагаваць.
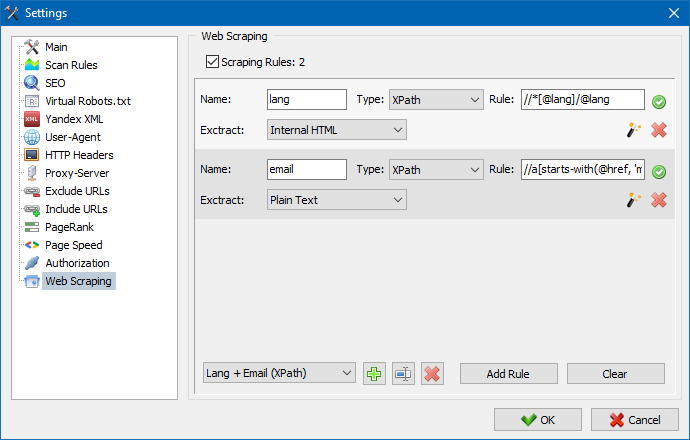
Таксама прысутнічае модуль тэставання правілаў. Пры дапамозе убудаванага адладчыка правілаў можна хутка і проста атрымаць HTML-змесціва любой старонкі сайта і тэставаць працу запытаў, пасля чаго выкарыстоўваць адладжаныя правілы для парсінга дадзеных у SiteAnalyzer.

Пасля заканчэння вымання дадзеных усю сабраную інфармацыю можна экспартаваць у Excel.
Больш падрабязна вывучыць працу модуля і азнаёміцца са спісам найбольш часта сустракаемых правілаў і рэгулярных выразаў можна ў артыкуле
Праверка унікальнасці кантэнту
Дадзены інструмент дазваляе правесці пошук дублікатаў старонак і праверыць унікальнасць тэкстаў у самой сайта. Іншымі словамі гэта пакетная праверка групы URL на унікальнасць паміж сабой.
Гэта можа быць карысна ў выпадках:
- Для пошуку поўных дубляў старонак (напрыклад, старонка з параметрамі і тая ж самая старонка, але ў выглядзе ЛПК).
- Для пошуку частковых супадзенняў кантэнту (напрыклад, два рэцэпты баршчу ў кулінарным блогу, якія падобныя паміж сабой на 96%, што наводзіць на думку, што адзін з артыкулаў лепш выдаліць, каб пазбавіцца ад магчымай каннибализации трафіку).
- Калі на кожным артыкуле сайце вы выпадкова напісалі артыкул па тэме, якую ўжо пісалі раней за 10 гадоў таму. У гэтым выпадку наш інструмент таксама выявіць дублікат такога артыкула.
Прынцып працы інструмента праверкі ўнікальнасці кантэнту просты: па спісе URL сайта праграма запампоўвае іх змесціва, атрымлівае тэкставае змесціва старонкі (без блока HEAD і без HTML-тэгаў), а затым пры дапамозе алгарытму шинглов параўноўвае іх адзін з адным.

Такім чынам, пры дапамозе шинглов мы вызначаем унікальнасць старонак і можам вылічыць як поўныя дублі старонак з 0% унікальнасцю, так і частковыя дублі з рознымі ступенямі унікальнасці тэкставага змесціва. Праграма працуе з даўжынёй шингла роўнай 5.
Больш падрабязна вывучыць працу модуля можна ў дадзеным артыкуле: >>
Праверка хуткасці загрузкі старонак
Інструмент PageSpeed Insights пошукавага гіганта Google дазваляе правяраць хуткасць загрузкі тых ці іншых элементаў старонак, а таксама паказвае агульны баль хуткасці загрузкі цікавяць URL для дэсктопнай і мабільнай версіі браўзэра.

Інструмент Google усім добры, аднак, мае адзін істотны мінус - ён не дазваляе ствараць групавыя праверкі URL, што стварае нязручнасці пры праверцы мноства старонак вашага сайта: пагадзіцеся, што ўручную правяраць хуткасць загрузкі для 100 і больш URL па адной старонцы моташна і можа заняць нямала часу.
Таму, намі быў створаны модуль, які дазваляе бясплатна ствараць групавыя праверкі хуткасці загрузкі старонак праз адмысловы API ў інструменце Google PageSpeed Insights.

Асноўныя аналізаваныя параметры:
- FCP (First Contentful Paint) – час адлюстравання першага кантэнту.
- SI (Speed Index) – паказчык таго, як хутка адлюстроўваецца кантэнт на старонцы.
- LCP (Largest Contentful Paint) – час адлюстравання найбольшага па памеры элемента старонкі.
- TTI (Time to Interactive) – час, на працягу якога старонка становіцца цалкам гатовая да ўзаемадзеяння з карыстальнікам.
- TBT (Total Blocking Time) – час ад першай адмалёўкі кантэнту да яго гатоўнасці да ўзаемадзеяння з карыстальнікам.
- CLS (Cumulative Layout Shift) – назапашвальны зрух макета. Служыць для вымярэння візуальнай стабільнасці старонкі.
Пры гэтым, сам аналіз URL адбываецца ўсяго ў пару клікаў, пасля чаго даступная выгрузка справаздачы, які ўключае асноўныя характарыстыкі праверак у зручным выглядзе ў Excel.
Усё, што вам патрабуецца для пачатку работы - атрымаць ключ API.
Як гэта зрабіць - апісана ў дадзеным артыкуле >>
Дадзены функцыянал прызначаны для стварэння структуры сайта на аснове атрыманых дадзеных. Структура сайта генеруецца зыходзячы з ўкладзенасці URL старонак. Пасля генерацыі структуры даступны яе экспарт у CSV-фармат (Excel).

Кантэкстнае меню спісу праектаў
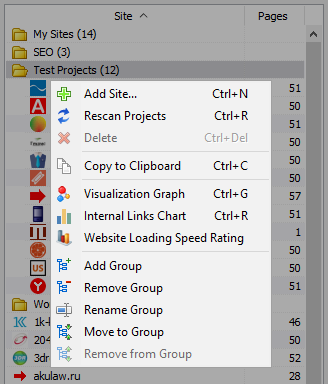
- У спісе праектаў даступна масавае сканаванне шляхам выдзялення патрэбных сайтаў і націску кнопкі "Пересканировать". Пасля чаго ўсе сайты становяцца ў чаргу і скануюцца па чарзе ў стандартным рэжыме.
- Таксама, для выгоды працы з праграмай, масавае выдаленне выбраных сайтаў таксама даступна па кнопцы "Выдаліць".
- Акрамя адзінкавага сканавання сайтаў, існуе магчымасць масавага дадання сайтаў у спіс праектаў з дапамогай спецыяльнай формы, пасля чаго карыстальнік можа прасканаваць цікавяць праекты цалкам.
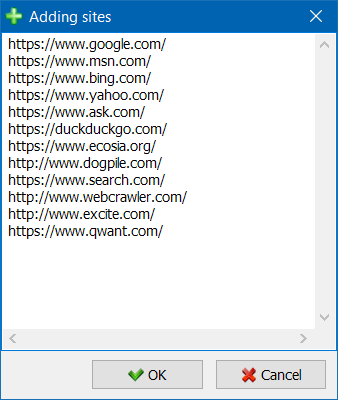
- Для больш зручнай навігацыі па спісе праектаў даступная магчымасць групоўкі сайтаў па тэчках, а таксама фільтраванне спісу праектаў па назве.

Рэжым візуалізацыі спасылкавых сувязяў на графе дапаможа SEO-спецыяліста ацаніць размеркаванне ўнутранага PageRank на старонках сайта, а таксама зразумець, якія з старонак атрымліваюць вялікую спасылачныя масу (і адпаведна, большы ўнутраны кантрольны вага ў вачах пошукавых сістэм), а якім старонках і раздзелах сайта не хапае ўнутраных спасылак.

Пры дапамозе рэжыму візуалізацыі структуры сайта SEO-спецыяліст зможа наглядна ацаніць тое, як арганізавана ўнутраная перелинковка на сайце, а таксама за кошт візуальнага прадстаўлення масы PageRank, прысвоенай тым ці іншым старонкам, аператыўна ўносіць карэкціроўкі ў бягучую перелинковку сайта і тым самым павышаць рэлевантнасць старонак, якія цікавяць.
У левай частцы акна візуалізацыі знаходзяцца асноўныя інструменты для працы з графам:
- змена маштабу на графе
- паварот графа на адвольны кут
- пераключэнне вокны графа ў поўнаэкранны рэжым (таксама працуе па клавішы F11)
- адлюстраванне / утойванне подпісаў да вузлоў (Ctrl-T)
- адлюстраванне / утойванне стрэлак у ліній
- адлюстраванне / утойванне спасылак на вонкавыя рэсурсы (Ctrl-E)
- пераключэнне рэжыму каляровай схемы Дзень / Ноч (Ctrl-D)
- адлюстраванне / утойванне легенды і статыстыкі графа (Ctrl-L)
- захаванне графа ў фармат PNG (Ctrl-S)
- акно налад візуалізацыі (Ctrl-O)
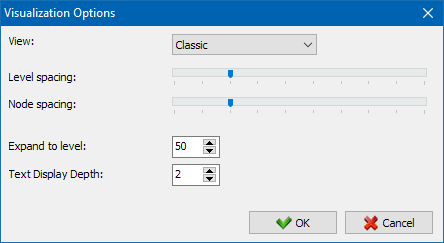
Раздзел "Выгляд" прызначаны для змены фармату адлюстравання вузлоў на графе. У рэжыме малявання вузлоў "PageRank", памеры вузлоў ўсталёўваюцца адносна іх раней разлічанага паказчыка PageRank, у выніку чаго на графе можна наглядна ўбачыць, якія старонкі атрымліваюць большы кантрольны вага, а якім дастаецца менш за ўсё спасылак.
У класічным рэжыме памеры вузлоў ўсталёўваюцца адносна абранага маштабу графа візуалізацыі.
Графік размеркавання ўнутраных спасылак
Гэты графік паказвае размеркаванне ўнутранай спасылачныя масы на старонках сайта (можна сказаць, што гэта візуалізацыя перелинковки ў наглядным выглядзе, чым яна прадстаўлена на графе візуалізацыі). Чытаць больш >>
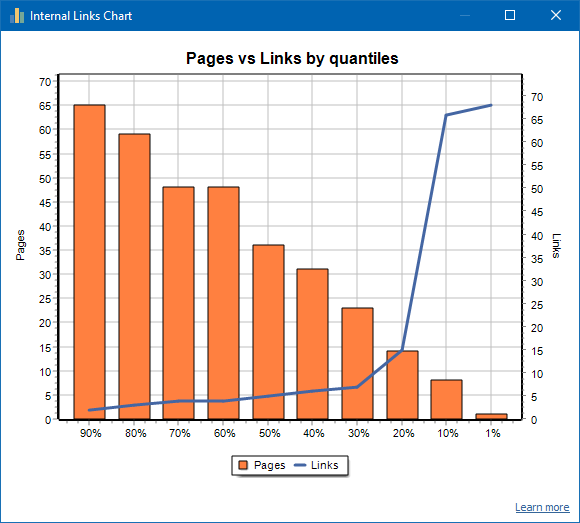
Злева адлюстравана лік старонак, справа - лік спасылак. Унізе - працэнтныя Квант па старонках. Пры складанні графіка дублікаты спасылак адкідаюцца (калі са старонкі А на старонку Б вядзе 3 спасылкі, то мы іх лічым за адну).
Напрыклад, зыходзячы з скрыншота вышэй, для сайта з парадку 70 старонак:
- 1% старонак маюць ~68 якія ўваходзяць спасылак.
- 10% старонак маюць ~66 якія ўваходзяць спасылак.
- 20% старонак маюць ~15 якія ўваходзяць спасылак.
- 30% старонак маюць ~8 якія ўваходзяць спасылак.
- 40% старонак маюць ~7 якія ўваходзяць спасылак.
- 50% старонак маюць ~6 якія ўваходзяць спасылак.
- 60% старонак маюць ~5 якія ўваходзяць спасылак.
- 70% старонак маюць ~5 якія ўваходзяць спасылак.
- 80% старонак маюць ~3 якія ўваходзяць спасылак.
- 90% старонак маюць ~2 якія ўваходзяць спасылак.
Гэта значыць, калі мы бачым, што ў нас маюцца старонкі, на якія вядзе менш за 10 якія ўваходзяць спасылак, то такія старонкі мы можам лічыць слаба залинкованными, а нармальна залинкованных у нас 60% старонак. Зыходзячы з гэтага, мы можам альбо праставіць больш ўнутраных спасылак на гэтыя слаба залинкованные старонкі (калі старонкі важныя для прасоўвання), альбо пакінуць як ёсць, калі падобныя старонкі маюць малое значэнне і нізкі прыярытэт.
На агульнай практыцы, старонкі, якія маюць менш за 10 ўнутраных спасылак горш кра-ул пошукавымі робатамі, у прыватнасці, ботамі Google.
Таму, калі вы бачыце сайт, у якога нармальна залинкованных ўсяго 20-30% старонак ад агульнага ліку старонак на сайце, то мае сэнс паглыбіцца ў наладу перелинковки небудзь падумаць, як паступіць з гэтымі 80-70% слаба залинкованных старонак (выдаліць, схаваць ад індэксацыі, паставіць рэдырэкты).
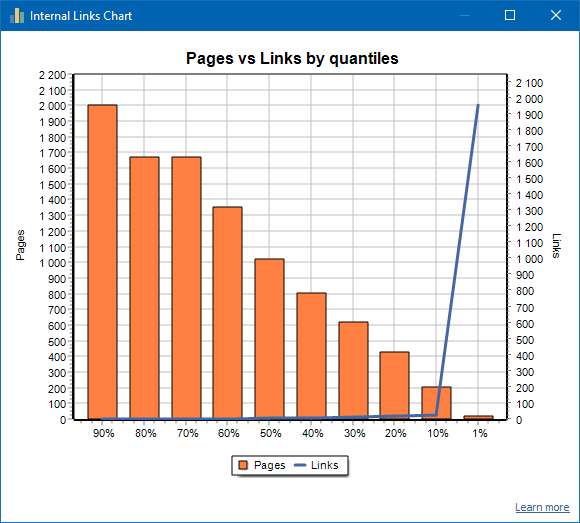
Прыклад слаба залинкованного сайта:
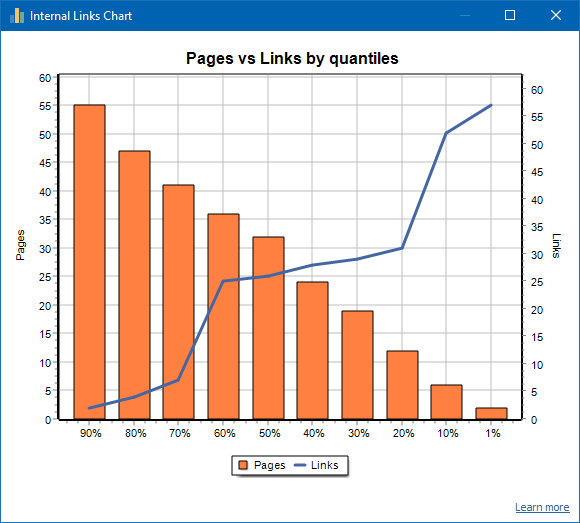
Прыклад добра залинкованного сайта:
Графік хуткасці загрузкі старонак
Графік хуткасці загрузкі старонак дазваляе ацаніць хуткадзейнасць сайта. Для нагляднасці, старонкі размеркаваны па групах і часовым інтэрвалам з крокам у 100 мілісекунд.
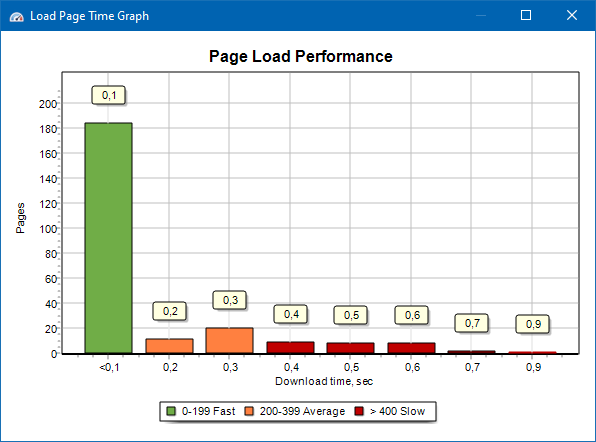
Такім чынам, зыходзячы з графіка можна вызначыць, якая частка старонак сайта грузіцца хутка (у межах 0-100 мілісекунд), якая з сярэдняй хуткасцю (100-200 мілісекунд) і якія старонкі загружаюцца дастаткова доўга (400 мілісекунд і больш).
Заўвага: паказаны час з'яўляецца часам загрузкі зыходнага кода HTML, а не часам поўнай загрузкі старонак (рэндэрынг старонкі, а таксама падгрузка элементаў старонкі, такіх як, напрыклад, малюнкі і стылі, не ўлічваецца).
Генерацыя Sitemap.xml
Карта сайта генеруецца на аснове прасканаваных старонак альбо малюнкаў сайта.
- Пры генерацыі карты сайта, якая складаецца з старонак, у яе дадаюцца старонкі фармату "text / html".
- Пры генерацыі карты сайта, якая складаецца з малюнкаў, у яе дадаюцца малюнка JPG, PNG, GIF і таму падобных фарматаў.
Згенераваць карту сайта можна адразу пасля сканавання сайта, праз галоўнае меню: пункт "Праекты -> Генераваць Sitemap".

Для сайтаў вялікіх аб'ёмаў, ад 50 000 старонак, маецца функцыя аўтаматычнага разбіцця "sitemap.xml" на некалькі файлаў (у гэтым выпадку асноўны файл змяшчае спасылкі на дадатковыя, якія змяшчаюць непасрэдна спасылкі на старонкі сайта). Гэта звязана з патрабаваннямі пошукавых сістэм для апрацоўкі файлаў sitemap вялікіх памераў.

Пры неабходнасці, аб'ём старонак у файле "sitemap.xml" можна вар'іраваць, змяніўшы значэнне 50 000 (ўстаноўлена па змаўчанні) на патрэбнае значэнне ў асноўных наладах праграмы.
Сканаванне адвольных URL
Пункт меню "Імпарт URL" прызначаны для сканавання адвольных спісаў URL, а таксама XML-карт сайта Sitemap.xml (у тым ліку і індэксных) для іх наступнага аналізу.
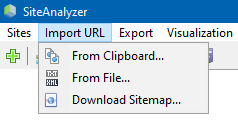
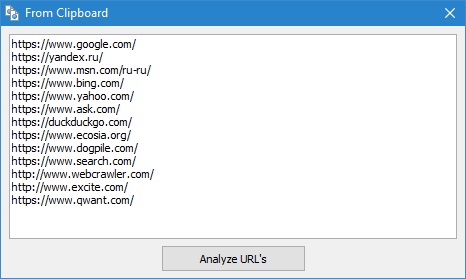
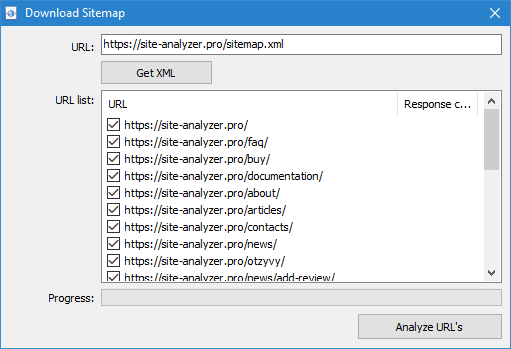
Сканаванне адвольных URL магчыма трыма спосабамі:
- шляхам ўстаўкі спісу URL з буфера абмену
- загрузкай з жорсткага дыска файлаў фармату *.txt і *.xml, якія змяшчаюць спісы URL
- шляхам запампоўкі файла Sitemap.xml непасрэдна з сайта
Асаблівасцю дадзенага рэжыму з'яўляецца тое, што пры сканаванні адвольных URL сам "праект" не захоўваецца ў праграме і дадзеныя па яго не дадаецца ў базу. Таксама не даступныя раздзелы "Структура сайта" і "Дашборд".
Больш падрабязна азнаёміцца з працай пункта "Імпарт URL" можна ў гэтым артыкуле: Агляд новай версіі SiteAnalyzer 1.9.
Dashboard
Ўкладка "Дашборд", адлюстроўвае падрабязную справаздачу аб бягучым якасці аптымізацыі сайта. Справаздача генеруецца на аснове дадзеных укладкі "Статыстыка SEO". Акрамя гэтых дадзеных у справаздачы прысутнічае ўказанне агульнага паказчыка якасці аптымізацыі сайта, разлічанага па 100-бальнай шкале адносна бягучай ступені яго аптымізацыі. Маецца магчымасць экспарту дадзеных укладкі "Дашборд" у зручны справаздачу ў фармаце PDF.

Экспарт дадзеных
Для больш гнуткага аналізу атрыманых дадзеных маецца магчымасць іх выгрузкі ў CSV-фармат (экспартуецца бягучая актыўная ўкладка), а таксама генерацыі паўнавартаснага справаздачы ў Microsoft Excel з усімі укладкамі ў адным файле.

Пры экспарце дадзеных у Excel з'яўляецца спецыяльнае акно, у якім карыстальнік можа выбраць пытанні, якія цікавяць калонкі і затым згенераваць справаздачу з патрэбнымі дадзенымі.

Мультиязычность
У праграме маецца магчымасць выбару пераважнага мовы, на якім будзе весціся праца.
Асноўныя падтрымліваюцца мовы: руская, англійская, нямецкая, італьянскі, іспанскі, французскі... На дадзены момант праграма перакладзеная на больш чым пятнаццаць (15) найбольш папулярных моў.

Калі вы хочаце перавесці праграму на сваю родную мову, то для гэтага дастаткова перавесці любы файл "*.lng" на які цікавіць мова, пасля чаго перакладзены файл трэба адправіць на адрас "support@site-analyzer.pro" (каментары да ліста павінны быць напісаны на рускай або англійскай мовах) і ваш пераклад будзе ўключаны ў новы рэліз праграмы.
Больш падрабязная інструкцыя па перакладзе праграмы на мовы знаходзіцца ў дыстрыбутыве (файл "lcids.txt").
P.S. Калі ў вас ёсць заўвагі па якасці перакладу - адпраўляйце заўвагі і выпраўленні на "support@site-analyzer.ru".
Сціск базы дадзеных
Пункт галоўнага меню "Сціснуць базу дадзеных" прызначаны для выканання аперацыі ўпакоўкі базы дадзеных (чыстка базы ад раней аддаленых праектаў, а таксама парадкаванне дадзеных (аналаг дэфрагментацыі дадзеных на персанальных кампутарах)).
Дадзеная працэдура эфектыўная ў выпадку, калі напрыклад, з праграмы быў выдалены буйны праект, які змяшчае вялікая колькасць запісаў. У цэлым рэкамендуецца праводзіць перыядычнае сціск дадзеных для збавення ад залішніх дадзеных і памяншэння аб'ёму базы.
З адказамі на астатнія пытанні можна азнаёміцца ў раздзеле FAQ >>



















