





















 1,393
1,393Olá a todos! Estamos de volta aos negócios!
Após um longo período, finalmente preparamos um novo lançamento do SiteAnalyzer, que, esperamos, irá atender às suas expectativas e se tornará um assistente indispensável na promoção de SEO.
Na nova versão do SiteAnalyzer, implementamos várias das funções mais solicitadas pelos usuários, tais como: coleta de dados (extração de dados do site), verificação da exclusividade do conteúdo e verificação da velocidade de carregamento da página pelo Google PageSpeed. Ao mesmo tempo, muitos bugs foram corrigidos e o logotipo foi reestilizado. Vamos falar sobre tudo com mais detalhes.

As principais alterações
1. Raspagem de dados com XPath, CSS, XQuery, RegEx.
Web scraping é um processo automatizado de extração de dados das páginas de interesse no site de acordo com certas regras.
Os principais métodos de web scraping são métodos de análise usando XPath, seletores CSS, XQuery, RegExp e modelos HTML.
- XPath é uma linguagem de consulta especial para elementos de documento XML / XHTML. Para acessar os elementos, o XPath usa a navegação DOM, descrevendo o caminho para o elemento desejado na página. Com sua ajuda, você pode obter o valor de um elemento por seu número ordinal no documento, extrair seu conteúdo de texto ou código interno, verificar a presença de um elemento específico na página.
- Os seletores CSS são usados para encontrar um elemento de sua parte (atributo). CSS é sintaticamente semelhante ao XPath, mas em alguns casos os localizadores CSS são mais rápidos e são mais descritivos e concisos. A desvantagem do CSS é que ele funciona apenas em uma direção - mais profundamente no documento. XPath, por outro lado, funciona nos dois sentidos (por exemplo, você pode pesquisar um elemento pai por um filho).
- XQuery é baseado em XPath. XQuery imita XML, o que permite criar expressões aninhadas de uma maneira que não é possível em XSLT.
- RegExp é uma linguagem de pesquisa formal para extrair valores de um conjunto de strings de texto que correspondem às condições exigidas (expressão regular).
- Os modelos HTML são uma linguagem para extrair dados de documentos HTML, que é uma combinação de marcação HTML para descrever o modelo de pesquisa para o fragmento desejado, além de funções e operações para extrair e transformar dados.
Normalmente, a raspagem é usada para resolver tarefas que são difíceis de realizar manualmente. Isso pode ser extrair descrições de produtos para criar uma nova loja online, raspando em pesquisas de marketing para monitorar preços ou para monitorar anúncios.

No SiteAnalyzer, a extração é configurada na guia Extração de dados, onde as regras de extração são configuradas. As regras podem ser salvas e, se necessário, editadas.
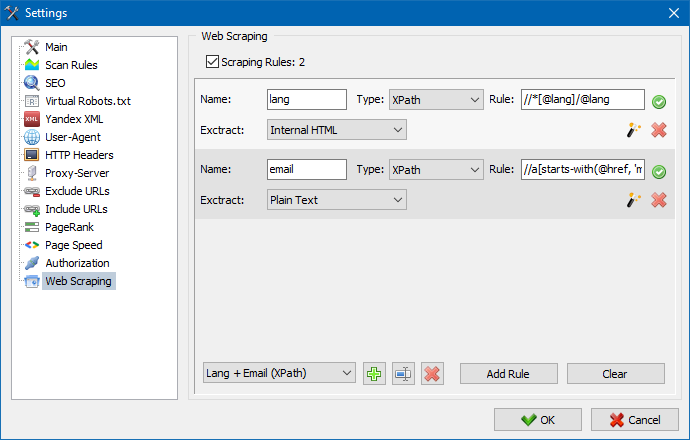
Também existe um módulo de teste de regra. Usando o depurador de regras integrado, você pode obter de forma rápida e fácil o conteúdo HTML de qualquer página do site e testar o trabalho das consultas e, em seguida, usar as regras depuradas para analisar dados no SiteAnalyzer.

Após finalizar a extração dos dados, todas as informações coletadas podem ser exportadas para o Excel.
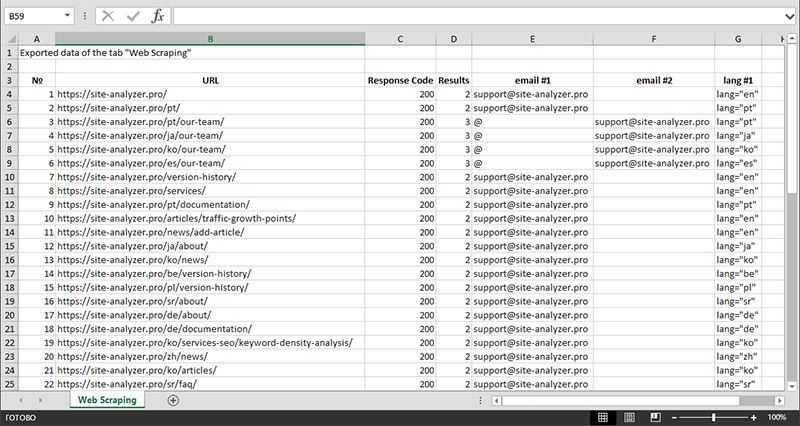
Para um estudo mais detalhado da operação do módulo e uma lista das regras e expressões regulares mais comuns, consulte o artigo
2. Verificar a exclusividade do conteúdo do site.
Esta ferramenta permite pesquisar páginas duplicadas e verificar a singularidade dos textos dentro do site. Em outras palavras, esta é uma verificação em lote de um grupo de URLs quanto à exclusividade entre eles.
Isso pode ser útil nos casos:
- Para pesquisar páginas duplicadas completas (por exemplo, uma página com parâmetros e a mesma página, mas na vista CNC).
- Para pesquisar correspondências parciais de conteúdo (por exemplo, duas receitas de borscht em um blog de culinária, que são 96% semelhantes entre si, o que sugere que um dos artigos deve ser excluído para se livrar de uma possível canibalização do tráfego).
- Quando em um site de artigos, você acidentalmente escreveu um artigo sobre um tópico que já havia escrito há 10 anos. Nesse caso, nossa ferramenta também detectará uma duplicata de tal artigo.
O princípio da ferramenta de verificação da singularidade do conteúdo é simples: o programa baixa o conteúdo da lista de URLs do site, recebe o conteúdo de texto da página (sem o bloco HEAD e sem tags HTML) e, a seguir, os compara com cada um outro usando o algoritmo de cascalho.

Assim, usando telhas, determinamos a exclusividade das páginas e podemos calcular duplicatas completas de páginas com 0% de exclusividade e duplicatas parciais com vários graus de exclusividade do conteúdo do texto. O programa funciona com um comprimento de telha de 5.
Você pode aprender mais sobre como o módulo funciona neste artigo.: >>
3. Verificar a velocidade de carregamento das páginas pelo Google PageSpeed.
A ferramenta PageSpeed Insights do gigante das buscas do Google permite que você verifique a velocidade de carregamento de certos elementos da página e também mostra a pontuação geral da velocidade de carregamento dos URLs de interesse para as versões desktop e móvel do navegador.

A ferramenta do Google é boa para todos, no entanto, tem uma desvantagem significativa - não permite que você crie verificações de URL de grupo, o que cria inconvenientes ao verificar muitas páginas do seu site: concorde que verificar manualmente a velocidade de download de 100 ou mais URLs em uma página é uma tarefa árdua e pode levar muito tempo.
Portanto, criamos um módulo que permite criar verificações de grupo de velocidade de carregamento de página gratuitamente por meio de uma API especial na ferramenta Google PageSpeed Insights.

Parâmetros principais analisados:
- FCP (First Contentful Paint) – hora de exibir o primeiro conteúdo.
- SI (Speed Index) – um indicador de quão rapidamente o conteúdo é exibido em uma página.
- LCP (Largest Contentful Paint) – tempo de exibição para o maior elemento da página.
- TTI (Time to Interactive) – o tempo durante o qual a página fica totalmente pronta para a interação do usuário.
- TBT (Total Blocking Time) – tempo desde a primeira renderização do conteúdo até sua prontidão para a interação do usuário.
- CLS (Cumulative Layout Shift) – mudança cumulativa de layout. Serve para medir a estabilidade visual da página.
Devido ao trabalho multithread do SiteAnalyzer, verificar centenas ou mais URLs pode levar apenas alguns minutos, o que pode levar um dia ou mais no modo manual por meio de um navegador.
Ao mesmo tempo, a análise da própria URL ocorre em apenas alguns cliques, após os quais um relatório pode ser baixado, incluindo as principais características dos cheques em um formato conveniente no Excel.
Tudo que você precisa para começar é obter uma chave de API.
Como fazer isso é descrito neste artigo. >>
4. Adicionada a capacidade de agrupar projetos por pastas.
Para uma navegação mais conveniente pela lista de projetos, foi adicionada a capacidade de agrupar sites por pastas.

Além disso, tornou-se possível filtrar a lista de projetos por nome.
5. A interface das configurações do programa foi atualizada.
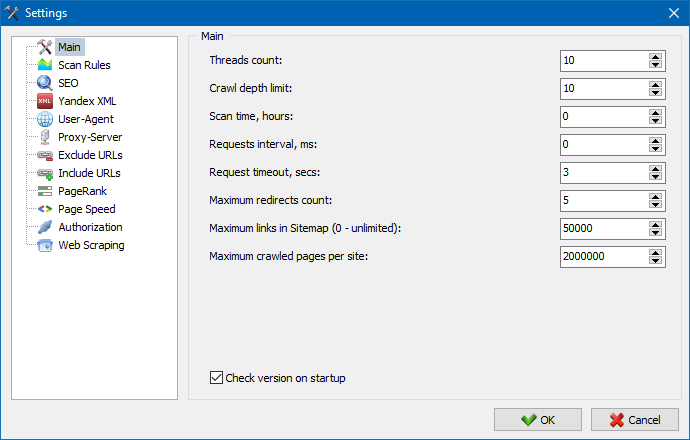
Com a expansão da funcionalidade do programa, ficou "apertado" o uso de guias, então reformatamos a janela de configurações em uma interface mais compreensível e funcional.
Notas:
- corrigiu contabilização incorreta de exceções de URL
- corrigiu contabilização incorreta da profundidade de rastreamento do site
- exibição restaurada de redirecionamentos para URLs importados de um arquivo
- restaurou a capacidade de reorganizar e lembrar a ordem das colunas nas guias
- restaurou a contabilidade de páginas não canônicas, resolveu o problema com metatags vazias
- exibição restaurada de âncoras de link na guia Informações
- importação acelerada de grande número de URLs da área de transferência
- corrigido nem sempre a análise correta do título e da descrição
- exibição restaurada de alt e título nas imagens
- congelamento corrigido ao alternar para a guia "Links externos" durante a digitalização de um projeto
- corrigiu o erro que ocorria ao alternar entre projetos e atualizar os nós da guia "Estatísticas de rastreamento do site"
- corrigiu a definição incorreta do nível de aninhamento para URL com parâmetros
- classificação de dados fixa por campo HTML-hash na tabela principal
- trabalho otimizado do programa com domínios cirílicos
- interface de configurações do programa atualizada
- design de logotipo atualizado

Visão geral das versões anteriores:
- Visão geral da nova versão do SiteAnalyzer 2.2
- Visão geral da nova versão do SiteAnalyzer 2.1
- Visão geral da nova versão do SiteAnalyzer 2.0


















