





















 1,982
1,982Nella versione 1.9 aggiunta la possibilità di scansione arbitrarie elenchi di URL, e anche XML-sitemaps Sitemap.xml (tra cui e indice) per la loro successiva analisi sul tema di ricerca "spezzato" riferimenti non corretti meta-tag, le intestazioni e simili errori.
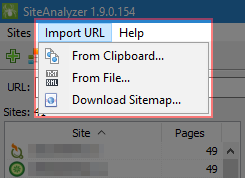
Le principali modifiche
Aggiunta la possibilità di acquisire l'elenco arbitrarie URL, utilizzando gli appunti o il download di un URL di un file su disco.
- Appunti. Il modo più semplice e veloce l'opzione di scansione arbitrarie URL attraverso appunti. Avendo negli appunti un elenco di URL per l'analisi, si sceglie nel menu la voce "Import URL" -> "appunti", dopo di che il programma copia automaticamente il contenuto degli appunti in un modulo separato, in cui è possibile aggiungere nuovi o modificare le attuali URL. Dopo aver fatto clic sul pulsante OK un elenco di URL aggiunto in programma, dopo di che inizia la loro scansione, in modo simile a come se hai acquisito un normale sito web.
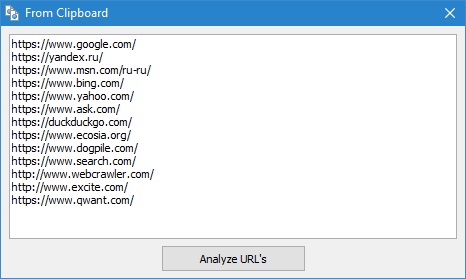
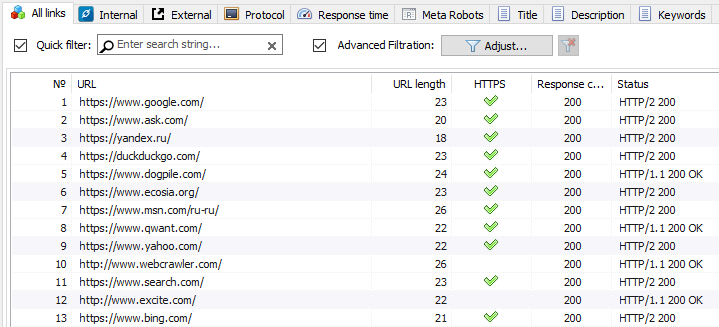
- Da un file su disco. Questa opzione è utile se l'elenco degli URL per il controllo si trova sul disco rigido in un file di testo o in un file Sitemap (*.txt e *.formati xml). In questo caso, l'importazione di un URL di questo tipo di file è simile importazione di appunti con l'unica eccezione che, dopo l'apertura dei file avviene la loro analisi su un oggetto di ricerca l'URL, e poi si ripete la procedura per aggiungere trovati URL nel modulo e loro successiva scansione programma SiteAnalyzer.
- Nota: durante l'importazione Sitemap.xml con il disco rigido si verifica la sua analisi su un oggetto, se è indice, e se è così, allora nel modulo viene visualizzato l'elenco interno del file XML, il cui contenuto verrà scaricato e inserito nel programma. Quando si importa un file di testo contenenti elenchi di URL, avviene semplice aggiunta del loro contenuto nel modulo per inviare l'URL alla successiva scansione.
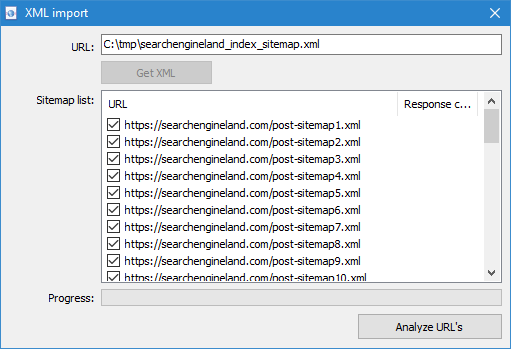
Aggiunta la possibilità di eseguire la scansione dei file Sitemap.xml (classico Sitemap o indice con l'elenco dei file XML).
- La scansione Sitemap.xml direttamente dal sito è disponibile attraverso l'opzione di menu "Importa URL" -> "Scarica Sitemap". Nella finestra che appare, è necessario specificare l'URL per il download e l'analisi del contenuto Sitemap.xml. Dopo aver fatto clic sul pulsante "Importa" il programma guida l'analisi del contenuto del file in oggetto, è se questo сайтмап indice o è normale Sitemap.xml con un elenco di URL del sito.
- Classico Sitemap.xml. Se questo era un classico Sitemap.xml qui di seguito il programma спарсит tutto il suo URL e dopo aver premuto il pulsante OK aggiungerà nel programma e li inizierà la scansione.
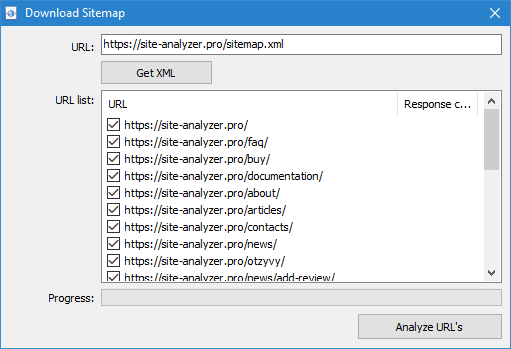
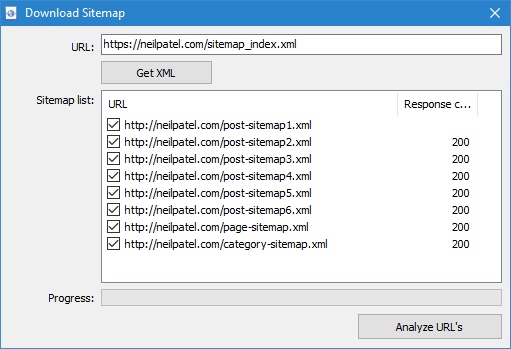
- Indice Sitemap.xml. Nel caso in cui Sitemap.xml sarà il file di indice, in quella stessa finestra, il programma visualizzerà una lista interni *.i file xml, così come il codice di risposta di ciascuno di essi. Con l'aiuto di caselle di controllo è possibile selezionare i file il cui contenuto si prevede di eseguire la scansione. Dopo aver premuto il pulsante OK contenuto dei dati da file XML sarà anche inserito nel programma e iniziare la loro scansione.
Note:
- Quando si importano URL accade validazione automatica di link per correttezza. Se la stringa non è un URL, non viene aggiunto alla coda di scansione.
- Vengono esaminati solo gli URL che sono stati inviati per la convalida, e solo loro. In questo modo, nel parsing di numeri in URL scanner non passa i link e non li aggiunge alla lista di scansione, come quando si esegue la scansione di un intero sito internet. Quanto URL stato importato in ingresso - tanto e sarà scansionata in uscita. Questa caratteristica vale per tutti i tipi di scansione arbitrarie URL.
- Quando si esegue la scansione arbitrarie URL stesso "progetto" non è salvato il programma e le informazioni su di esso non viene aggiunto al database. Inoltre, non sono disponibili sezioni "Struttura del sito" e "Dashboard".
Altre variazioni
- Aggiunta la possibilità di evidenziare e copiare negli appunti i valori delle celle di Ctrl+A.
- Accelerato l'operazione di rimozione dei progetti (per la rimozione completa dei progetti è necessario fare una compressione del database tramite il menu del programma).
- Risolto il problema con non sempre corretto conteggio vuote tag H1.
- Risolto il problema con non sempre corretto parsing attributo «title» le immagini.
- Risolto il blocco del programma quando si sposta al record durante la scansione.
Non ci fermiamo qui e già preparando per voi una nuova pedina, che abbiamo in programma di rilasciare al più presto.
Rimanete sintonizzati! :-)
Vota l'articolo
0/5
0


















