





















 1,473
1,473Bonjour à tous! Nous sommes de retour en affaires!
Après une très longue période, nous avons enfin préparé une nouvelle version de SiteAnalyzer, qui, nous l'espérons, saura répondre à vos attentes et deviendra un assistant indispensable dans la promotion SEO.
Dans la nouvelle version de SiteAnalyzer, nous avons implémenté plusieurs des fonctions les plus demandées par les utilisateurs, telles que : le grattage de données (extraction de données du site), la vérification de l'unicité du contenu et la vérification de la vitesse de chargement des pages par Google PageSpeed. Dans le même temps, de nombreux bugs ont été corrigés et le logo a été redessiné. Parlons de tout plus en détail.

Les principaux changements
1. Grattage de données avec XPath, CSS, XQuery, RegEx.
Le grattage Web est un processus automatisé d'extraction de données des pages d'intérêt sur le site selon certaines règles.
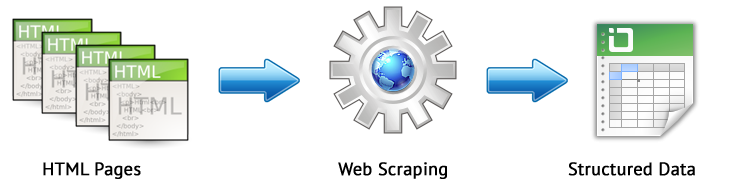
Les principales méthodes de grattage Web sont les méthodes d'analyse utilisant XPath, les sélecteurs CSS, XQuery, RegExp et les modèles HTML.
- XPath est un langage de requête spécial pour les éléments de document XML / XHTML. Pour accéder aux éléments, XPath utilise la navigation DOM en décrivant le chemin d'accès à l'élément souhaité sur la page. Avec son aide, vous pouvez obtenir la valeur d'un élément par son numéro ordinal dans le document, extraire son contenu textuel ou son code interne, vérifier la présence d'un élément spécifique sur la page.
- Les sélecteurs CSS sont utilisés pour rechercher un élément de sa partie (attribut). CSS est syntaxiquement similaire à XPath, mais dans certains cas, les localisateurs CSS sont plus rapides et sont plus descriptifs et concis. L'inconvénient de CSS est qu'il ne fonctionne que dans une seule direction - plus profondément dans le document. XPath, en revanche, fonctionne dans les deux sens (par exemple, vous pouvez rechercher un élément parent par un enfant).
- XQuery est basé sur XPath. XQuery imite XML, ce qui vous permet de créer des expressions imbriquées d'une manière qui n'est pas possible dans XSLT.
- RegExp est un langage de recherche formel permettant d'extraire des valeurs à partir d'un ensemble de chaînes de texte qui correspondent aux conditions requises (expression régulière).
- Les modèles HTML sont un langage d'extraction de données à partir de documents HTML, qui est une combinaison de balisage HTML pour décrire le modèle de recherche pour le fragment souhaité, ainsi que des fonctions et opérations pour extraire et transformer des données.
En règle générale, le grattage est utilisé pour résoudre des tâches difficiles à gérer manuellement. Cela peut être l'extraction de descriptions de produits pour créer une nouvelle boutique en ligne, le grattage d'études marketing pour surveiller les prix ou pour surveiller les publicités.

Dans SiteAnalyzer, le scraping est configuré dans l'onglet Data Extraction, où les règles d'extraction sont configurées. Les règles peuvent être enregistrées et, si nécessaire, modifiées.
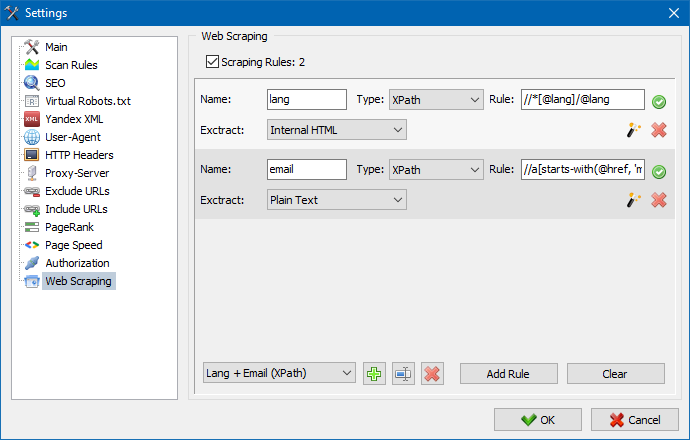
Il existe également un module de test de règles. À l'aide du débogueur de règles intégré, vous pouvez obtenir rapidement et facilement le contenu HTML de n'importe quelle page du site et tester le travail des requêtes, puis utiliser les règles déboguées pour analyser les données dans SiteAnalyzer.

Une fois l'extraction des données terminée, toutes les informations collectées peuvent être exportées vers Excel.
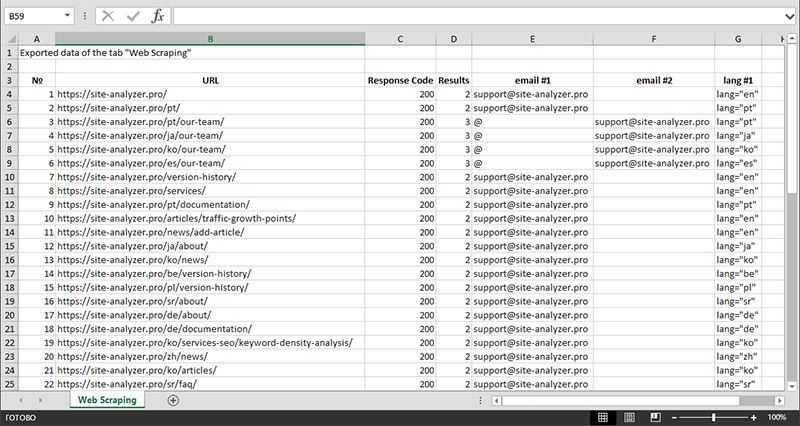
Pour une étude plus détaillée du fonctionnement du module et une liste des règles et expressions régulières les plus courantes, consultez l'article
2. Vérification de l'unicité du contenu au sein du site.
Cet outil vous permet de rechercher les pages en double et de vérifier l'unicité des textes au sein du site. En d'autres termes, il s'agit d'une vérification par lots d'un groupe d'URL pour l'unicité entre elles.
Cela peut être utile dans les cas suivants :
- Pour rechercher des pages dupliquées complètes (par exemple, une page avec des paramètres et la même page, mais dans la vue CNC).
- Pour rechercher des correspondances partielles de contenu (par exemple, deux recettes de bortsch dans un blog culinaire, qui se ressemblent à 96%, ce qui suggère que l'un des articles doit être supprimé afin de se débarrasser d'une éventuelle cannibalisation du trafic).
- Lorsque, sur un site d'articles, vous avez accidentellement écrit un article sur un sujet que vous avez déjà écrit il y a 10 ans. Dans ce cas, notre outil détectera également un doublon d'un tel article.
Le principe de l'outil de vérification de l'unicité des contenus est simple : le programme télécharge leur contenu à partir de la liste des URL du site, reçoit le contenu texte de la page (sans le bloc HEAD et sans balises HTML), puis les compare avec chacun autre en utilisant l'algorithme de shingle.

Ainsi, à l'aide de bardeaux, nous déterminons l'unicité des pages et pouvons calculer à la fois des doublons complets de pages avec 0% d'unicité et des doublons partiels avec divers degrés d'unicité du contenu du texte. Le programme fonctionne avec une longueur de bardeau de 5.
Vous pouvez en savoir plus sur le fonctionnement du module dans cet article.: >>
3. Vérification de la vitesse de chargement des pages par Google PageSpeed.
L'outil PageSpeed Insights du géant de la recherche Google vous permet de vérifier la vitesse de chargement de certains éléments de la page et affiche également le score global de vitesse de chargement des URL d'intérêt pour les versions de bureau et mobile du navigateur.

L'outil de Google est bon pour tout le monde, cependant, il présente un inconvénient important - il ne vous permet pas de créer des vérifications d'URL de groupe, ce qui crée des inconvénients lors de la vérification de nombreuses pages de votre site : acceptez que vérifier manuellement la vitesse de téléchargement pour 100 URL ou plus sur une page est une corvée et peut prendre beaucoup de temps.
Par conséquent, nous avons créé un module qui vous permet de créer gratuitement des contrôles de groupe de la vitesse de chargement des pages via une API spéciale dans l'outil Google PageSpeed Insights.

Principaux paramètres analysés :
- FCP (First Contentful Paint) – le temps d'afficher le premier contenu.
- SI (Speed Index) – un indicateur de la rapidité avec laquelle le contenu est affiché sur une page.
- LCP (Largest Contentful Paint) – temps d'affichage du plus grand élément de la page.
- TTI (Time to Interactive) – le temps pendant lequel la page devient entièrement prête pour l'interaction de l'utilisateur.
- TBT (Total Blocking Time) – entre le premier rendu du contenu et sa préparation à l'interaction avec l'utilisateur.
- CLS (Cumulative Layout Shift) – décalage de mise en page cumulatif. Sert à mesurer la stabilité visuelle de la page.
En raison du travail multithread de SiteAnalyzer, la vérification de centaines ou plus d'URL ne peut prendre que quelques minutes, ce qui peut prendre un jour ou plus en mode manuel via un navigateur.
Dans le même temps, l'analyse de l'URL elle-même s'effectue en quelques clics, après quoi un rapport peut être téléchargé, comprenant les principales caractéristiques des contrôles sous une forme pratique dans Excel.
Tout ce dont vous avez besoin pour commencer est d'obtenir une clé API.
Comment faire cela est décrit dans cet article. >>
4. Ajout de la possibilité de regrouper les projets par dossiers.
Pour une navigation plus pratique dans la liste des projets, la possibilité de regrouper les sites par dossiers a été ajoutée.

De plus, il est devenu possible de filtrer la liste des projets par nom.
5. L'interface des paramètres du programme a été mise à jour.
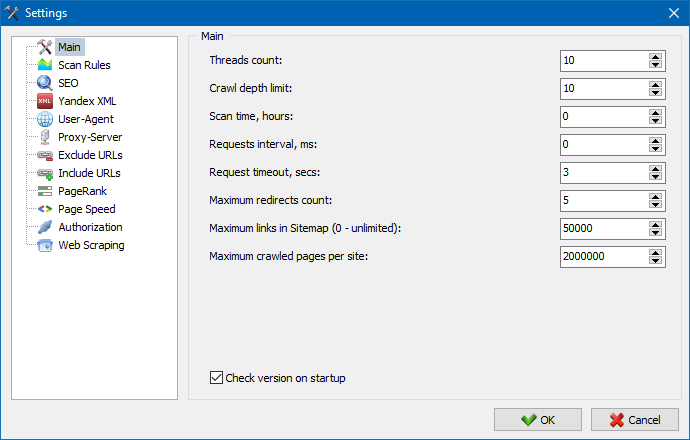
Avec l'extension des fonctionnalités du programme, il est devenu "serré" pour nous d'utiliser des onglets, nous avons donc reformaté la fenêtre des paramètres dans une interface plus compréhensible et fonctionnelle.
Remarques:
- correction de la comptabilisation incorrecte des exceptions d'URL
- correction de la comptabilisation incorrecte de la profondeur d'exploration du site
- affichage restauré des redirections pour les URL importées d'un fichier
- restauré la possibilité de réorganiser et de mémoriser l'ordre des colonnes dans les onglets
- comptabilité restaurée des pages non canoniques, résolution du problème avec les balises meta vides
- affichage restauré des ancres de lien dans l'onglet Info
- importation accélérée d'un grand nombre d'URL à partir du presse-papiers
- correction de l'analyse pas toujours correcte du titre et de la description
- affichage restauré de l'alt et du titre dans les images
- gel fixe lors du passage à l'onglet "Liens externes" lors de la numérisation d'un projet
- correction de l'erreur qui se produisait lors du basculement entre les projets et de la mise à jour des nœuds de l'onglet "Statistiques d'exploration du site"
- correction de la définition incorrecte du niveau d'imbrication pour l'URL avec des paramètres
- tri des données fixes par champ de hachage HTML dans la table principale
- travail optimisé du programme avec les domaines cyrilliques
- interface des paramètres du programme mise à jour
- conception de logo mise à jour

Présentation des versions précédentes:
- Présentation de la nouvelle version de SiteAnalyzer 2.2
- Présentation de la nouvelle version de SiteAnalyzer 2.1
- Présentation de la nouvelle version de SiteAnalyzer 2.0


















