





















 2,512
2,512Ahoj všichni! Jsme zpět v práci!
Po velmi dlouhém období jsme konečně připravili nové vydání SiteAnalyzer, které, jak doufáme, splní vaše očekávání a stane se nepostradatelným pomocníkem při SEO propagaci.
V nové verzi SiteAnalyzer jsme implementovali několik nejžádanějších funkcí uživatelů, například: škrábání dat (extrakce dat z webu), kontrola jedinečnosti obsahu a kontrola rychlosti načítání stránky pomocí Google PageSpeed. Současně bylo opraveno mnoho chyb a logo bylo upraveno. Promluvme si o všem podrobněji.

Hlavní změny
1. Škrábání dat pomocí XPath, CSS, XQuery, RegEx.
Web scraping je automatizovaný proces extrakce dat ze stránek, které vás zajímají, podle určitých pravidel.
Hlavní metody škrábání webu jsou metody analýzy pomocí šablon XPath, CSS, XQuery, RegExp a HTML.
- XPath je speciální dotazovací jazyk pro prvky dokumentu XML / XHTML. Pro přístup k prvkům používá XPath navigaci DOM popisem cesty k požadovanému prvku na stránce. S jeho pomocí můžete získat hodnotu prvku podle jeho pořadového čísla v dokumentu, extrahovat jeho textový obsah nebo interní kód, zkontrolovat přítomnost konkrétního prvku na stránce.
- Selektory CSS se používají k vyhledání prvku jeho části (atributu). CSS je syntakticky podobný XPath, ale v některých případech jsou vyhledávače CSS rychlejší a jsou popisnější a stručnější. Nevýhodou CSS je, že funguje pouze jedním směrem - hlouběji do dokumentu. XPath na druhou stranu funguje oběma způsoby (například můžete vyhledat nadřazený prvek dítětem).
- XQuery je založen na XPath. XQuery napodobuje XML, což vám umožňuje vytvářet vnořené výrazy způsobem, který není v XSLT možný.
- RegExp je formální vyhledávací jazyk pro extrakci hodnot ze sady textových řetězců, které odpovídají požadovaným podmínkám (regulární výraz).
- Šablony HTML je jazyk pro extrakci dat z dokumentů HTML, což je kombinace značek HTML popisujících vyhledávací šablonu pro požadovaný fragment, plus funkce a operace pro extrakci a transformaci dat.
Škrábání se obvykle používá k řešení úkolů, které je obtížné zvládnout ručně. Může to být extrahování popisů produktů k vytvoření nového online obchodu, škrábání v marketingovém výzkumu za účelem sledování cen nebo sledování reklam.

V SiteAnalyzer je škrábání konfigurováno na kartě Extrakce dat, kde jsou nakonfigurována pravidla extrakce. Pravidla lze uložit a v případě potřeby upravit.
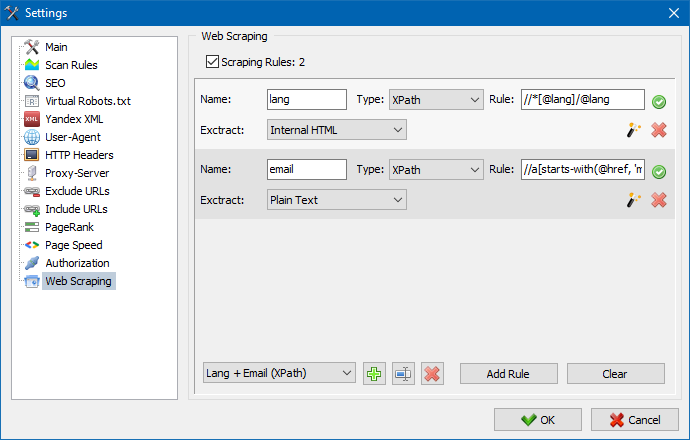
K dispozici je také modul testování pravidel. Pomocí integrovaného ladicího programu pravidel můžete rychle a snadno získat obsah HTML jakékoli stránky na webu a otestovat práci dotazů a poté použít laděná pravidla pro analýzu dat v SiteAnalyzer.

Po dokončení extrakce dat lze všechny shromážděné informace exportovat do aplikace Excel.
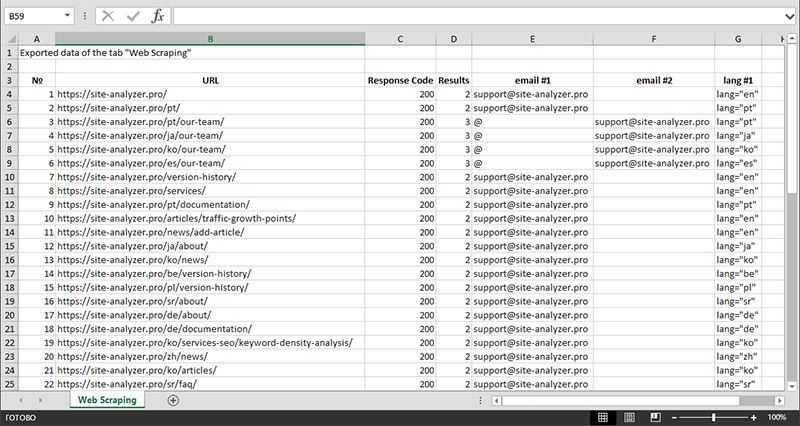
Podrobnější studii fungování modulu a seznam nejběžnějších pravidel a regulárních výrazů najdete v článku
2. Kontrola jedinečnosti obsahu na webu.
Tento nástroj umožňuje vyhledávat duplicitní stránky a kontrolovat jedinečnost textů na webu. Jinými slovy se jedná o hromadnou kontrolu skupiny adres URL, aby byla mezi nimi jedinečnost.
To může být užitečné v případech:
- Chcete-li vyhledat úplné duplicitní stránky (například stránku s parametry a stejnou stránkou, ale v zobrazení CNC).
- Chcete-li vyhledat částečné shody obsahu (například dva recepty boršč v kulinářském blogu, které jsou navzájem na 96% podobné, což naznačuje, že jeden z článků by měl být odstraněn, aby se zbavil možné kanibalizace provozu).
- Když jste na webu s článkem omylem napsali článek na téma, které jste napsali již před 10 lety. V tomto případě náš nástroj také detekuje duplikát takového článku.
Princip nástroje pro kontrolu jedinečnosti obsahu je jednoduchý: program stáhne jejich obsah ze seznamu adres URL webových stránek, obdrží textový obsah stránky (bez bloku HEAD a bez značek HTML) a poté je porovná s každým ostatní pomocí šindelového algoritmu.

Pomocí šindelů tedy určujeme jedinečnost stránek a můžeme vypočítat jak úplné duplikáty stránek s 0% jedinečností, tak i částečné duplikáty s různým stupněm jedinečnosti textového obsahu. Program pracuje s délkou šindele 5.
Další informace o tom, jak modul funguje, se dozvíte v tomto článku.: >>
3. Kontrola rychlosti načítání stránek pomocí Google PageSpeed.
Nástroj PageSpeed Insights od společnosti Google Search gigant vám umožňuje zkontrolovat rychlost načítání určitých prvků stránky a také ukazuje celkové skóre rychlosti načítání adres URL, které vás zajímají pro verzi prohlížeče pro stolní počítače a mobilní zařízení.

Nástroj Google je vhodný pro každého, má však jednu významnou nevýhodu - neumožňuje vytvářet kontroly skupinových adres URL, což způsobuje potíže při kontrole mnoha stránek vašeho webu: souhlaste s tím, že ruční kontrola rychlosti stahování pro 100 nebo více adres URL na jedna stránka je fuška a může to zabrat hodně času.
Proto jsme vytvořili modul, který vám umožňuje bezplatně vytvářet skupinové kontroly rychlosti načítání stránek prostřednictvím speciálního rozhraní API v nástroji Google PageSpeed Insights.

Hlavní analyzované parametry:
- FCP (First Contentful Paint) – čas pro zobrazení prvního obsahu.
- SI (Speed Index) – indikátor rychlosti zobrazení obsahu na stránce.
- LCP (Largest Contentful Paint) – doba zobrazení pro největší prvek na stránce.
- TTI (Time to Interactive) – doba, během níž je stránka plně připravena na interakci s uživatelem.
- TBT (Total Blocking Time) – doba od prvního vykreslení obsahu do jeho připravenosti na interakci s uživatelem.
- CLS (Cumulative Layout Shift) – kumulativní posun rozložení. Slouží k měření vizuální stability stránky.
Kvůli vícevláknové práci SiteAnalyzer může kontrola stovek a více adres URL trvat jen několik minut, což může v prohlížeči v ručním režimu trvat den nebo více.
Samotná analýza adresy URL současně probíhá pouhými několika kliknutími, po kterých lze stáhnout zprávu, včetně hlavních charakteristik kontrol ve vhodné formě v aplikaci Excel.
Vše, co potřebujete, je získat klíč API.
Postup je popsán v tomto článku. >>
4. Přidána možnost seskupovat projekty podle složek.
Pro pohodlnější procházení seznamem projektů byla přidána možnost seskupovat weby podle složek.

Kromě toho bylo možné filtrovat seznam projektů podle názvu.
5. Rozhraní nastavení programu bylo aktualizováno.
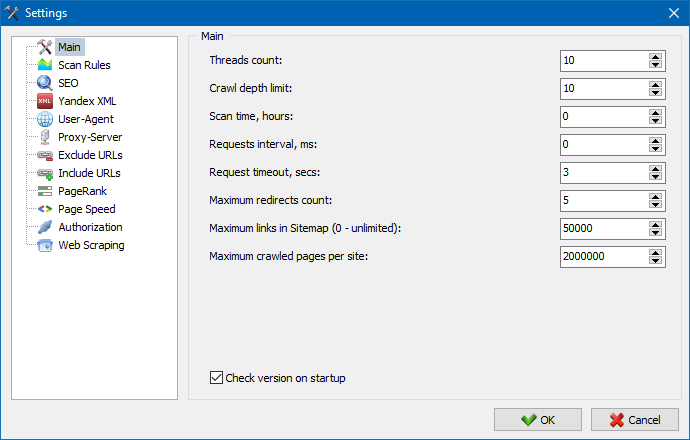
S rozšířením funkčnosti programu se nám "zpřísnilo" používání karet, a tak jsme okno nastavení přeformátovali na srozumitelnější a funkčnější rozhraní.
Poznámky:
- opraveno nesprávné účtování výjimek URL
- opraveno nesprávné účtování hloubky procházení stránek
- obnovené zobrazení přesměrování pro adresy URL importované ze souboru
- obnovila možnost přeskupit a zapamatovat si pořadí sloupců na kartách
- obnovené účtování nekanonických stránek, vyřešil problém s prázdnými metaznačkami
- obnovené zobrazení kotev odkazů na kartě Informace
- zrychlený import velkého počtu URL ze schránky
- opravena ne vždy správná analýza názvu a popisu
- obnovené zobrazení alt a názvu v obrázcích
- opraveno pozastavení při přepínání na kartu "Externí odkazy" během skenování projektu
- opravena chyba, ke které došlo při přepínání mezi projekty a aktualizaci uzlů na kartě "Statistiky procházení webů"
- opravena nesprávná definice úrovně vnoření pro URL s parametry
- opravené třídění dat podle hashovacího pole HTML v hlavní tabulce
- optimalizovaná práce programu s doménami cyrilice
- aktualizované rozhraní nastavení programu
- aktualizovaný design loga

Přehled předchozích verzí:
- Recenze nové verze SiteAnalyzer 2.2
- Recenze nové verze SiteAnalyzer 2.1
- Recenze nové verze SiteAnalyzer 2.0


















