





















Označení program
Program SiteAnalyzer je určen pro analýzu stránek a zjištění technických chyb (vyhledat nefunkční odkazy, duplicitní stránky, špatných odpovědí serveru), a také chyby a недоработок v SEO-optimalizaci (bianco meta tagy, přebytek je buď úplná absence titulků stránek h1, analýza obsahu stránky, kvalitní перелинковки a řadu dalších SEO parametrů).

Základní funkce
- Skenování všech stránek na webu, stejně jako vaše obrázky, skripty a dokumentů
- Získání kódy odezvy serveru pro každou stránku webu (200, 301, 302, 404, 500, 503 a, atd.)
- Definice dostupnosti a obsahu Title, Keywords, Description, H1-H6
- Vyhledávání a mapování "duplicitní" stránky, meta tagů a titulků
- Určení, zda atribut rel="canonical" pro každou stránku webu
- Podle směrnic souboru "robots.txt" jsou metaznačky "robots" nebo "X-Robots-Tag"
- Účtování "noindex" a "nofollow" při procházení stránek webu
- Škrábání dat pomocí XPath, CSS, XQuery, RegEx
- Kontrola jedinečnosti obsahu na webu
- Kontrola rychlosti načítání stránky pomocí Google PageSpeed
- Referenční analýza: definice interních a externích odkazů pro libovolnou stránku webu
- Výpočet interní PageRank pro každou stránku webu
- Vizualizace struktury webu v grafu
- Určení počtu přesměrování ze stránky (přesměrování)
- Zkontrolujte libovolné adresy URL a externí soubor Sitemap.xml
- Sitemap "sitemap.xml" generace (s možností rozdělení do několika souborů)
- Filtrování dat libovolným parametrem (flexibilní konfigurace filtrů libovolné složitosti)
- Vyhledejte na webu libovolný obsah
- Export zprávy do formátu CSV, Excel a PDF
Rozdíly od analogů
- Nízké požadavky na počítačových zdrojů, nízká spotřeba ram
- Skenování stránky pro prakticky jakékoli množství kvůli nízké požadavky na počítačových zdrojů
- Přenosný formát (funguje bez instalace na PC nebo přímo z vyměnitelného média)
Sekce dokumentace
- Začínáme
- Nastavení programu
- Základní nastavení
- Skenování
- SEO
- Soubor virtuálních robotů new
- Yandex XML
- User-Agent
- Libovolné HTTP hlavičky new
- Proxy-server
- Vyloučit adresu URL
- Sledujte adresu URL
- PageRank
- Autorizace
- Práce s programem
- Nastavení sloupců a karet
- Filtrování dat
- Technické statistiky stránek
- SEO statistiky
- Custom Filters
- Custom Search
- Škrábání dat
- Kontrola jedinečnosti obsahu
- Kontrola rychlosti načítání stránky
- Struktura stránek
- Kontextové menu seznamu projektů
- Vizualizace struktury webových stránek
- Graf distribuce interních odkazů
- Graf rychlosti načítání stránky
- Generování Sitemap.xml
- Skenování libovolných adres URL
- Dashboard
- Export dat
- Мультиязычность
- Komprese databáze
Začínáme
Při spuštění programu se uživatel k dispozici adresní řádek pro zadávání URL sledované stránky (můžete zadat libovolnou stránku webu, vyhledávací robot, klikněte na odkazy dané stránky chodilo celé webové stránky, včetně hlavní stránku, za předpokladu, že všechny odkazy jsou vyrobeny v HTML a ne pomocí Javascriptu).
Po kliknutí na tlačítko "Start", vyhledávací robot začne obcházet všechny stránky na interní odkazy (na externí zdroje on nechodí, také nechodí na odkazy, splněna na Javascript).
Poté, co robot předstihne všechny stránky webu, se stává dostupnou zprávu, dosažený v podobě tabulky a zobrazuje získané údaje jsou seskupeny podle témat вкладкам.
Všechny анализируемые projekty se zobrazují v levé části programu a automaticky uloženy v databázi programu spolu s nálezy. Pro odstranění zbytečných stránek pomocí místní nabídky seznamu projektů.
Poznámka:
- když kliknete na tlačítko "Pauza" scan projektu přerušena, souběžně s aktuální pokrok skenování, je uložen v databázi, která umožňuje, například, zavřít program a pokračovat ve skenování projektu po restartování programu od místa zastavení
- tlačítko "Stop" pro přerušení skenování aktuálního projektu bez možnosti pokračování jeho skenování
Nastavení programu
Sekce hlavního menu "Nastavení" je určen pro jemné nastavení program pracuje s externími weby a obsahuje 7 karet:

Sekce základní nastavení slouží pro indikaci programu vlastních směrnic používaných při procházení webu.
Popis parametrů:
- Počet vláken
- Čím je větší počet vláken, tím více URL schopen zpracovat za jednotku času. Při tom je nutné vzít v úvahu, že větší počet vláken vede k většímu počtu využívaných zdrojů PC. Je doporučeno nastavit počet vláken v rozmezí 5-10.
- Čas skenování
- Slouží k nastavení omezení skenování stránek v čase. Měří v hodinách.
- Maximální hloubka
- Tento parametr slouží k určení hloubky skenování stránky. Hlavní stránka webu má úroveň vnoření = 0. Například, pokud potřebujete skenovat stránky typu "somedomain.ru/catalog.html" a "somedomain.ru/catalog/tovar.html" v takovém případě je třeba nastavit na hodnotu maximální hloubky = 2.
- Zpoždění mezi dotazy
- Slouží k nastavení pauzy při projevech čtečky k prohlížení webu. To se stává nezbytné pro webové stránky na "slabé" хостингах, není выдерживающих velké zatížení a časté k nim doporučení.
- Časový limit dotazu
- Nastavení času čekání na odpověď webové stránky na dotaz program. Pokud je některý z vašich webových stránek reagují pomalu (dlouho грузятся), pak procházení stránek může trvat dost dlouhou dobu. Tyto stránky lze zahození, což naznačuje hodnota, po které skener přejde k procházení ostatních stránek webu a tím nebude zdržovat celkový pokrok.
- Počet čitelného stránek
- Omezení na maximální počet čitelného stránek. Je užitečné, pokud, například, budete muset procházet prvních N stránek (v tom nejsou započítány obrázky, soubory stylů, skripty a další typy souborů).

Vzít v úvahu obsah
- V této sekci lze vybrat typy údajů, které budou počítat zpracovávače při procházení stránek (obrázky, videa, styly, skripty), nebo vyloučit přebytečné informace při парсинге.
Pravidla skenování
- Toto nastavení souvisí s nastavením výjimek při procházení webu сканнером pomocí souboru "robots.txt" na odkazy typu "nofollow", a také pomocí směrnic "meta name=robots" přímo v kódu stránek.

Tato část slouží k zadání základních analyzovaných SEO parametry, které se dále budou promítat na korektnost při парсинге stránek, načež se získané údaje budou zobrazeny v záložce "Statistiky, SEO" v pravé části hlavního okna programu.
Pomocí těchto nastavení můžete zvolit službu, pomocí které budete kontrolovat indexaci stránek ve vyhledávači Yandex. Existují dvě možnosti pro kontrolu indexace: pomocí služby Yandex XML nebo služby Majento.ru.

Při výběru služby Yandex XML je třeba vzít v úvahu možné omezení (hodinové nebo denní), které lze použít při kontrole indexace stránek, pokud jde o stávající limity na vašem účtu Yandex, v důsledku čehož mohou často existovat situace, kdy limity vašeho účtu nebudou stačit ke kontrole všech Stránky najednou a za to budete muset počkat na další hodinu.
Při použití služby Majento.ru prakticky chybí hodinová nebo denní omezení, protože vaše omezení se doslova spojí do obecného limitu, který není sám o sobě malý, ale má také značně větší limit s hodinovými omezeními než kterýkoli z uživatelských účtů na Yandex XML.

Virtuální soubor robots.txt lze použít místo skutečného souboru robots.txt hostovaného na webu.
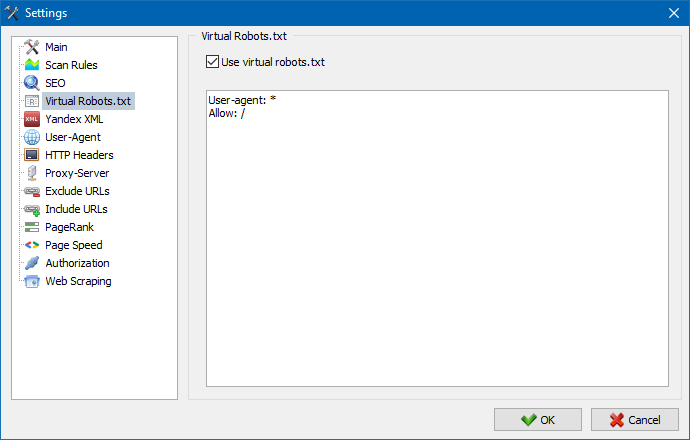
To se hodí při testování webu, kdy například potřebujete procházet určité sekce webu, které jsou uzavřené z indexování (nebo naopak – při procházení je nezohledňujte), přičemž nepotřebujete fyzicky vytvářet změny ve skutečném souboru robots.txt a věnujte tomu čas vývojáře.
Poznámka: při importu seznamu URL jsou brány v úvahu direktivy virtuálního robots.txt (pokud je tato možnost aktivována), jinak se pro seznam URL žádný robots.txt nebere v úvahu.
V sekci User-Agent lze uvést, jakým musí uživatel zadat kromě zvolení-agent hlášení program při přístupu k externím webům během jejich skenování. Na умочанию, nastavit uživatelské musí uživatel zadat kromě zvolení-agent, ale v případě potřeby si můžete vybrat jednu ze standardních látek, nejčastěji se vyskytující na internetu. Mezi nimi jsou takové, jako: boti vyhledávačů YandexBot, GoogleBot, MicrosoftEdge, roboty prohlížečů Chrome, Firefox, IE8, a také mobilních zařízení iPhone, Android a mnoho dalších.

Pomocí této možnosti můžete analyzovat reakci webu a stránek na různé požadavky. Někdo může například potřebovat poslat referera v požadavku, majitelé vícejazyčných stránek chtějí přenést Accept-Language | Charset | Encoding a někdo potřebuje přenášet neobvyklá data v hlavičkách Accept-Encoding, Cache-Control, Pragma. atd. NS.
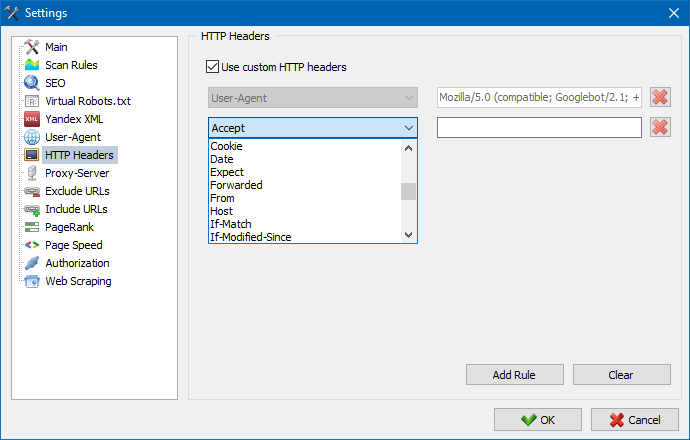
Pomocí této možnosti můžete analyzovat reakci webu a stránek na různé požadavky. Někdo může například potřebovat poslat referera v požadavku, majitelé vícejazyčných stránek chtějí přenést Accept-Language | Charset | Encoding a někdo potřebuje přenášet neobvyklá data v hlavičkách Accept-Encoding, Cache-Control, Pragma. atd. NS.
Pokud je potřeba pracovat přes proxy, pak v této sekci můžete přidat seznam proxy serverů, přes které bude program přistupovat k externím zdrojům. Navíc, tam je možnost ověření proxy na funkčnost, ale také funkce odstranění neaktivních proxy-serverů.

Tato sekce je určena pro vyloučení obcházení určitých stránek a částí webu při парсинге.
Použití vzorů vyhledávání * a ? můžete určit, které části webu by prolézací modul neměl procházet, a proto by neměly být zahrnuty do programové databáze. Tento seznam je místní seznamem výjimek na čas skenování stránky (ohledně něj "globální" seznam je soubor "robots.txt" v root webu).

Podobně můžete přidat adresy URL, které musí být prolézány. V takovém případě budou všechny ostatní adresy URL mimo tyto složky během kontroly ignorovány. Tato možnost funguje také s vyhledávacími vzory * a ?

Pomocí parametru PageRank můžete analyzovat navigační strukturu vašich webových stránek a optimalizovat systém interních vazeb webového zdroje pro přenos referenční hmotnosti na nejdůležitější stránky.

Program má dvě možnosti pro výpočet PageRank: klasický algoritmus a jeho modernější protějšek. Obecně platí, že pro analýzu interního propojení webu není velký rozdíl při použití prvního nebo druhého algoritmu, takže můžete použít libovolný ze dvou algoritmů.
Podrobný popis algoritmu a principy výpočtu PageRank lze nalézt v článku "Výpočet interní PageRank": >>

Zadejte přihlašovací jméno a heslo pro automatickou autorizaci na stránkách uzavřených přes .htpasswd a chráněných autorizací serveru BASIC.
Práce s programem
Po dokončení skenování uživatel se stává k dispozici informace uvedené v bloku "Základní informace". Každá karta obsahuje údaje seskupené o jejich titulů (např. záložka "Title" obsahuje obsah hlavičky stránky <title></title> záložka "Obrázky" obsahuje seznam všech obrázků, webových stránek, a tak dále). S pomocí těchto dat je možné provádět analýzu obsahu webu, najít "nefunkční odkazy nebo nesprávně vyplněné meta tagy.

V případě potřeby (například po provedení změn na webu) pomocí kontextového menu je k dispozici možnost nové skenování samostatných adres URL pro zobrazení změny v programu.
Pomocí tohoto menu je možné zobrazovat duplicitní stránky na příslušných parametrů (zdvojnásobuje za title, description, keywords, h1, h2, obsah stránek).

Položka "Znovu vyhledat adresu URL s kódem 0" je navržena tak, aby automaticky znovu zkontrolovala všechny stránky, které dávají kód odpovědi 0 (Časový limit čtení). Tento kód odezvy se obvykle zadává, když server nemá čas na doručení obsahu a připojení je ukončeno časovým limitem, stránku nelze načíst a nelze z ní extrahovat informace.
Nyní si můžete vybrat, které karty se budou zobrazovat v rozhraní základní údaje (konečně, to stalo se možné se rozloučit s morálně zastaralé kartě Meta Keywords). To je výhodné, pokud taba není vejde na obrazovce, nebo budete jen zřídka používat.

Sloupec lze skrýt nebo přesunout na požadované místo přetažením.
Zobrazení záložek a sloupců lze nastavit pomocí volání kontextové menu na panelu základní údaje. Zalamování sloupců se provádí pomocí myši.
Pro snadnější analýzu oblastí webových stránek v programu je k dispozici filtrování údajů. Filtrování je možné ve dvou variantách:
- podle všech polí s pomocí "rychlého" filtr
- pomocí laditelný filtr (s pomocí pokročilých nastavení vzorkování dat)
Rychlý filtr
Používá se pro rychlé filtrování dat a vztahuje se současně ke všem polí aktuální karty.

Přizpůsobitelné filtr
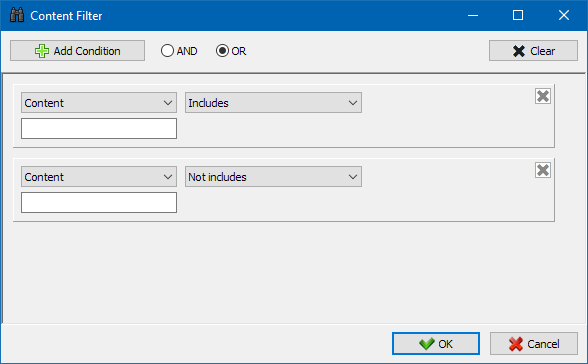
Je určen pro podrobné filtrování a může obsahovat současně několik podmínek. Například, pro meta tag "title" jdete filtrovat stránky podle jejich délky, aby to neměl překročit 70 znaků a současně obsahoval text "novinky". Pak tento filtr bude vypadat takto:

Tímto způsobem, za použití vysoce přizpůsobitelné filtr k žádné z karet můžete dostat vzorku dat jakékoliv složitosti.
Karta technických statistik webu se nachází na panelu Další údaje a obsahuje sadu základních technických parametrů webu: statistiky odkazů, metaznačky, kódy odpovědí na stránky, parametry indexování stránky, typy obsahu atd. parametry.
Kliknutím na některý z parametrů se automaticky filtrují na příslušné kartě dat karet a současně se na grafu v dolní části stránky zobrazují statistiky.

Karta SEO-statistiky je určena pro provádění plnohodnotných auditů lokality a obsahuje 50+ hlavních parametrů SEO a identifikuje více než 60 klíčových interních optimalizačních chyb! Mapování chyb je rozděleno do skupin, které naopak obsahují sady analyzovaných parametrů a filtrů, které detekují chyby na webu.
Podrobný popis všech ověřených parametrů naleznete v tomto článku. >>

Pro všechny výsledky filtrování je možné je rychle exportovat do aplikace Excel bez dalších dialogů (zpráva je uložena ve složce programu).
Na této záložce jsou umístěny přednastavené filtry, které umožňují vytvořit odběr pro všechny externí odkazy, chyby 404, obrázky a další parametry se všemi stránkami, na kterých jsou přítomny. Tak, nyní můžete snadno a rychle získat seznam externích odkazů a stránek, na nichž jsou umístěny, nebo vybrat všechny nefunkční odkazy, a okamžitě vidět, na jakých stránkách se nacházejí.

Všechny zprávy jsou k dispozici na programu v režimu on-line a zobrazí se na záložce "Custom" v panelu základní údaje. Navíc, tam je možnost jejich exportu do aplikace Excel přes hlavní menu.
Funkce prohledávání obsahu webu vám umožňuje prohledávat zdrojový kód a zobrazovat webové stránky s obsahem, který hledáte.
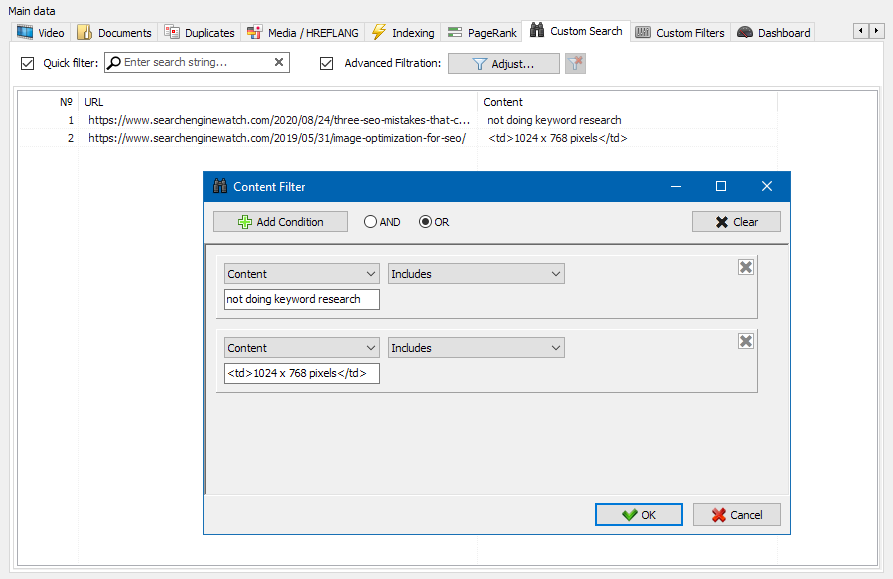
Modul vlastních filtrů vám umožňuje zkontrolovat přítomnost mikroznaček, metaznaček, analytických systémů, fragmentů volného textu nebo kódu HTML na webu.
V okně konfigurace filtru existuje několik parametrů pro vyhledávání určitých fragmentů textu na stránkách webu nebo naopak pro vyloučení stránek obsahujících určité fragmenty textu nebo fragmentů kódu HTML z výsledků vyhledávání (tato funkce je podobná hledání obsahu ve zdrojovém kódu stránky pomocí Ctrl-F) ...
Škrábání se obvykle používá k řešení úkolů, které je obtížné zvládnout ručně. Může to být extrahování popisů produktů k vytvoření nového online obchodu, škrábání v marketingovém výzkumu za účelem sledování cen nebo sledování reklam.

V SiteAnalyzer je škrábání konfigurováno na kartě Extrakce dat, kde jsou nakonfigurována pravidla extrakce. Pravidla lze uložit a v případě potřeby upravit.
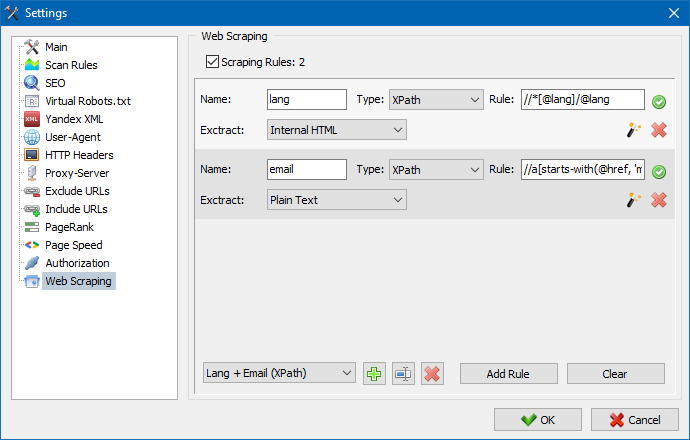
K dispozici je také modul testování pravidel. Pomocí integrovaného ladicího programu pravidel můžete rychle a snadno získat obsah HTML jakékoli stránky na webu a otestovat práci dotazů a poté použít laděná pravidla pro analýzu dat v SiteAnalyzer.

Po dokončení extrakce dat lze všechny shromážděné informace exportovat do aplikace Excel.
Podrobnější studii fungování modulu a seznam nejběžnějších pravidel a regulárních výrazů najdete v článku
Tento nástroj umožňuje vyhledávat duplicitní stránky a kontrolovat jedinečnost textů na webu. Jinými slovy se jedná o hromadnou kontrolu skupiny adres URL, aby byla mezi nimi jedinečnost.
To může být užitečné v případech:
- Chcete-li vyhledat úplné duplicitní stránky (například stránku s parametry a stejnou stránkou, ale v zobrazení CNC).
- Chcete-li vyhledat částečné shody obsahu (například dva recepty boršč v kulinářském blogu, které jsou navzájem na 96% podobné, což naznačuje, že jeden z článků by měl být odstraněn, aby se zbavil možné kanibalizace provozu).
- Když jste na webu s článkem omylem napsali článek na téma, které jste napsali již před 10 lety. V tomto případě náš nástroj také detekuje duplikát takového článku.
Princip nástroje pro kontrolu jedinečnosti obsahu je jednoduchý: program stáhne jejich obsah ze seznamu adres URL webových stránek, obdrží textový obsah stránky (bez bloku HEAD a bez značek HTML) a poté je porovná s každým ostatní pomocí šindelového algoritmu.

Pomocí šindelů tedy určujeme jedinečnost stránek a můžeme vypočítat jak úplné duplikáty stránek s 0% jedinečností, tak i částečné duplikáty s různým stupněm jedinečnosti textového obsahu. Program pracuje s délkou šindele 5.
Další informace o tom, jak modul funguje, se dozvíte v tomto článku.: >>
Kontrola rychlosti načítání stránky
Nástroj PageSpeed Insights od společnosti Google Search gigant vám umožňuje zkontrolovat rychlost načítání určitých prvků stránky a také ukazuje celkové skóre rychlosti načítání adres URL, které vás zajímají pro verzi prohlížeče pro stolní počítače a mobilní zařízení.

Nástroj Google je vhodný pro každého, má však jednu významnou nevýhodu - neumožňuje vytvářet kontroly skupinových adres URL, což způsobuje potíže při kontrole mnoha stránek vašeho webu: souhlaste s tím, že ruční kontrola rychlosti stahování pro 100 nebo více adres URL na jedna stránka je fuška a může to zabrat hodně času.
Proto jsme vytvořili modul, který vám umožňuje bezplatně vytvářet skupinové kontroly rychlosti načítání stránek prostřednictvím speciálního rozhraní API v nástroji Google PageSpeed Insights.

Hlavní analyzované parametry:
- FCP (First Contentful Paint) – čas pro zobrazení prvního obsahu.
- SI (Speed Index) – indikátor rychlosti zobrazení obsahu na stránce.
- LCP (Largest Contentful Paint) – doba zobrazení pro největší prvek na stránce.
- TTI (Time to Interactive) – doba, během níž je stránka plně připravena na interakci s uživatelem.
- TBT (Total Blocking Time) – doba od prvního vykreslení obsahu do jeho připravenosti na interakci s uživatelem.
- CLS (Cumulative Layout Shift) – kumulativní posun rozložení. Slouží k měření vizuální stability stránky.
Samotná analýza adresy URL současně probíhá pouhými několika kliknutími, po kterých lze stáhnout zprávu, včetně hlavních charakteristik kontrol ve vhodné formě v aplikaci Excel.
Vše, co potřebujete, je získat klíč API.
Postup je popsán v tomto článku. >>
Tento funkcionál je určen pro vytvoření struktury stránek na základě získaných údajů. Struktura stránek je generován na základě vnořených URL stránek. Po generování vzorů je k dispozici její export do CSV-formátu (Excel).

Kontextové menu seznamu projektů
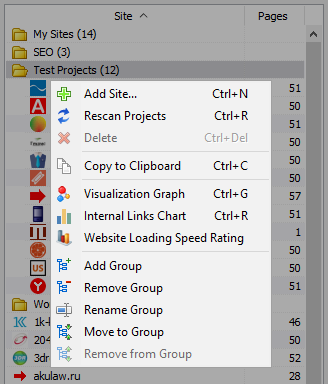
- V seznamu projektů je k dispozici hromadné skenování tak, že vyberete požadované webové stránky a kliknutí na tlačítko "Пересканировать". Poté, co jsou všechny stránky jsou v řadě a naskenované střídavě ve standardním režimu.
- Také, pro pohodlí práce s programem, hromadné odstranění vybraných stránek je také k dispozici na tlačítko "Odstranit".
- Kromě jediného skenování stránky, tam je možnost hromadného přidání stránek na seznam projektů pomocí speciálního formuláře, po kterém může uživatel procházet zajímavé projekty zcela.
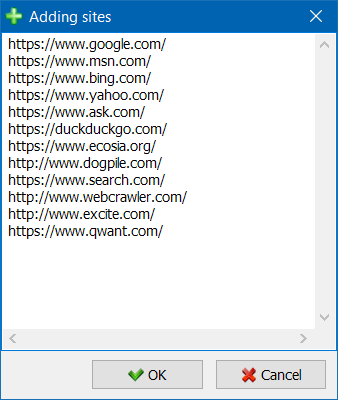
- Pro pohodlnější procházení seznamem projektů je možné weby seskupovat podle složek a filtrovat seznam projektů podle názvu.

Vizualizace struktury webových stránek
Režim vizualizace referenčních vazeb na grafu vám SEO specialista posoudit rozdělení vnitřního PageRank na stránkách, a také pochopit, jaké stránky si hodně referenční hmotnost (a, respektive, větší vnitřní referenční hmotnost v očích vyhledávačů), a jak se jednotlivé stránky a sekce webu chybí vnitřní odkazy.

Pomocí režimu vizualizace struktury webu, SEO-specialista schopen dostatečně posoudit to, jak je organizována interní perelinkovka na webových stránkách, a také prostřednictvím vizuální reprezentace hmoty PageRank, přiřazeno tím nebo jiným stranám, rychle provádět úpravy v aktuální propojení webových stránek a tím zvýšení relevance požadované stránky.
V levé části okna vizualizace jsou základní nástroje pro práci s grafem:
- změní měřítko na grafu
- twist hraběte na libovolný úhel
- přepínání oken je graf v režimu celé obrazovky (také pracuje na klávesu F11)
- zobrazení / skrytí popisků k počítačům (Ctrl-T)
- zobrazení / skrytí šipek u linek
- zobrazení / skrytí odkazů na externí zdroje (Ctrl-E)
- přepínání režimu barevného schéma Den / Noc (Ctrl-D)
- zobrazení / skrytí legendy a graf statistiky (Ctrl-L)
- uložení grafu ve formátu PNG (Ctrl-S)
- okno nastavení vizualizace (Ctrl-O)
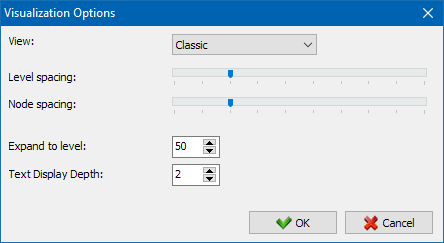
Sekce "Vzhled" je určen pro změnu formátu zobrazení uzlů v grafu. V režimu kreslení uzlů "PageRank", rozměry uzly jsou nastaveny s ohledem na jejich dřívější počítá skóre PageRank, což vede na grafu lze jasně vidět, jaké stránky mají vyšší referenční hmotnost, a jak se vede nejméně odkazů.
V klasickém režimu rozměry uzly jsou nastaveny na zvolené měřítko grafu vizualizace.
Graf distribuce interních odkazů
Tento graf ukazuje distribuci hmoty interního odkazu na stránkách webu (můžeme říci, že se jedná o vizualizaci propojení ve vizuální podobě, spíše než je prezentováno ve vizualizačním grafu). Číst více >>
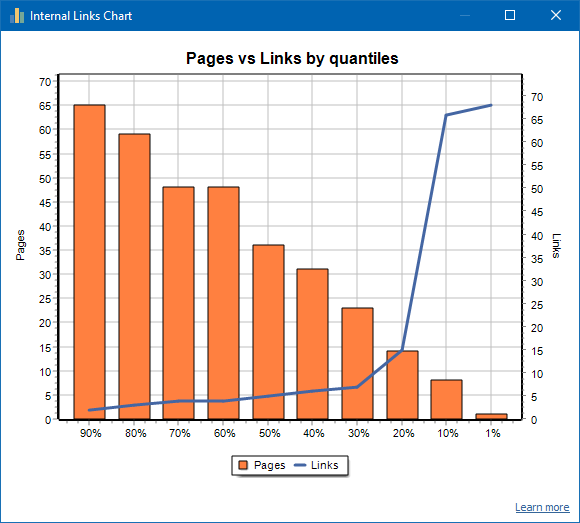
Vlevo je počet stránek, vpravo je počet odkazů. Níže jsou uvedeny procentuální kvantily podle stránky. Při sestavování grafu se duplicitní odkazy zahodí (pokud existují 3 odkazy ze stránky A na stránku B, pak je počítáme jako jeden).
Například na základě výše uvedeného snímku obrazovky pro web s přibližně 70 stránkami:
- 1% stránky mají ~68 příchozí odkazy.
- 10% stránky mají ~66 příchozí odkazy.
- 20% stránky mají ~15 příchozí odkazy.
- 30% stránky mají ~8 příchozí odkazy.
- 40% stránky mají ~7 příchozí odkazy.
- 50% stránky mají ~6 příchozí odkazy.
- 60% stránky mají ~5 příchozí odkazy.
- 70% stránky mají ~5 příchozí odkazy.
- 80% stránky mají ~3 příchozí odkazy.
- 90% stránky mají ~2 příchozí odkazy.
To znamená, že pokud vidíme, že máme stránky, na které vede méně než 10 příchozích odkazů, můžeme takové stránky považovat za slabě propojené a 60% stránek máme normálně propojených. Na základě toho můžeme buď dát více interních odkazů na tyto slabě odkazované stránky (pokud jsou stránky důležité pro propagaci), nebo ponechat tak, jak jsou, pokud mají takové stránky malý význam a nízkou prioritu.
V obecné praxi je méně pravděpodobné, že by stránky s méně než 10 interními odkazy procházely roboty vyhledávačů, zejména roboty Google.
Pokud tedy uvidíte web, který má pouze 20–30% stránek normálně propojených z celkového počtu stránek na webu, pak má smysl ponořit se do nastavení propojení nebo přemýšlet o tom, jak se vypořádat s těmito 80–70% slabě odkazovaných stránek (smazat, skrýt před indexování, přesměrování).
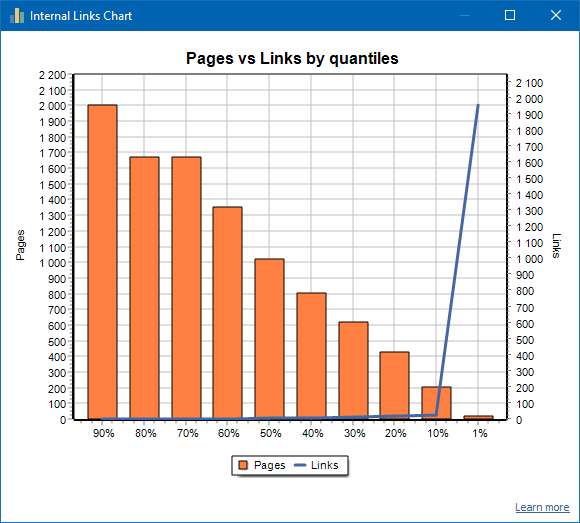
Příklad slabě propojeného webu:
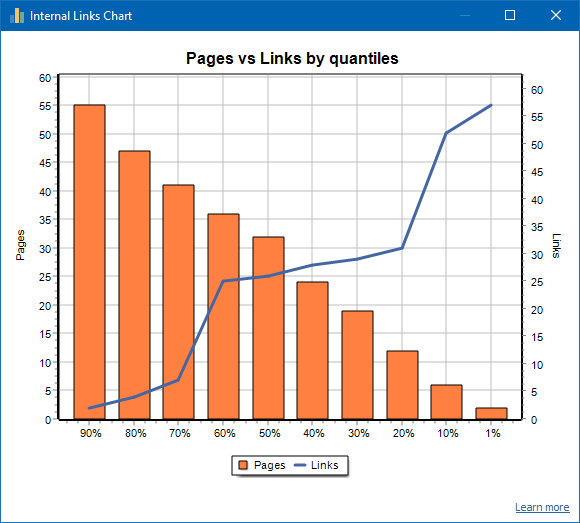
Příklad dobře propojeného webu:
Graf rychlosti načítání stránky
Graf rychlosti načítání stránky vám umožňuje vyhodnotit výkon webu. Pro přehlednost jsou stránky rozděleny do skupin a časových intervalů s krokem 100 milisekund.
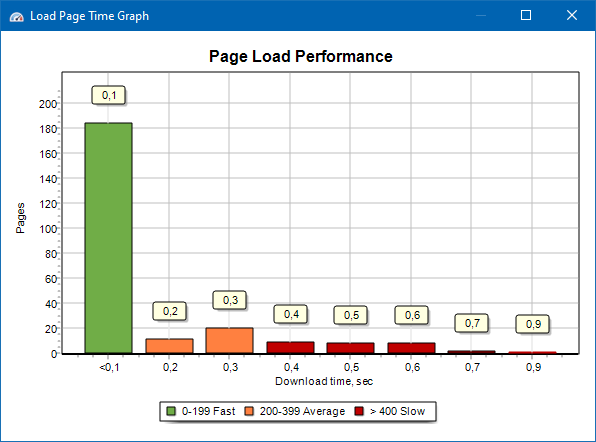
Na základě grafu tedy můžete určit, jaký podíl stránek webu se načte rychle (během 0-100 milisekund), které při průměrné rychlosti (100-200 milisekund) a které stránky se načtou dostatečně dlouho (400 milisekund nebo více).
Poznámka: Zobrazený čas je čas na načtení zdrojového kódu HTML, nikoli čas na úplné načtení stránek (vykreslování stránky a načítání prvků stránky, jako jsou obrázky a styly, nejsou brány v úvahu).
Generování Sitemap.xml
Soubor Sitemap je generován na základě procházených stránek nebo obrázků webů.
- Při generování souboru Sitemap skládajícího se ze stránek se k němu přidají stránky ve formátu "text / html".
- Při generování souboru Sitemap sestávajícího z obrázků se k němu přidají obrázky JPG, PNG, GIF a podobné.
Vygenerovat mapu stránek je možné ihned po skenování stránek, přes hlavní menu: položka "Projekty -> Generovat Sitemap".

Pro webové stránky velké množství, od 50 000 stránek, je k dispozici funkce automatického rozdělování "sitemap.xml" na několik souborů (v tomto případě je základní soubor obsahuje odkazy na další, které obsahují přímo odkazy na stránky vašeho webu). To souvisí s požadavky vyhledávačů pro zpracování souborů sitemap větších rozměrů.

Pokud je to nutné, objem stránek v souboru "sitemap.xml" lze měnit změnou hodnoty 50 000 (to je výchozí nastavení) na požadované hodnoty v hlavním nastavení programu.
Skenování libovolných adres URL
Položka menu "Import URL" je určen pro skenování libovolných seznamů URL, stejně jako XML mapy stránek Sitemap.xml (včetně indexu) pro jejich pozdější analýzu.
Skenování libovolné URL je možné třemi způsoby:
- tím, že vloží seznam adres URL ze schránky
- pro zavádění z pevného disku soubory ve formátu *.txt a *.xml, které obsahují seznamy URL
- tím, že stahování souboru Sitemap.xml přímo z webových stránek
Rysem tohoto režimu je, že při procházení libovolné URL-it-yourself "projekt" není uložena v programu a údaje o ní není přidán do databáze. Také není k dispozici sekce "Struktura stránek" a "Дашборд".
Podrobněji se seznámit s prací na položku "Import URL" můžete v tomto článku: Recenze nové verze SiteAnalyzer 1.9.
Dashboard
Záložka "Dashboard", zobrazí podrobnou zprávu o kvalitě optimalizace webových stránek. Sestava je generována na základě dat záložky "Statistiky, SEO". Kromě těchto dat ve zprávě je přítomen údaj o celkové výši kvalitní optimalizace webových stránek, vypočítá na 100 bodovou stupnici relativně současná míry jeho optimalizaci. Je k dispozici možnost exportu dat karty "Дашборд" v uživatelsky přívětivé zpráva ve formátu PDF.

Export dat
Pro pružnější analýzy získaných dat je možné jejich vypouštění do CSV-formátu (je exportován aktuální aktivní karta), a také generuje plnohodnotné sestavy v aplikaci Microsoft Excel se všemi kartami v jednom souboru.

Při exportu dat do aplikace Excel se zobrazí speciální okno, ve kterém uživatel může vybrat dotazy, které sloupce a pak vygenerovat zprávu s potřebnými údaji.

Mnohojazyčnost
V programu je k dispozici možnost výběru preferovaného jazyka, v němž bude probíhat práce.
Hlavní podporované jazyky: angličtina, ruština, němčina, italština, španělština, francouzština... program V současné době přeložena do více než patnáct (15) nejvíce populárních jazyků.

Pokud chcete přeložit program do svého rodného jazyka, pak stačí převést každý soubor "*.lng" na požadovaný jazyk, poté přeložený soubor je třeba poslat na adresu "support@site-analyzer.pro" (poznámky k dopisu by měla být napsána v ruštině nebo angličtině) a svůj překlad, bude zahrnuta v nové verzi programu.
Podrobnější návod na překlad programu v jazycích se nachází v distribuci (soubor "lcids.txt").
P.S. Pokud máte připomínky na kvalitu překladu - hlaste připomínky a opravy na "support@site-analyzer.ru".
Komprese databáze
Položka hlavního menu "Komprimovat databáze" je určen pro provedení operace balení databáze (čištění databáze od dříve odstraněných projektů, stejně jako uspořádání dat (obdoba defragmentace dat na osobních počítačích)).
Tento postup je efektivní v případě, kdy například z programu byl zrušen velký projekt, který obsahuje velké množství záznamů. Obecně se doporučuje provádět pravidelné komprese dat, jak se zbavit nadbytečných dat a snížení objemu databáze.
S odpověďmi na ostatní otázky se můžete seznámit v sekci FAQ >>




















