





















 1,990
1,990У версіі 1.9 дададзеная магчымасць сканавання адвольных спісаў URL, а таксама XML-карт сайта Sitemap.xml (у тым ліку і індэксных) для іх наступнага аналізу на прадмет пошуку "бітых" спасылак, некарэктных мета-тэгаў, пустых загалоўкаў і таму падобных памылак.
Асноўныя змены
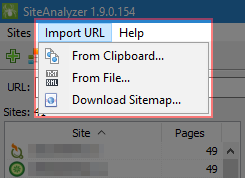
Дададзеная магчымасць сканавання спісу адвольных URL, выкарыстоўваючы буфер абмену або загрузку URL з файла на дыску.
- Буфер абмену. Самы просты і хуткі варыянт сканавання адвольных URL - праз буфера абмену. Маючы ў буферы абмену спіс URL для аналізу, вы выбіраеце ў меню праграмы пункт "Імпарт URL" -> "З буфера абмену", пасля чаго праграма аўтаматычна капіюе змесціва буфера абмену ў асобную форму, у якой вы можаце дадаць новыя небудзь адрэдагаваць бягучыя URL. Пасля націску на кнопку, ОК спіс URL дадаецца ў праграму, пасля чаго пачынаецца іх сканаванне, аналагічна таму, як калі б вы сканавалі звычайны сайт.
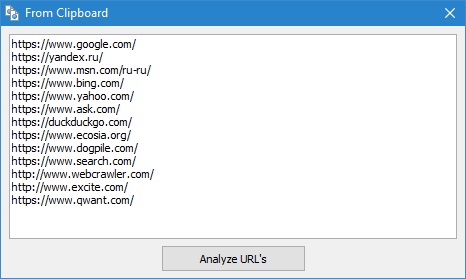
- З файла на дыску. Дадзены варыянт зручны, калі спіс URL для праверкі знаходзіцца на цвёрдым дыску ў тэкставым файле альбо ў файле Sitemap (*.txt і *.xml фарматы). У гэтым выпадку імпарт URL з дадзенага тыпу файлаў аналагічны імпарту з буфера абмену за тым толькі выключэннем, што пасля адкрыцця файлаў адбываецца іх парсінга на прадмет пошуку ў іх URL, а затым паўтараецца працэдура дадання знойдзеных URL у форму і наступнае іх сканіраванне праграмай SiteAnalyzer.
- Заўвага: пры імпарце Sitemap.xml з жорсткага дыска адбываецца яго аналіз на прадмет, ці з'яўляецца ён індэксным, і калі гэта так, то ў форме адлюстроўваецца спіс ўнутраных XML файлаў, змесціва якіх будзе запампавана і дададзена ў праграму. Пры імпарце тэкставых файлаў, якія змяшчаюць спісы URL, адбываецца простае даданне іх змесціва ў форму для адпраўкі URL на наступнае сканаванне.
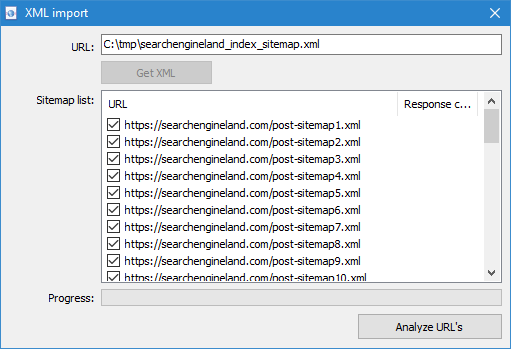
Дададзеная магчымасць сканавання файлаў Sitemap.xml (класічны Sitemap небудзь індэксны са спісам XML-файлаў).
- Сканаванне Sitemap.xml напрамую з сайта даступна праз пункт меню "Імпарт URL" -> "Спампаваць Sitemap". У якое з'явілася акне неабходна пазначыць URL для запампоўкі і разбору змесціва Sitemap.xml. Пасля націску на кнопку "Імпартаваць" праграма правядзе аналіз змесціва файла на прадмет таго, ці з'яўляецца дадзены сайтмап індэксным ці гэта звычайны Sitemap.xml са спісам URL сайта.
- Класічны Sitemap.xml. Калі гэта апынуўся класічны Sitemap.xml, то далей праграма спарсит ўсе яго URL і пасля націску кнопкі ОК дадасць іх у праграму і пачне іх сканаванне.
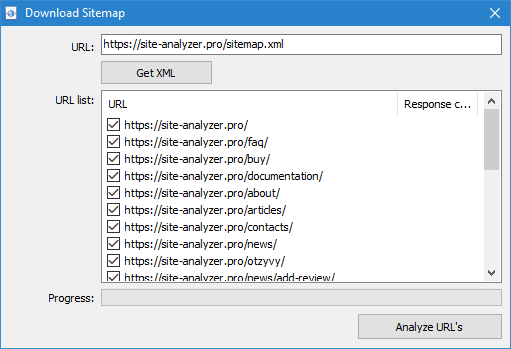
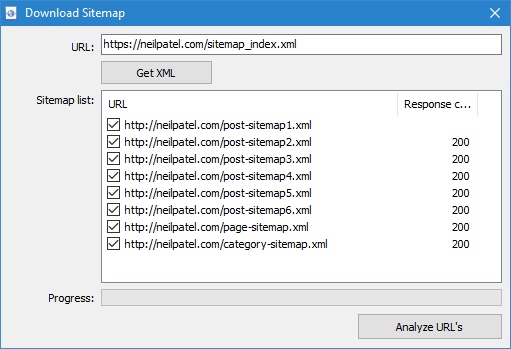
- Індэксны Sitemap.xml. У выпадку, калі Sitemap.xml апынецца індэксным файлам, то ў гэтым жа акне праграма адлюструе списк яго ўнутраных *.xml файлаў, а таксама код адказу кожнага з іх. З дапамогай чекбоксов можна выбраць тыя файлы, змесціва якіх плануецца прасканаваць. Пасля націску кнопкі ОК змесціва дадзеных XML-файлаў будзе таксама дададзена ў праграму і пачнецца іх сканаванне.
Заўвагі:
- Пры імпарце URL адбываецца аўтаматычная валідацыю спасылак на карэктнасць. Калі радок не з'яўляецца URL, то яна не будзе дададзеная ў чаргу сканавання.
- Скануюцца толькі тыя URL, якія былі адпраўленыя на праверку, і толькі яны. Такім чынам, пры парсинге URL сканер не пераходзіць па спасылках і не дадае іх у спіс сканавання, як пры сканаванні паўнавартасных сайтаў. Колькі URL было імпартавана на ўваходзе - столькі і будзе просканировано на выхадзе. Гэтая асаблівасць тычыцца ўсіх тыпаў сканавання адвольных URL.
- Пры сканаванні адвольных URL сам "праект" не захоўваецца ў праграме і дадзеныя па яго не дадаецца ў базу. Таксама не даступныя раздзелы "Структура сайта" і "Дашборд".
Іншыя змены
- Дададзеная магчымасць выдзялення і капіявання ў буфер абмену значэнняў вочак па Ctrl+A.
- Паскорана аперацыя выдалення праектаў (для поўнага выдалення праектаў неабходна рабіць сціск базы праз меню праграмы).
- Выпраўленая праблема з не заўсёды карэктным падлікам пустых тэгаў H1.
- Выпраўленая праблема з не заўсёды карэктным парсингом атрыбуту «title» у малюнкаў.
- Выпраўлена завісанне праграмы пры перамяшчэнні па запісах падчас сканавання.
Мы не спыняемся на дасягнутым і ўжо рыхтуем для вас новую фішку, якую плануем выпусціць у бліжэйшы час.
Сачыце за абнаўленнямі! :-)
Ацэніце артыкул
4.5/5
1


















